

4K游戏无忧!NVIDIA GTX980Ti首发评测
1965年时任仙童半导体公司研究开发实验室主任的摩尔绘制数据时,发现了一个惊人的趋势:每个新芯片大体上包含其前任两倍的容量,每个芯片的产生都是在前一个芯片产生后的18-24个月内。只要“光刻”的精度不断提高,元器件的密度也会相应提高,从而计算能力相对于时间周期将呈指数式的上升。摩尔定律虽然算不上什么物理定律,但在显卡行业却一直延续着它的神话。即使是在28mn工艺停滞数年之后,显卡的计算能力依然在不断翻番。

今天NVIDIA再度发布了年度重磅产品——GeForce GTX980Ti,它的问世让高端游戏玩家多了一个选择!

目前GeForce GTX980Ti无疑是世界上性能最强的单芯显卡之一,NV最新的Maxwell架构优异GPU——GM200,核心集成的晶体量比双芯显卡GTX Titan Z还要多出了10亿,单卡显存容量6GB,这让我们对它的游戏性能异常期待,或许GTX TITAN X更多的任务是并行计算,而GTX 980Ti才是高端游戏玩家的非常好的选择!
文章开头我们已经提到过,GeForceGTX980Ti仍是一款采用NVIDIA Maxwell架构GPU的产品,从某种层面上来说,这意味着GM200只是GM107的衍生品而已。不过话说回来,在第二代Maxwell架构GPU到来之后,NVIDIA的GPU架构师再次在能效比利用方面突破了难关。下面,我们就进入GeForce GTX GTX980Ti的核心架构解析部分,帮助大家全面了解Maxwell架构的优异GPU产品——GM200。

Maxwell SM框图
自Maxwell架构GPU问世之后,它的全新设计可大幅提高每瓦特性能和每单位面积的性能。虽然Kepler SMX设计在这一代产品中已经相当高效,但随着它的发展,NVIDIA的GPU架构师再次在能效比利用方面突破了难关。它在控制逻辑分区、负荷均衡、时钟门控粒度、编译器调度、每时钟周期发出指令条数等方面的改进以及其它诸多增强之处让Maxwell SM(亦称“SMM”)能够在效率上远超Kepler SMX。
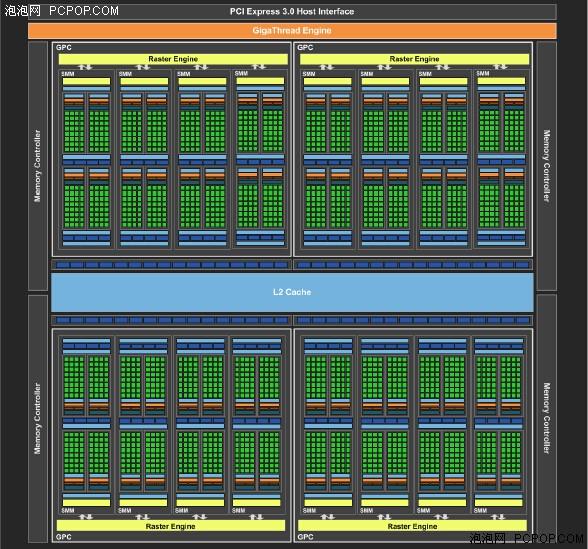
GM204核心逻辑架构图
我们知道,GM204拥有4组GPC、16个Maxwell流式多处理器(SMM)以及4个64bit显存控制器,并随之搭配了曾经前所未有的2MB L2。而搭载GM204核心的GTX 980显卡在性能以及能耗比方面的卓越表现各位也有目共睹。但是GM204可不是Maxwell架构GPU中的最强、最完整的核心,GM200核心才是。

从上面这张GM200核心逻辑架构图中我们可以看到,GM200核心在规格上要比GTX 980的GM204强大许多,拥有包含6组GPC、24个Maxwell流式多处理器(SMM)以及6个64bit显存控制器(共计384bit)。而且,与之相搭配的L2容量也增加到了3MB,比之前的任何GPU设计都大,十分有效地降低了显存带宽需求,确保了DRAM带宽不成为瓶颈。
GM200核心共计拥有3072个CUDA、192个TMUs、96个ROPs以及3MB L2,显存位宽也达到了384bit,这样的规格使GM200毫无疑问的成为了NVIDIA旗下有史以来规格最为强大的桌面级GPU。GeForce GTX GTX980Ti屏蔽了部分流处理器。下面,我们就一起来看一看GeForce GTX GTX980Ti与AMD、NIVIDIA这两家的旗舰、次旗舰显卡规格对比表格。
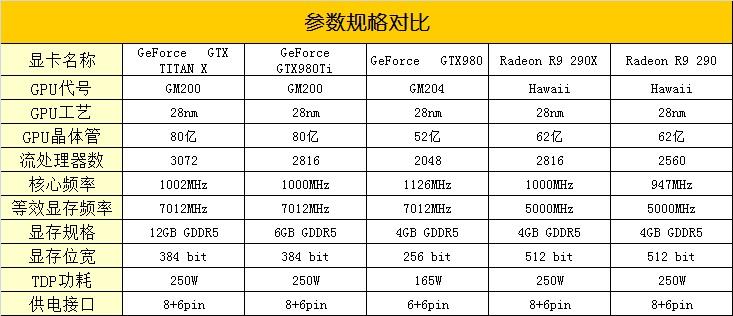
可以看到,相比GTX TITAN X,GeForce GTX980Ti在规格上虽然有所删减,但依然相当强悍,而且和GTX TITAN X一样,GeForce GTX980Ti的功耗控制的依然很出色,其官方提供的250W TDP只比GTX 980高了85W,而与AMD的旗舰显卡R9 290X相比则处于同一水平线上。这自然是由两点因素决定的,一是相当成熟的台积电28nm工艺,另一个就是优秀的Maxwell架构。
有人说NVIDIA最大的竞争对手就是过去的自己,这句话听着像是N次元平行世界的科幻,但笔者深以为然。事实上NVIDIA中国区高管最近频频表示在硬件层面上拿到卡皇宝座已经司空见惯,而他们更加为软件层面取得的成就引以为傲,DSR、G-SYNC、VR技术等等才是让游戏体验提升的关键技术!
虚拟现实(VR)是当今游戏业界中的热门话题,自从电影《The Lawnmower Man》(《割草者》) 上映之后之后,首次现身的虚拟现实 (VR) 名声大噪。当时的虚拟现实不但图形效果糟糕、游戏体验肤浅,而且运动追踪技术也处在萌芽阶段,因此导致动作迟滞,这无疑会使观看者感到恶心。
随着科学技术的日益进步,相对以往来说目前我们已经更深入地了解了人脑,这就允许我们更好地打造出可最大限度减少恶心症状的虚拟现实体验,而技术上的改进则能够提供照片般逼真的图形效果,带来真正令人身临其境的游戏体验。从超强的GPU到高密度显示器,虚拟现实现已得到充分发展,变成了一种让人乐此不疲的卓越体验,哪怕是热情洋溢的描述也不足以刻画出它的风貌。

早在几年前,NVIDIA一直与Oculus等公司密切合作以改善虚拟现实体验。很快NVIDIA就发现,最大限度减少游戏动作与屏幕显示之间的延迟,这对临场感和避免恶心症状来说至关重要。
为此,NVIDIA开发了多项新技术,这些技术可大幅改善虚拟现实体验,使基于Maxwell架构GPU的显卡最擅长提供流畅而有趣的虚拟现实体验。
一、直接输出“VR”专用图像

其次,VR设备都拥有一个镜头组在放大显示屏上面的内容,这样就可以让几英寸的显示屏拥有影院巨幕的观看效果,然后这么高倍放大的镜头组必然会产生鱼眼效果,所以在VR设备里的显示屏上实际显示的画面是经过压缩调整的,抵消掉镜头组产生的畸变,让我们看到正常的画面。

这种“调整”使得VR设备实际需要显示的图像面积比正常渲染出来的要小的多,如果是显卡算出正常的画面然后再压缩,不仅多了一道工序,而且浪费了很多资源在无用的像素渲染上面。俄日了让VR设备的效率达到最优,NVIDIA显卡在检测到VR设备连接后,会自动直接渲染出右面Warped Image,既减少了工序,又节约了资源,让N卡对VR设备的支持效率大大提升。
二、预渲染帧数调整减小延迟
从输入 (当你移动头部) 到输出 (当你看到游戏中出现动作) 的标准虚拟现实流水线大约耗时 57 毫秒 (ms)。然而,要获得良好的虚拟现实体验,这一延迟时间应该低于 20ms。目前,绝大部分延迟时间是 GPU 渲染场景所花费的时间以及将场景显示在头盔显示器上所花费的时间 (大约 26ms)。

为了降低这一延迟,NVIDIA把预先渲染的帧数量从 4 帧减少到 1 帧,从而最多缩短了 33ms 的延迟,而且NVIDIA开发的 Asynchronous Warp 已接近完工。Asynchronous Warp 是一种可大幅改善头部追踪延迟的技术,能够确保玩家察觉不到头部晃动与画面渲染之间的延迟。
这两者相结合,再加上 NVIDIA 开发者的进一步调整,这一虚拟现实流水线现在的延迟只有 25ms。随着进一步工作的开展和更新技术的问世,我们预计消费版本的虚拟现实将会拥有更快的响应速度。
三、双卡协同工作,一卡负责一屏幕
虚拟现实的另一项要求是高帧速率。目前,想要实现流畅的游戏体验,每只眼睛的帧速率需要在 960x1080 分辨率下达到每秒 75 帧才行,实现这种水平的性能相当于 4K 渲染,因此性能最强的旗舰级N卡自然是必不可少的。
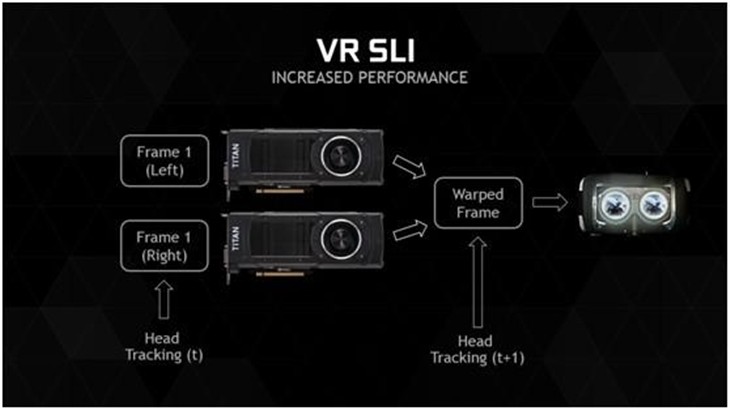
为了给虚拟现实游戏玩家带来更为出色的体验,NVIDIA还专门开发了VR SLI技术,它可以让每一路GPU只负责虚拟现实头戴显示器的一只眼睛画面,让游戏可充分利用两颗GPU,提升帧率。
速度与画质一直都是3D游戏追求的两大终极目标,但很多时候,速度与画质总是鱼和熊掌不可兼得,想要开启高级特效必然会损失帧数导致流畅度下降,因此就需要硬件厂商不断的研发出性能更强的GPU,也需要软件厂商研发出更高效率的图形技术。
抗锯齿(Anti-Aliasing,简写为AA)就是这样一项很特别的图形技术,它能够明显的改善游戏画面表现力,同时也会让游戏帧数大幅下降。所以多年以来,不论是显卡厂商还是游戏开发商,都在努力的改进抗锯齿效率,开发出新的抗锯齿模式,让游戏画质变得更好,同时也不至于让性能损失太多。
所以,大家一定听过或者见过以下这些抗锯齿中的一种甚至多种,如:MSAA、CSAA、CFAA、FXAA、TSAA……今天笔者就为大家详细解读3D游戏中的锯齿是如何产生的,回顾最常见的MSAA技术的原理和优缺点,最后介绍NVIDIA新开发的一种效率极高的抗锯齿技术——MFAA。
● 为什么会产生锯齿?

我们知道,显示屏是由一个个方块像素点组成的,这些方块像素点在显示斜向或圆形物体时,会不可避免的在边缘产生锯齿状的线条。就像马赛克一样,只不过是薄码而已……
● 高分屏能否自动消除锯齿?

当显示器的分辨率或显示屏的PPI(每英寸的像素数)足够大时,人眼将无法看清具体的像素点,但相邻像素之间的色彩差异也会产生明显的错落感,高分辨率/PPI由于像素变得非常细腻,可以同比缩小锯齿,但仍不能完全消除锯齿。
● 抗锯齿技术是如何抵抗锯齿的?
前面说过,方块像素显示斜向或圆形物体时,锯齿是无可避免的,抗锯齿也无法消除锯齿,但它能通过欺骗人眼的方法,让锯齿的棱角显得不那么明显:
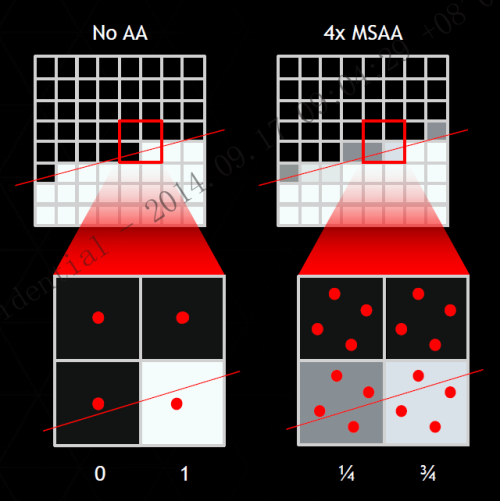
如上图所示,方法就是对锯齿所在位置的像素及相邻像素进行比对采样处理,计算出该像素应该显示多少比例的灰阶值,而不是“非黑即白”的显示模式。比如4xAA就是对每个像素采样4次,原本该像素只有0、1两种显示模式,开启4xAA后就能显示0、1/4、1/2、3/4、1五种模式。
如此一来,棱角分明的锯齿边缘,就会显得比较模糊,色彩过渡比较自然,就不会那么刺眼了,锯齿一定程度上被消除了。
● MSAA占据主导位置,4xMSAA使用最广泛
MSAA的全称是Multi Sampling Anti-Aliasing,多重采样抗锯齿。MSAA只对Z缓存和模板缓存中的数据进行采样处理,可以简单理解为只对多边形的边缘进行抗锯齿处理,而忽略非边缘像素(因此可能会在一些特殊位置残留一些锯齿)。这样的话,相比SSAA对画面中所有数据进行处理,MSAA对资源的消耗需求大大减弱,因此MSAA在游戏中使用最广泛,多年来一直占据主导位置。

通常在游戏中会提供2x、4x、8x三种抗锯齿级别,一般最常用的就是4x这种模式,因为4x和8x的画质差别已经很小了。
● 开启抗锯齿性能损失有多大?
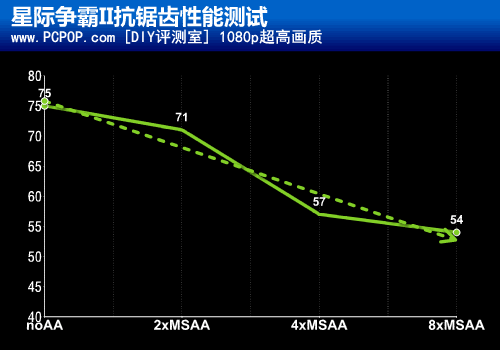
可以看出,4x抗锯齿虽然效果优秀,但性能损失比较大,而2x性能损失最小,可以说效率最高。
● NVIDIA的黑科技:超高效能的MFAA
鉴于高倍MSAA性能损失较大的问题,NVIDIA在MSAA的基础上开发出了一种“投机取巧”的技术:Multi-Frame Sampled Anti-Aliasing(MFAA),从字面上来看它是MSAA的一个变种,可以翻译为“多帧多重采样抗锯齿”。
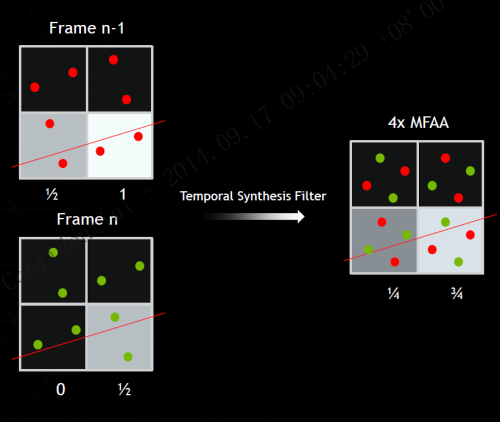
上图为MFAA的工作原理,奇数帧在水平方向进行一次2xMSAA采样,偶数帧在垂直方向进行另外一次2xMSAA采样,然后通过软件算法将其合成,最终的采样结果与直接进行4xMSAA没有区别。
可能会有人担心,对相邻的两帧进行两次2xMSAA采样合成会不会造成画质损失,尤其是当画面运动幅度较大时?其实MFAA都是对物体边缘进行采样,无论运动幅度多大都有固定的几何轨迹,因此两帧始终会在固定的像素点进行合成,不会产生错乱,合成之后的采样效果自然也不会与MSAA有啥区别。
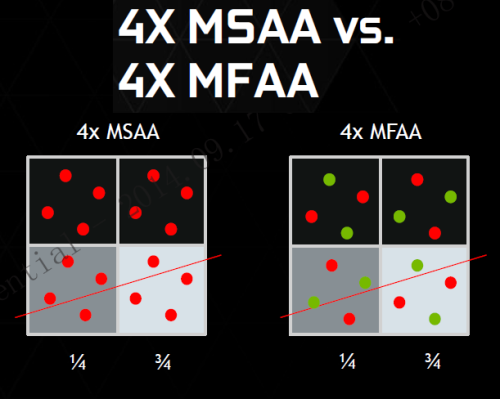
● 4xMSAA的画质与4xMFAA完全相同,4xMSAA的性能接近与2xMSAA

4xMFAA的画质与4xMSAA没有区别
当然,通过算法将两次2xMSAA合成为4xMFAA,性能肯定会有损失的,NVIDIA官方称性能损失会在5%以内,这样4xMFAA的性能自然会远超4xMSAA,只是略低于2xMSAA。同理可以实现8xMFAA的性能远超8xMSAA,略低于4xMSAA。
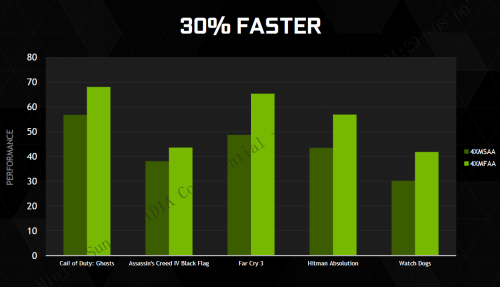
4xMFAA的帧数比4xMSAA高30%
通过这样一个简单而有创意的技术,可以免费让NVIDIA显卡的抗锯齿性能提高30%,简直逆天了!
NVIDIA新开发的高效能抗锯齿技术——MFAA,它能够以2xMSAA的性能,提供4xMSAA的画质,从而以较小的性能损失提供更完美的游戏画质。这样当玩家们玩类似《显卡危机3》、《男朋友4》这样的优异大作,由于FPS本身较低不敢开高倍AA时,就可以开启MFAA技术,让速度与画质兼得。
但并不是所有的游戏都像显卡危机一样吃显卡,绝大多数游戏对显卡要求不是很高,比如《穿越火线》、《英雄联盟》一类的游戏中端显卡就能动辄跑100FPS以上,此时显卡性能有些浪费,那有没有通过牺牲一部分FPS来提高画质的方法呢?现在笔者就为大家介绍NVIDIA的另外一项黑科技——Dynamic Super Resolution(DSR),动态超级分辨率

简单来说,DSR技术可以在普通的1080p显示器上显示4K级别的游戏画面,当然NVIDIA即便掌握了火星科技也不可能将1080p显示器变成4K显示器,该技术只是在后台以4K分辨率渲染游戏画面,通过动态缩放的方式显示在1080p显示器上,虽然实际分辨率依然是1080p,但游戏画面却要比原生1080p分辨率渲染出来的好很多。
首先我们来看一张开启DSR前后的游戏画面截图:
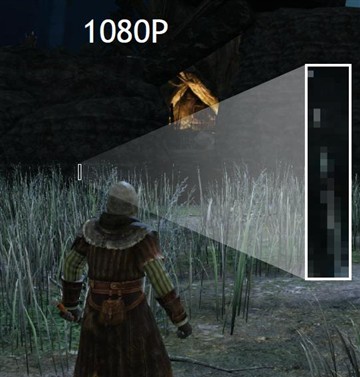

可以看出,开启DSR之后的草丛边缘显示效果要好,然后再通过显卡渲染流程为大家分析出现差异的原因:

可以看到,DSR模式在GPU内部是以真4K分辨率进行渲染的,只不过在像素输出阶段将4个像素合成为1个像素,最后才以1080p分辨率输出。4K的分辨率是1080p的4倍,渲染精度自然大幅提高,输出像素的采样率相当于是4倍,最终的画面自然会更加柔和平滑一些。
看到这里的示意图,相信资历较老的玩家会发现DSR技术有些类似于最早期的SSAA(超级采样抗锯齿),就拿前面的示例图来说,原理可以说是完全相同的,但区别是SSAA只针对几何物体的边缘,而DSR则是针对全屏所有像素进行二次采样,毕竟内部就是以4K分辨率进行渲染的。

点击查看大图可以看到开启DSR的明显区别
DSR对游戏有要求吗?
DSR技术的工作模式非常简单,它在系统内部模拟出了4K分辨率的显示器,游戏就会以为电脑拥有一台4K显示器,从而以4K模式渲染出高精度的画面,最后GPU再重新采样并缩放成1080p分辨率输出,因此DSR技术的唯一要求就是游戏本身能够支持4K分辨率。
如何开启DSR技术?

DSR技术支持几乎所有的PC 3D游戏,玩家可以在最新版的343驱动控制面板中开启,或者使用GeForce Experience自动扫描并优化游戏,如果您的显卡较好,那么像暗黑3这样要求不是很高的游戏默认就会开启DSR技术。
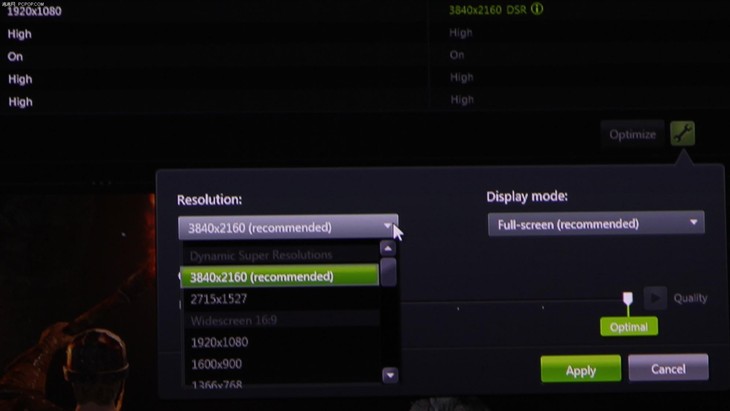
DSR除了4K模式,还支持自定义分辨率,如2K模式:
当然,如果显卡性能还不够强的话,DSR技术允许玩家进行自定义设置,将渲染模式从4K降为2K,以2K模式渲染出来的画质缩放成1080p分辨率输出后,画质依然会有明显提升,同时性能损失不至于太大。
每一个行业都有自己的“圣杯”,例如能源方面的核聚变、医药方面的癌症特效药以及空间探索方面的超光速推进力。 任何领域中“圣杯”的定义都是难以实现和代价高昂的,或者完全是科幻产物。也许这就是我们之所以对此心驰神往的原因所在。
计算机图形领域的“圣杯”就是“实时全局光照”。全局光照是一种渲染游戏环境的方法,它通过模拟光线的行为,从而体现各个表面之间的光线反射效果。然而以光子级别进行自然仿真处理是一项代价高昂的事业,电影中仅仅是有选择地利用全局光照来渲染复杂的CG场景,就是因为这个原因。
这一情况即将有所改变。凭借次世代Unreal Engine 4(虚幻4)引擎,游戏将首次具备实时全局光照渲染效果。而这项技术是由NVIDIA图形工程师与EPIC开发者共同完成的,NVIDIA将其称为Voxel Global Illumination(VXGI,立体像素全局光照)。
● 什么是全局光照?它为什么对游戏逼真度来说如此重要?
首先来看一组对比截图:

传统直接光照效果

全局光照效果
区别很明显吧?通俗的讲,直接光照就是简单的模拟一个或多个光源的照射效果,在相应的位置投射出光和影;而全局光照就是考虑到了光线的直射与尽可能多的漫反射效果,最终呈现出来的光影效果更接近于现实世界。
全局光照指的是对场景周围光线反射的计算。全局光照负责制作出现实环境中的许多细微着色特效、气氛以及有光泽的金属反射效果。自1995年在虚幻1中采用实时直接光照以来,虚幻4引擎中的实时全局光照是在光照方面实现的最大突破!
● 在没有全局光照技术之前,游戏是如何实现更逼真光影效果的?
也许有人会说了,现有的游戏其实光影效果还是不错的,并不像上图1所示那么差。没错,上图的对比是比较直接的、没有附加特效的,其实游戏中还有其它的方法来提高画面真实度,最常见的就是Ambient Occlusion(AO,环境光遮蔽)技术。

目前非常先进的水平环境光遮蔽技术 (Horizon Based Ambient Occlusion,HBAO)
但不管是什么级别的AO,都是对光照与阴影的一种模拟,可以说是预处理,开发者认为此处的阴影的颜色应该深一些、或者浅一些、或者柔和一些,所以才会加上去的,而不是通过复杂的光影算法来直接生成的。
● 喜欢浓妆艳抹还是清新素雅?
我们知道传统的图形渲染分为立体建模(顶点着色)和像素着色两个部分,其中像素都是2D平面状的,平铺在模型表面,而光影效果都是需要预先计算每个像素的光照或阴影,就是根据游戏的需要来改变像素颜色。
这种对每个像素反复进行涂抹修饰的做法,既不逼真、也很低效,因为像素显示的并不是真正的光影效果,而是我们认为应该显示的效果,而且越来越多的预处理特效对GPU的ROP(光栅单元)和显存造成了很大的负担。
● VXGI立体像素全局光照:2D平面像素变为3D立体像素
NVIDIA使用了一种非常巧妙的方法,从根本上改变了虚假的光影处理流程。

传统游戏中,所有间接光照(某一表面反射出来的光线)是预先计算的,存储于有光线贴图之称的纹理内。光线贴图让游戏场景能够具备类似全局光照的效果,但是因为它们是预先计算的,所以只在静态物体上有效。
VXGI完全抛弃了将光线贴图存储于2D纹理中的做法,而是将其存储于立体像素中。立体像素就是三维像素,它具有体积,类似于乐高积木。
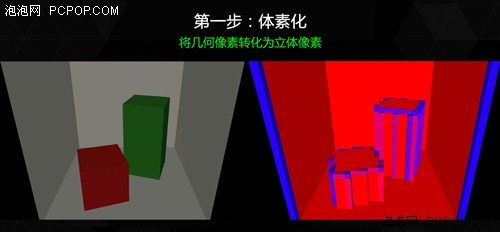
立体像素采用树状结构分布,以便能够对其进行高效地定位。当渲染一个像素时,它能够有效地询问立体像素树: “哪一个立体像素对我来说是可见的?”根据这一信息,就能够决定接收的间接光线数量(全局光照)。

VXGI完全消除了预先计算的光照,以存储于树状结构的立体像素取而代之,这种树会根据每一帧而更新,所有像素均利用它来收集光照信息。
● VXGI立体像素全局光照:每颗立体像素都是“手电筒”
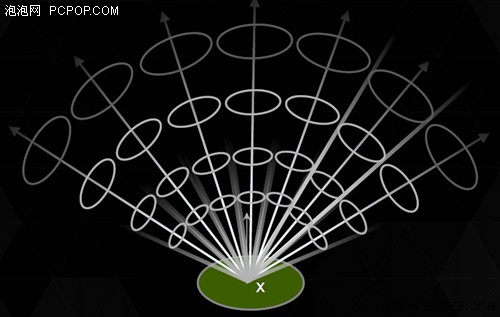
现在到了最关键的地方,立体像素看起来好像比马赛克更加稀疏,但是所有可见的立体像素都可以执行锥形聚焦光线追踪(给出起点、方向和角度),这样就能沿着小范围的锥形路径生成大致的光线漫反射效果。
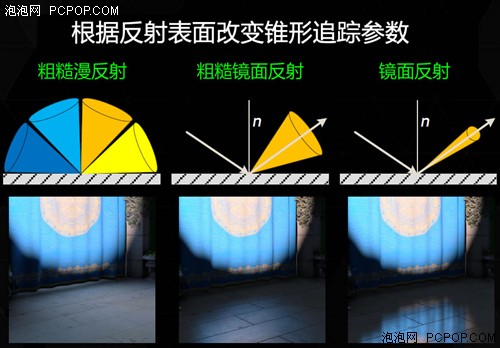
每一个立体像素都可以进行多个锥形追踪,游戏中需要根据实际光源的大致方向及反射表面的情况,来设定锥形范围及追踪数量。

实现最终的效果没有捷径,就是通过GPU强大的运算能力,让锥形追踪足够快,以使我们能够实时地对每个立体像素执行一次或多次追踪。对每个像素执行六次宽幅锥形追踪 (每个主要方向各一次) 会生成大致的二次反射间接光照效果。以镜面反射方向执行窄幅锥形追踪能够呈现金属反射效果,在这种反射效果中,每个有光泽的表面都能够反射出整个场景。
● 虚幻4引擎完美支持VXGI,Maxwell显卡运行效率更高
值得一提的是,VXGI提算全局光照技术严重依赖于GPU的浮点运算(通用计算),而不是传统的图形流水线,因此大大减轻了GPU光栅单元的负担。另外,NVIDIA称Maxwell架构对VXGI的运算进行了针对性的优化,新一代显卡在执行体素全局光照时的效率会更高。

VXGI现已加入UE4豪华DEMO
虚幻4引擎已经完整支持了VXGI技术,最新的虚幻4技术演示Demo已呈现出了非常惊人的光照效果,不久之后,将会有一大批使用虚幻4引擎的游戏大作问世,届时Maxwell架构的显卡将会有更佳的性能表现。
效果开高游戏帧数下降,特效开低画质惨不忍睹,如何平衡是一件令游戏玩家头疼不已的事。一般测试的时候我们都是将设置手动调整到最高,目的是压榨显卡的全部性能。但实际游戏的时候,根据显卡的性能和游戏的需要,我们并不需要这么做,而在画面质量和游戏速度两者之间达到非常好的平衡才是我们需要的结果,为了解决这个问题,NVIDIA发布了GeForce Experience——一款智能设置游戏参数的软件。
这款软件在NVIDIA官网提供下载,安装之后第一次运行,GeForce Experience会从NVIDIA的云端下载用户所需的游戏设置。
▲ 通过云端硬件和游戏的数据匹配交换,GeForce Experience可以优化系统。
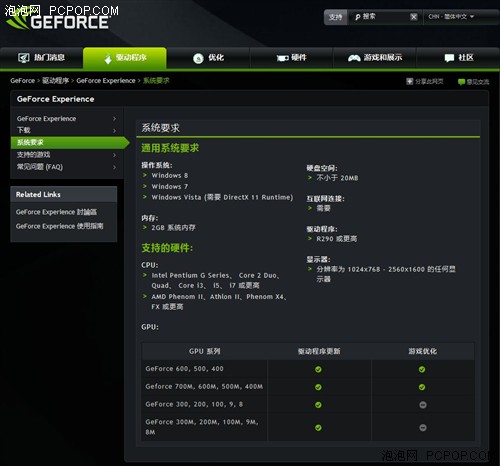
▲ GeForce Experience的系统要求,支援主流硬件和系统
GeForce Experience支持手动调整游戏设置,也支持一键智能优化,云端会根据用户的电脑硬件配置和游戏的要求设置特效的高低,保证所有GeForce用户非常好的的游戏体验。
电视机首次被开发出来时依赖的是阴极射线管 (CRT),阴极射线管通过在磷管表面上扫描电子束来工作。这些电子束造成管上的某个像素发光,当以足够快的速度激活足够多的像素时,CRT 就会呈现出全活动视频的效果。这些早期的电视具备 60Hz 刷新率主要是因为美国电网是 60Hz 交流电。将电视刷新率与电网相匹配,这让早期的电子产品开发起来更加容易,而且也减少了屏幕上的电源干扰。

到了上世纪八十年代早期 PC 上市之时,CRT 电视技术已经十分普遍,同时在打造计算机专用显示器方面也是最简单、最具性价比的技术。 60Hz 与固定刷新率成为了标准,系统制造商学会了如何在不大完美的情形下物尽其用。在过去的三十年里,即便显示器技术从已经从 CRT 发展到了 LCD 和 LED,但是尚无大公司挑战过这一想法,因此使 GPU 与显示器刷新率同步依然是当今整个行业的标准做法。
但问题是,显卡并不以固定的速度渲染。事实上,即便在单一游戏的单个场景中,显卡渲染的帧速率也会大幅变化,这种变化根据 GPU 的瞬时负荷而定。因此在刷新率固定的情况下,要如何将 GPU 图像搬到屏幕上呢? 第一个办法就是完全忽略显示器的刷新率,对中间周期扫描到显示器的图像进行更新。这种办法我们叫做「垂直同步关闭模式」,这也是大多数游戏玩家所使用的默认方式。缺点是,当单一刷新周期显示两幅图像时,在两幅图像交替时会出现非常明显“撕裂线”,这种情况通常被称作屏幕撕裂。

解决屏幕撕裂问题的老牌解决方案是打开垂直同步,强迫 GPU 延迟屏幕更新,直到显示器开始进入一个新的刷新周期为止。只要 GPU 帧速率低于显示器刷新率,这个办法就会导致卡顿现象。它还会增大延迟,导致输入延迟。输入延迟就是从按下按钮到屏幕上出现结果这段时间的延迟。
更糟糕的是,许多玩家在碰到持续的垂直同步卡顿现象时会导致眼睛疲劳,还有人会产生头痛和偏头痛症状。这些情况推动我们开发了自适应垂直同步技术,该技术是一种有效而备受赞誉的解决方案。尽管开发了这一技术,垂直同步的输入延迟问题现在依然存在,这是许多游戏发烧友所不能接受的,也是电子竞技职业玩家绝对不能容忍的。这些职业玩家会定制自己的 GPU、显示器、键盘以及鼠标以最大限度减少重新开始时的重大延迟问题。

传统的垂直同步就是让显卡输出的帧等液晶刷新。假设显卡渲染的帧比显示器更快,那就让渲染出来的这一帧放在显存里面等待下一个液晶刷新,这个周期里面即使游戏中的模型已经发生位移或者改变,最后显示器输出的依然是之前的图像。假设显示器刷新比显卡更快,那显示器会输出两帧同样的画面。

不开启G-SYNC的一边要么出现撕裂,要么出现卡顿
往往这两种情况交错进行,我们看到的画面就会抖动,看到的游戏世界就会和真实情况有着一定程度的非正常延时。这就是为什么即使我们的显卡帧数跑到100FPS以上,我们依然感觉不是完全流畅的原因。

G-SYNC的出现让这种情况彻底改观,本质上说G-SYNC可以从根源上杜绝撕裂和卡顿,因为G-SYNC是在显示器中加入一个芯片,让显示器听从显卡的命令确定实时的刷新频率。简而言之就是显卡渲染出一帧,显示器就刷新一帧。这样做的好处是无论场景渲染变化如何大,显卡帧数如何波动,只要保持在一定的水平之上,我们看到的都是连贯平滑的图像。

很明显除了观赏体验上发生了巨大变化以外,当 G-SYNC 与高速的 GeForce GTX GPU 和低延迟输入设备搭配使用时,线上游戏的玩家还将获得重大的竞争优势。无论是业余爱好者还是专业电子竞技选手,NVIDIA G-SYNC对他们来说无疑是一次必不可少的升级。Unreal Engine 的架构师就称 G-SYNC技术为“自人类从标清走向高清以来游戏显示器领域最重大的飞跃”。
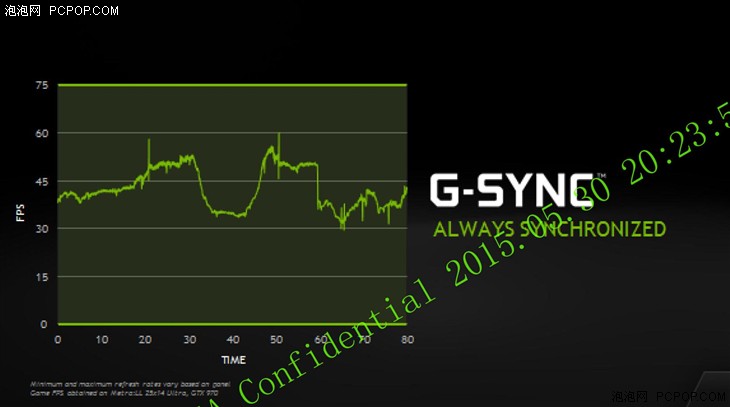
NVIDIA在发布会上再次披露了G-SYNC技术的最新进展,如果实际帧数低于一定数值,G-SYNC系统会将帧数翻倍或者X3,以确保显示器最终输出的画面不会因为间隔时间太长和发生明显的闪烁。
GeForce Experience 现已优化了支持上百款游戏,下载用户数量也早就超过了千万。而GeForce Experience(GFE软件)1.7之后的版本都加入了一个重大更新,那就是备受期待的Shadow Play。
Shadow Play是GFE中的一个简单易用的游戏录制模块,可充分利用 GeForce GTX 600 和 700 系列 GPU 中内置的 H.264 编码器达到高效率录制游戏录像的功能。通过利用这一硬件编码器,ShadowPlay 对游戏帧速率的影响大大低于传统的录制应用程序,传统应用程序会给 CPU 造成巨大压力。由于帧速率更高,玩家可以享受到更加流畅的游戏体验,而通过以 H.264 格式进行编码,ShadowPlay 避免了其它应用程序中占用数 GB 空间的大文件问题。这样便节省了空间,更重要的是,通过避免不必要的硬盘颠簸,减少了卡顿现象。
ShadowPlay演示:
● Maxwell更加卓越的视频录制功能
与之前的GeForce GPU相比,Kepler主要的技术创新之一是其基于硬件的H.264视频编码器——NVENC。通过把用于视频编码/解码的专用硬件电路集成进来(而不是使用GeForce GPU的CUDA核心),NVENC在H.264编码方面可带来大幅性能提升,同时消耗的功耗更低。
去年Q3利用Kepler的NVENC编码器实现的Shadow Play功能在游戏玩家中获得了极大的成功。因为NVENC编码器在游戏的同时自动记录几分钟的场景,所以只要玩家需要的时候按一个热键,就可以将之前几分钟的画面保存成游戏录像。这让所有GeForce GTX 600和GTX 700系列游戏玩家都兴奋不已。自从Shadow Play发布以来,捕捉的视频数量已逾300万,游戏玩家将捕捉到的视频发布到YouTube上,还有的玩家甚至在Twitch上实时流式传输自己的游戏片段。
为了提高视频性能,Maxwell采用了改进的NVENC模块,该模块编码速度是H.264实时编码的6-8倍或者Kepler实时编码的4倍,解码速度更是提升了8-10倍。换句话说在新一代Maxwell架构的显卡上,游戏同时录像,几乎感觉不到系统性能的下降。
Maxwell还具备量身定制的全新GC5功率状态,特别是能够在视频播放等轻载型使用场合降低GPU的功耗。GC5是一种低功耗休眠状态,在这些使用场合下的节能性远超之前的GPU,这对于高端显卡的意义更大。
看到GeForce GTX980Ti的外观,有人会觉得熟悉,熟悉的原因无非是这个外观设计早在首款核弹显卡GTX Titan来临时就一直沿用至今。但是,笔者相信一部分人觉得这款显卡很熟悉的原因不止于此。



早在GeForce GTX Titan BE还身处传闻中时,一位名为@控的是AK的网友发帖晒出了一款经过氧化处理的“泰坦皮”,也就是“自制版”GeForce GTX Titan BE。正是这条帖子,给予了NVIDIA灵感,于是这个设计就出现在了GeForce GTX980Ti显卡上。

核心方面,GeForce GTX980Ti搭载了一颗基于28nm工艺 Maxwell架构GM200核心,拥有2816个流处理器、176个TMUs和96个ROPs,基础核心频率为1000MHz、基础Boost频率为1075MHz。

而在显存方面,GeForce GTX980Ti的PCB正面一共配备了12颗GDDR5显存颗粒,组成了6GB GDDR5 384bit的显存规格,而在显存频率方面,GeForce GTX980Ti的显存频率为7012MHz。



视频接口方面,GeForce GTX980Ti采用完整版本的三DP、HDMI、DVI 2.0的输出设计,虽然视频输出接口的排布有点不符合处女座同学的审美观,但这样的组合已经完全可以满足发烧玩家的需要。
映众(Inno3D) GTX980Ti Ultra冰龙超级版的外观可以说是霸气外露!拿在手里沉甸甸的份量十足!



这款映众(Inno3D)GTX980 Ultra冰龙超级版给我们的感觉只能说是相当恐怖!而最炫的还是外观!散热器上也设计了正面与侧面的LED呼吸灯,呼吸光拥有关闭、长亮、呼吸三个模式可调,可以满足玩家们的不同需求。此外,HerculeZ Air Boss自然也支持特色的易拆洗技术,隐藏式设计的六角螺丝刀可以帮助用户方便地对风扇叶进行拆洗保养。此外,全尺寸的金属背板当然也是必不可少的。



显卡采用NVIDIA 公版PCB方案,硬件规格方面,GTX980Ti Ultra冰龙超级版采用GM200核心,基于28nm工艺制程,内建2816个流处理器,采用PCIe 3.0 x16总线接口,配备6GB/384Bit GDDR5显存,支持DirectX 12、Shader Model 5.0、OpenGL 4.4以及NVIDIA GPU Boost 2.0等技术,同时显卡还支持3Way SLI以及多屏输出等功能。

供电部分,显卡采用了6+2相供电设计,铁素体电感,全固态电容以及多特MOS管等用料,显卡需要外接的8+6Pin供电。

与其他厂商喜欢沿用上一代的散热器不同,冰龙在每一代N卡上都会有专门的散热器设计,而HerculeZ X4 Air Boss则是Herculez系列的第四代产品了!

与以往的三风扇不同,这款HerculeZ Air Boss在配置方面有了颠覆性的改进,其特别针对供电部分设计了一个供电模块散热系统,散热片紧贴显卡的供电部分,通过一根8mm的热管,导向显卡顶端,通过设置在显卡顶上的第四个风扇将热量散出。



针对GPU部分,三风扇五热管依然是最有效的风冷方案!不过与上一代的Herculez X3 Ultra不同的是,全新的HerculeZ Air Boss对热管进行了升级,从5根6mm直径热管升级为2*8mm+3*6mm,进一步地提升了散热性能。同时针对此前Herculez散热器在快递运输过程中可能受压变形的问题,此次HerculeZ Air Boss也做了改进,除了在散热鳍片中加入了固定条外,同时还在背板上也对应设置了防撞金属模块。



接口方面比较特别,显卡采用是3个DP接口,以及一个HDMI接口,一个DVI接口的组合,总共有5个接口。可以轻松实现高分辨的三屏NVIDIA Surround或NVIDIA 3D Vision Surround输出。
为了避免在游戏测试中出现瓶颈,在本次测试中我们用Intel Core i7-5960X、华擎X99 主板、16GB DDR4-2666(8GB x 2)内存组建了一套高端平台,下方表格就是本次测试平台配置表格:
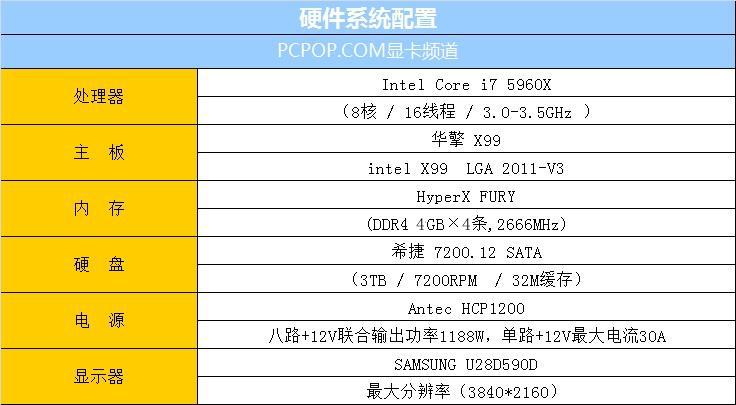
参测显卡方面,除了NVIDIA新显卡GeForce GTX 980Ti之外,我们在本篇评测中还选择了之前的GTX TITAN X和去年9月份发布的GTX 980以及AMD目前的单芯旗舰、次旗舰显卡Radeon R9 290X、Radeon R9 290。

HyperX骇客神条家族中的FURY针对中端用户而设计,自DDR3时代开始HyperX骇客神条系列就全新换装,作为HyperX Blu系列的替代者FURY主打三“高”:高性能、高性价比、高频率。内存颗粒采用SK Hynix,仅需1.2V电压,速度可达到2666MHz,ASRock X99主板好搭档。
测试内容与测试项目解析
从规格上看,我们可以毫无疑问的说GeForce GTX980Ti是一款专门为那些在4K分辨率下玩游戏的发烧友们所准备的优异单芯显卡。因此,在本篇评测中我们除了会在1920 x 1080、2560 x 1440这两个分辨率下进行测试外,还会着重进行显卡的4K性能测试。
另外,除了对GeForce GTX980Ti显卡进行功耗、温度以及噪音测试之外,我们还将会对这款显卡进行超频测试,来给大家展示GeForce GTX980Ti在超频之后的性能。
测试项目方面,基准性能测试3DMark 11、3DMark Fire Strike之外,我们还选择了多款热门游戏。在这些游戏项目中,既有《地铁2033》、《孤岛危机3》这类的老“显卡杀手”,也有《巫师3》、《刺客信条:大革命》、《GTA5》这样的热门新作。
3DMark11的测试重点是实时利用DX11 API更新和渲染复杂的游戏世界,通过六个不同测试环节得到一个综合评分,藉此评判一套PC系统的基准性能水平。


3DMark 11的特色与亮点:
1、原生支持DirectX 11:基于原生DX11引擎,全面使用DX11 API的所有新特性,包括曲面细分、计算着色器、多线程。
2、原生支持64bit,保留32bit:原生64位编译程序,独立的32位、64位可执行文件,并支持兼容模式。
3、新测试场景:总计六个测试场景,包括四个图形测试(其实是两个场景)、一个物理测试、一个综合测试,全面衡量GPU、CPU性能。
4、抛弃PhysX,使用Bullet物理引擎:抛弃封闭的NVIDIA PhysX而改用开源的Bullet专业物理库,支持碰撞检测、刚体、软体,根据ZLib授权协议而免费使用。
测试成绩展示:
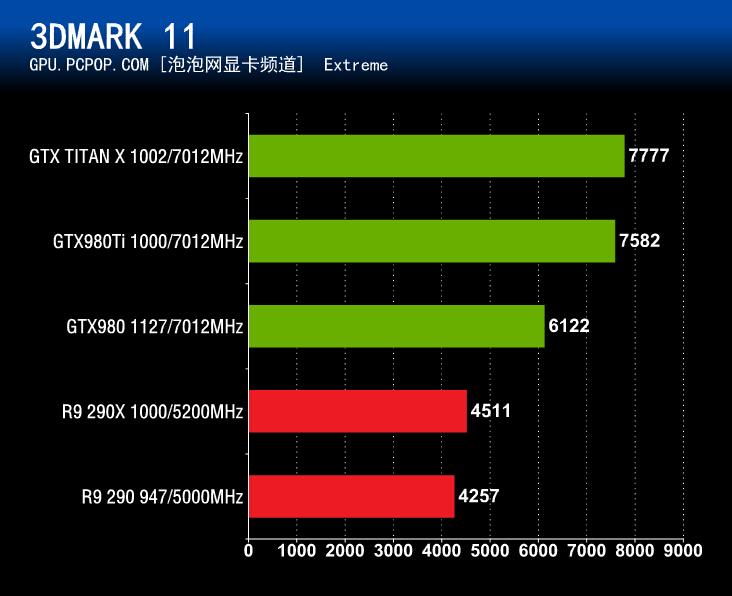
▲3DMark 11 Extreme测试项总得分(俗称的X分)
在3DMark 11性能测试中,我们可以看到规格最强大的GeForce GTX980Ti轻而易举的战胜了除了GTX TITAN X以外的其它几款A/N旗舰,而且领先幅度不小,与其它四款显卡中最优秀的GTX 980相比要高出大概四分之一。
既然针对平台不同,测试项目自然也相去甚远,三大平台除了PC追求极致性能外,笔记本和平板都受限于电池和移动因素,性能不是很高,因此之前的3Dmark11虽然有三档可选,依然不能准确衡量移动设备的真实性能。

而这次Futuremark为移动平台量身定做了专有测试方案,新一代3DMark三个场景的画面精细程度以及对配置的要求可谓天差地别。

Fire Strike、Cloud Gate、Ice Storm三大场景,他们分别对应当前最热门的三大类型的电脑——台式电脑、笔记本电脑和平板电脑。另外,在最新版的3DMark之中,我们还看到Fire Strike测试项多出了一个专为优异发烧主机准备的4K测试项目。
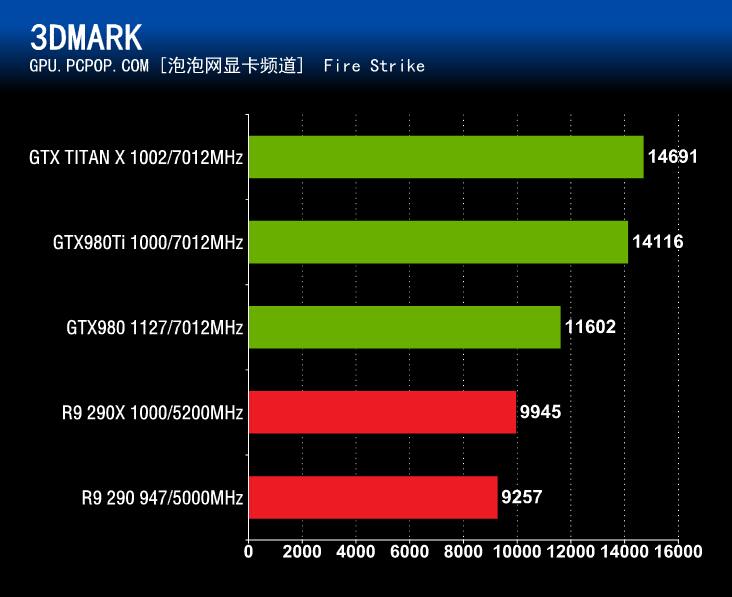
▲3DMark Fire Strike默认性能测试总得分
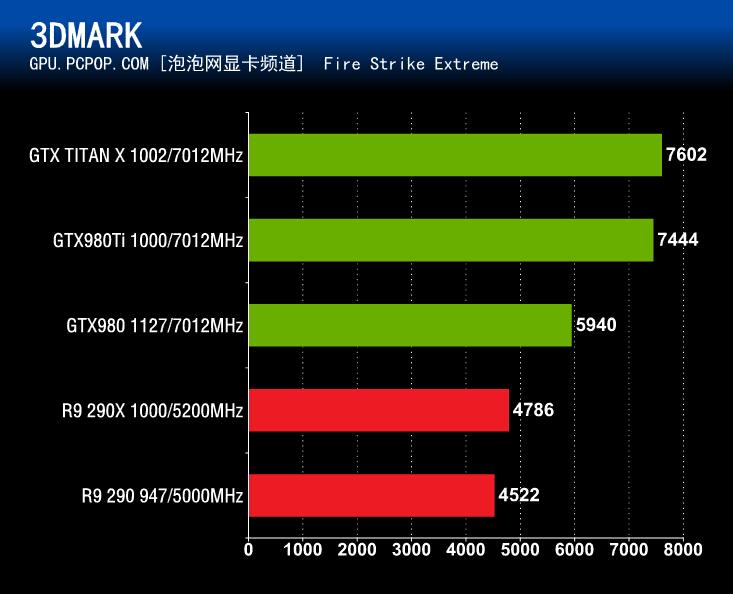
▲3DMark Fire Strike Extreme性能测试总得分

▲3DMark Fire Strike Ultra性能测试总得分
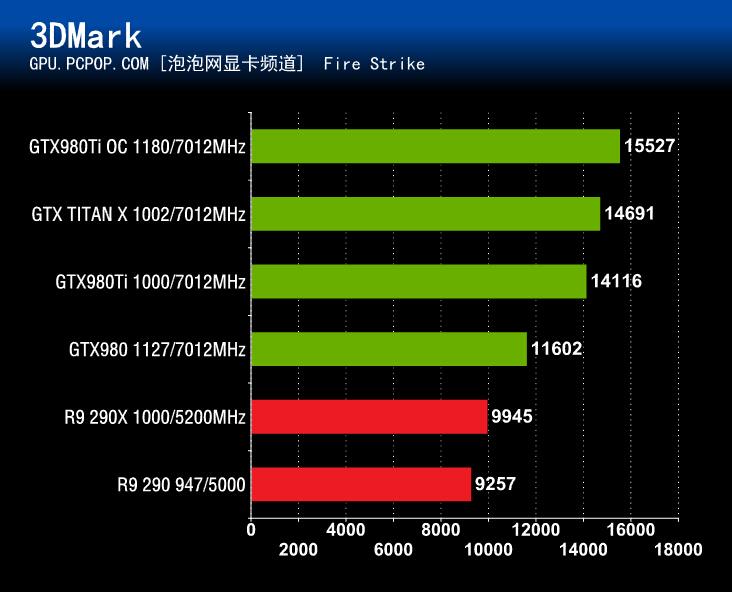
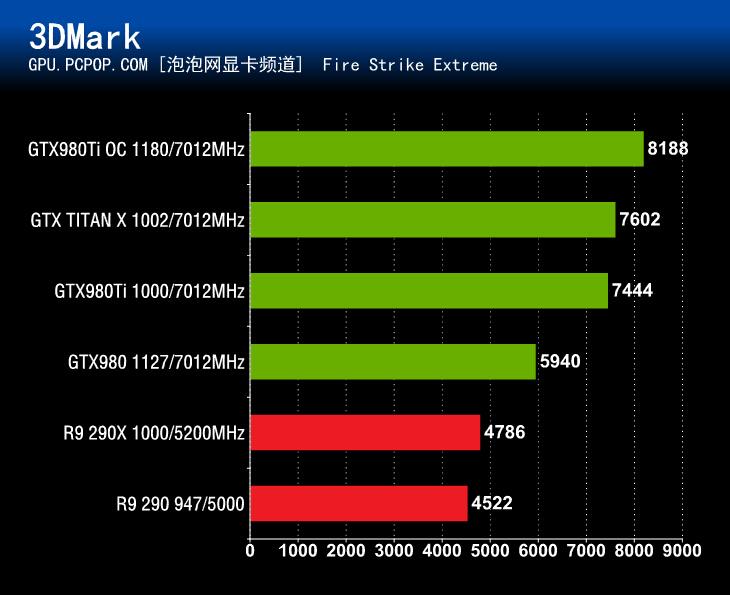
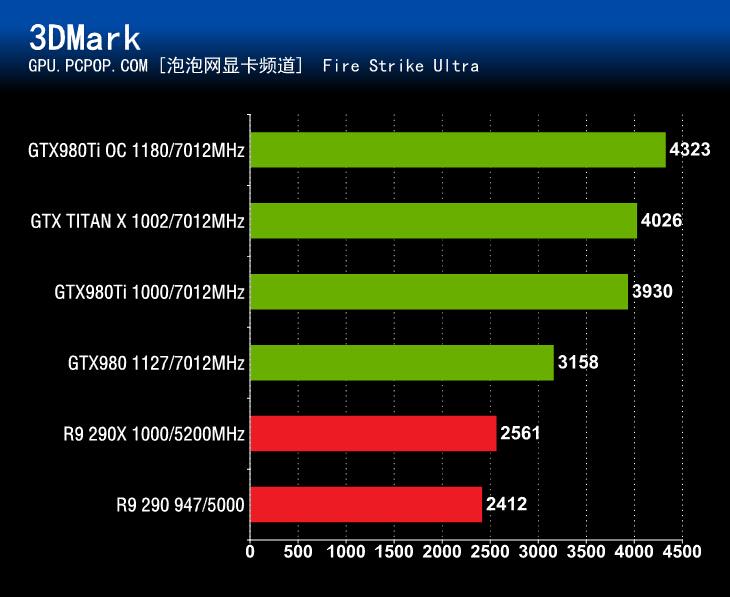
在3DMark Fire Strike性能测试中,GeForce GTX980Ti同样毫无悬念的碾压了其它3款参测显卡。无论是3DMark Fire Strike测试三种测试项的哪一种,GeForce GTX980Ti的成绩都仅次于采用完整GM200核心的GTX TITAN X。
基准性能测试小结:在3DMark 11和3DMark Fire Strike这两个基准性能测试中,GeForce GTX980Ti的表现非常不错,远远超过了除了TITAN X以外的其它3款产品。不过,这只是各位喜闻乐见的跑分测试结果,真正能体验出GeForce GTX980Ti性能的还得说是各种热门游戏的测试。下面,我们就进入本文的游戏性能测试环节。
《地铁2033》(Metro 2033)是俄罗斯工作室4A Games开发的一款新作,也是DX11游戏的新成员。

该游戏的核心引擎是号称自主全新研发的4A Engine,支持当今几乎所有画质技术,比如高分辨率纹理、GPU PhysX物理加速、硬件曲面细分、形态学抗锯齿(MLAA)、并行计算景深、屏幕环境光遮蔽(SSAO)、次表面散射、视差贴图、物体动态模糊等等。

《地铁2033》虽然支持PhysX,但对CPU软件加速支持的也很好,因此使用A卡玩游戏时并不会因PhysX效果而拖累性能。该游戏由于加入了太多的尖端技术导致要求非常BT,以至于我们都不敢开启抗锯齿进行测试,只是将游戏内置的效果调至最高。游戏自带Benchmark,这段画战斗场景并不是很宏大,但已经让高端显卡不堪重负了。
如果说是CRYSIS发动了DX10时代的显卡危机,那地铁2033无疑是DX11时代的显卡杀手!地铁2033几乎支持当时可以采用的所有新技术,在画面雕琢上大肆铺张,全然不顾显卡们的感受,和CRYSIS如出一辙。然而CRYSIS靠着特效的堆积和不错的优化,其惊艳绝伦的画面和DX9C游戏拉开了距离,终究赚足了眼球;而地铁则没有这么好运了,画面固然不差,BUG却是很多,招来了大量的非议。
测试成绩展示:
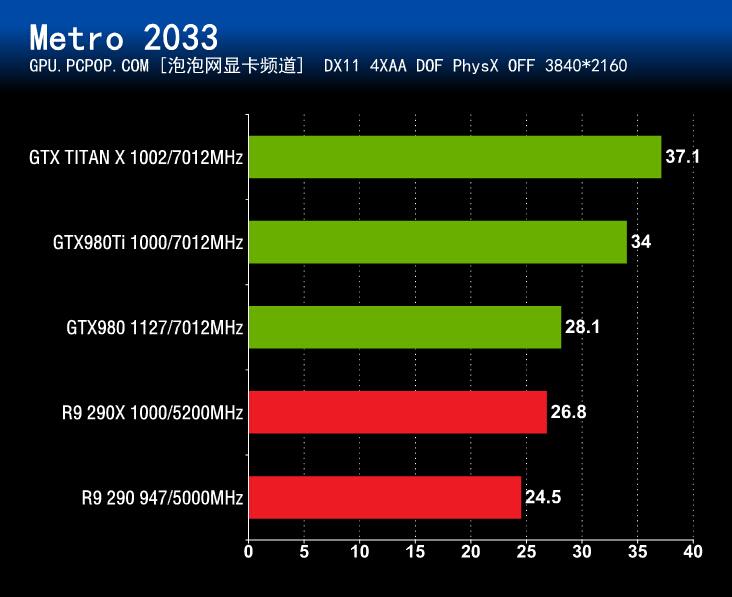
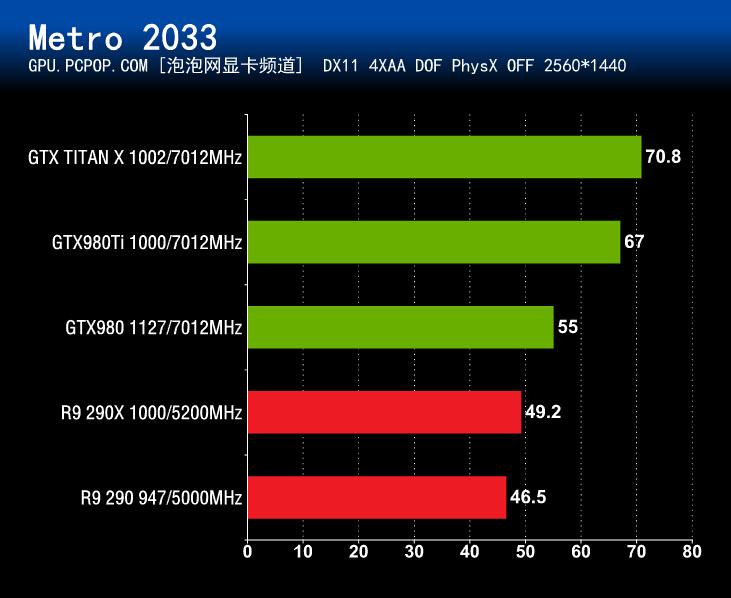
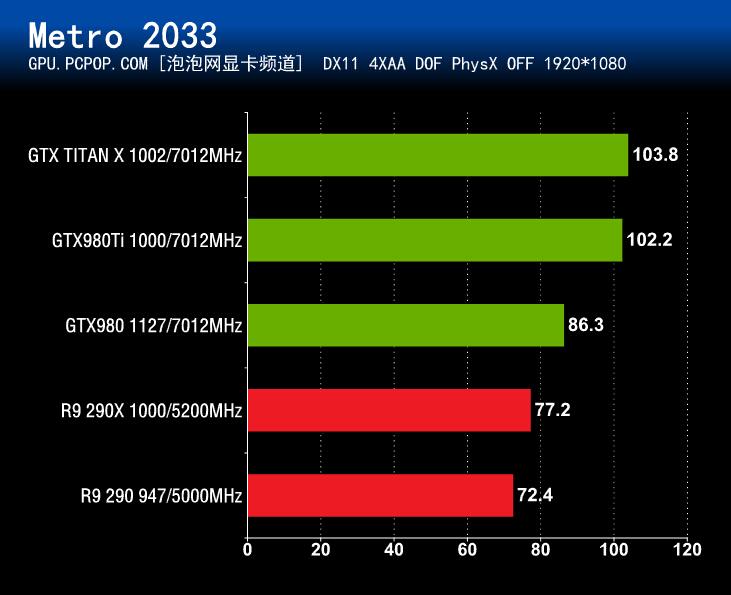
在《Metro 2033》Benchmark测试中,GTX 980Ti和GTX Titan X的成绩非常接近,即使是在4K分辨率 + 最高画质 + 最高抗锯齿的情况下,GeForce GTX 980Ti的成绩同样也是非常出色的。
《孤岛危机3》支持大量的高端图形选项以及高分辨率材质。在游戏中,PC玩家将能看到一系列的选项,包括了游戏效果、物品细节、粒子系统、后置处理、着色器、阴影、水体、各向异性过滤、材质分辨率、动态模糊以及自然光。技术主管Marco Corbetta表示之所以《孤岛危机2》并不包含这么多的选项,是因为开发主机板的开发组实在是搞的太慢了。

● 实时体积烟云阴影(Real-Time Volumetric Cloud Shadows)
实时体积烟云阴影(Real-Time Volumetric Cloud Shadows)是把容积云,烟雾和粒子阴影效果结合起来的一种技术。和之前的类似技术相比,实时体积烟云阴影技术允许动态生成的烟雾拥有体积并且对光线造成影响,和其他物体的纹理渲染互动变化。

● 像素精度置换贴图(Pixel Accurate Displacement Mapping)
像素精度置换贴图(Pixel Accurate Displacement Mapping)可以让CryEngine 3引擎无需借助DX11的细分曲面技术即可一次渲染出大量没有明显棱角的多边形。此前crytek曾透露过正在考虑在主机上实现类似PC上需要DX11硬件才能实现的细分曲面效果,看来此言非虚,新型的位移贴图技术来模拟细分曲面的效果。虽然实现原理完全不同,但效果看起来毫不逊色。
● 实时区域光照(Real-Time Area Lights)
实时区域光照(Real-Time Area Lights)从单纯的模拟点光源照射及投影进化到区域光照的实现,以及可变半阴影(即投影随着距离的拉长出现模糊效果),更准确的模拟真实环境的光照特性。
● 布料植被综合模拟(Integrated Cloth & Vegetation Simulation)
布料植被综合模拟(Integrated Cloth & Vegetation Simulation)其实在孤岛危机1代中植被已经有了非常不错的物理效果,会因为人物经过而摆动,但是这次crytek更加强化了这方面的效果,还有就是加入了对布料材质的物理模拟,这方面之前只有nvidia的physx做得比较好。
● 动态体积水反射(Dynamic Water Volume Caustics)
动态体积水反射(Dynamic Water Volume Caustics)孤岛危机1和2基本上在水的表现上集中在海水,很少有湖泊和类似大面积积水潭的场景,而这次crytek实现了超远视野的水面动态反射。动态体积水反射可以说是孤岛危机2中的本地实时反射的一个延伸,是结合静态环境采样和动态效果的新的水面反射技术。
测试成绩展示:
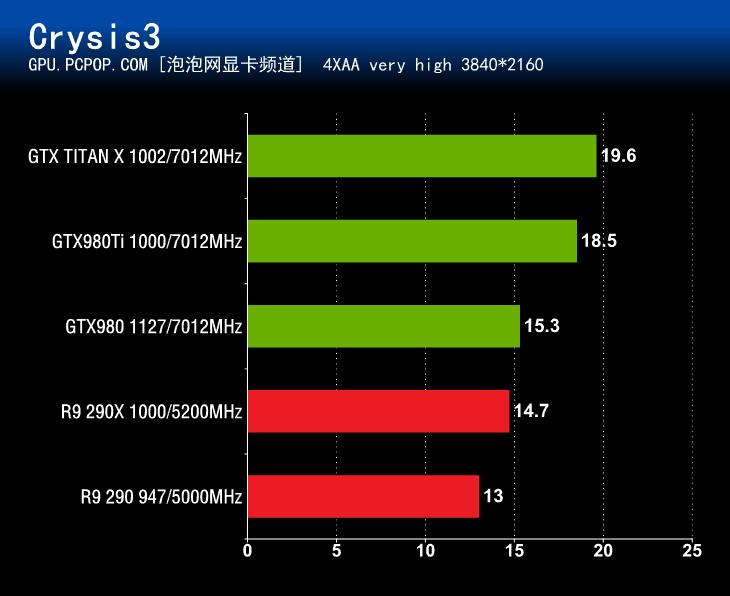
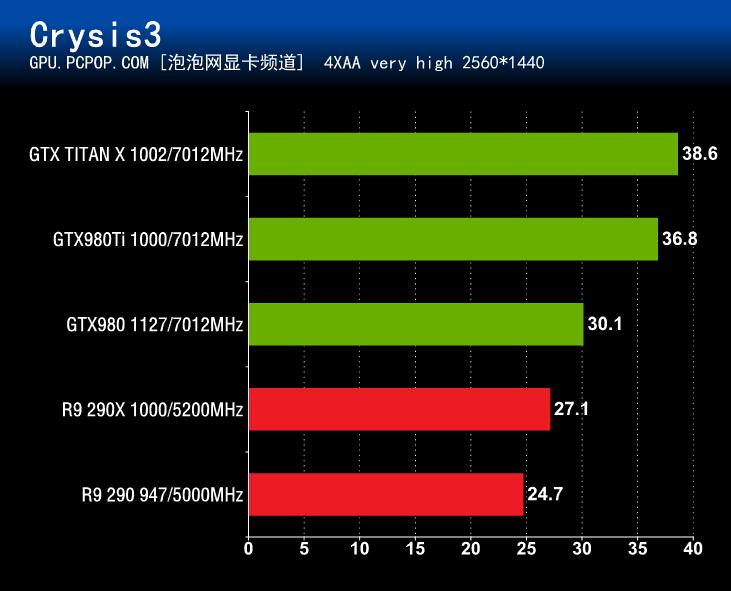
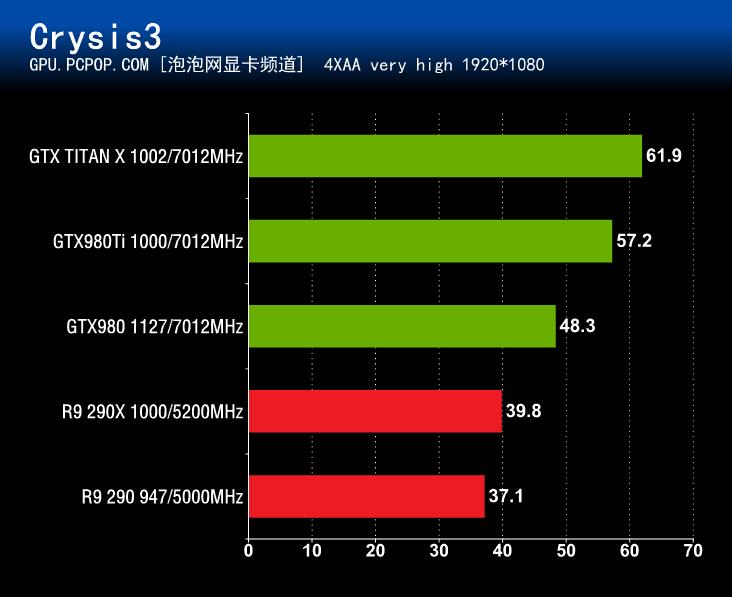
在《孤岛危机3》性能测试中,GeForce GTX980Ti充分展现了自身强大的性能实力,其成绩全面领先参测的其它3款显卡产品。
这些年我们看到了不少形态各异的劳拉,从丰乳肥臀的动作游戏主角到喜欢探索亚特兰蒂斯文明的睿智贵族。不过我们从未见过这样的劳拉。Crystal Dynamics的《古墓丽影9》让我们看到了一个参加初次探险的年轻劳拉,她遭遇海难被困在刀枪林立的小岛上,必须将自己的智谋和求生欲望提升到极限。

剧情介绍:故事从年少时期的劳拉开始,劳拉所乘坐的“坚忍号”仿佛是被宿命所呼唤,在日本海的魔鬼海遭遇到了台风,不幸搁浅。劳拉也被迫到岛上开始自己的求生经历。

“高”特效的画质已经非常不错了。
测试成绩展示:
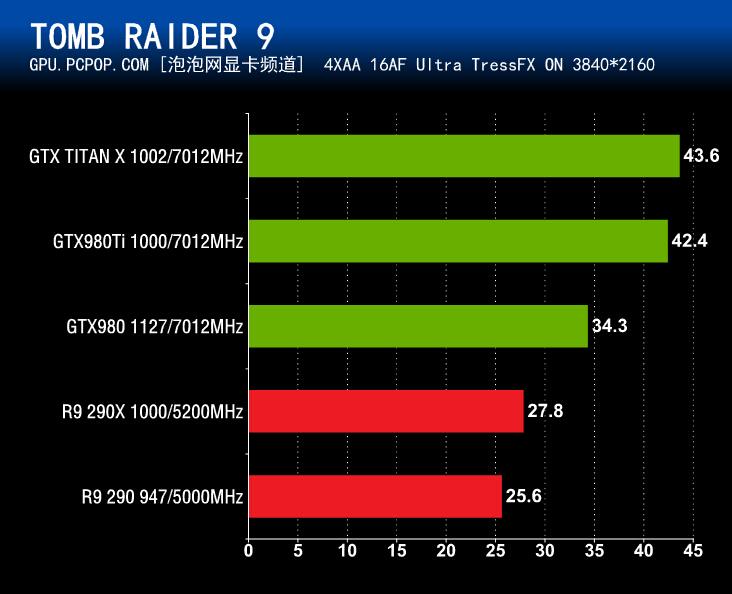
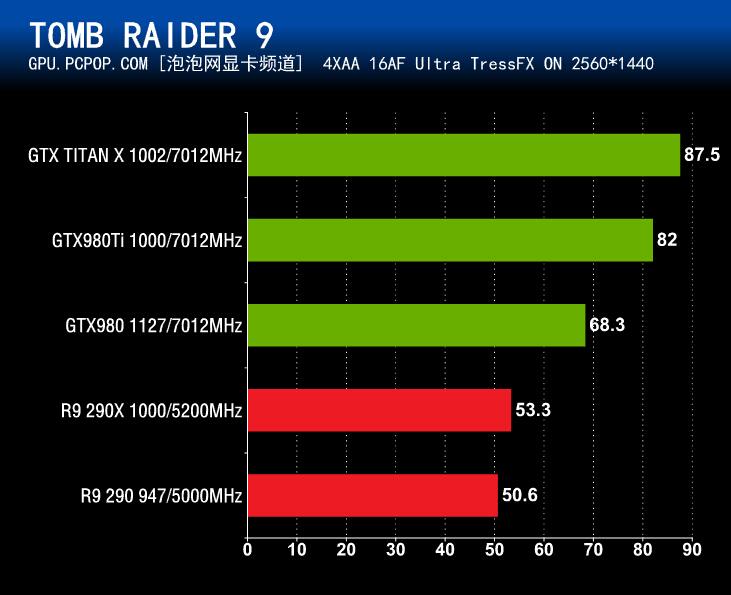
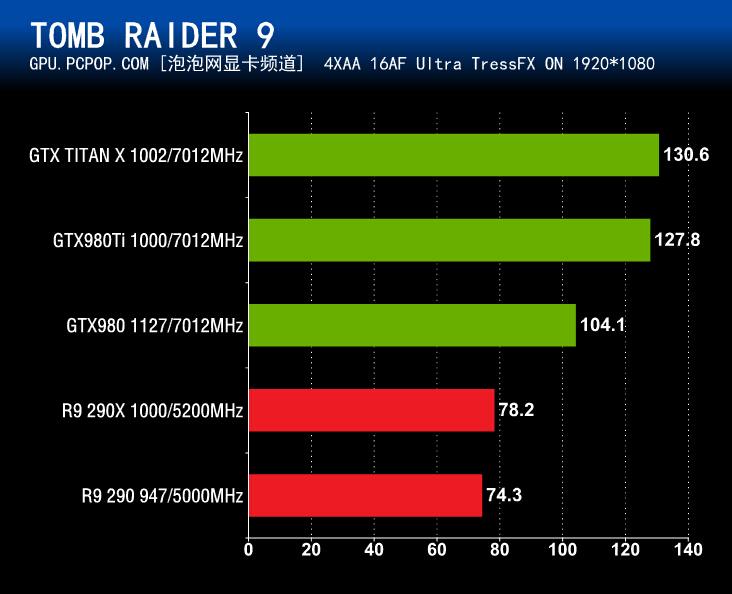
和之前的项目一样,GeForce GTX980Ti在《古墓丽影9》性能测试中跑出的平均帧数依旧明显领先其它3款产品,而且优势挺大。
《怪物猎人Online》,官方简称为MHO,是一款由CAPCOM授权,腾讯游戏和CAPCOM联合开发,腾讯游戏发行的网络游戏,以动作和角色扮演玩法为主体。《怪物猎人Online》是CAPCOM旗下《怪物猎人》的网游版,而内容则基于早前PC/XB360平台上《怪物猎人:边境Online》。
腾讯游戏在购得CryEngine3后对其进行了再开发,这让《怪物猎人Online》具有极高水准的画质。游戏暂时只在中国发行,并为PC独占。在《怪物猎人OL》的世界中,一方面玩家能够欣赏到最高清的游戏场景,感受栩栩如生的狩猎世界;另一方面,还能享受到由NVIDIA顶尖技术带来的极致细节刻画和狩猎动态效果,获得最身临其境的狩猎体验。

为了展现游戏中各种优异的光影特效和动作效果,带来最爽快的狩猎感受,NVIDIA在《怪物猎人OL》主题硬件测试程序中为玩家带来了包括:Depth of Field: Bokeh(景深技术:散焦)、Tessellation(曲面细分)、NVIDIA PhysX Clothing(NVIDIA PhysX衣料技术)、NVIDIA Hairworks(NVIDIA毛发技术)、NVIDIA HBAO+(NVIDIA新版环境光遮蔽。

测试成绩展示:
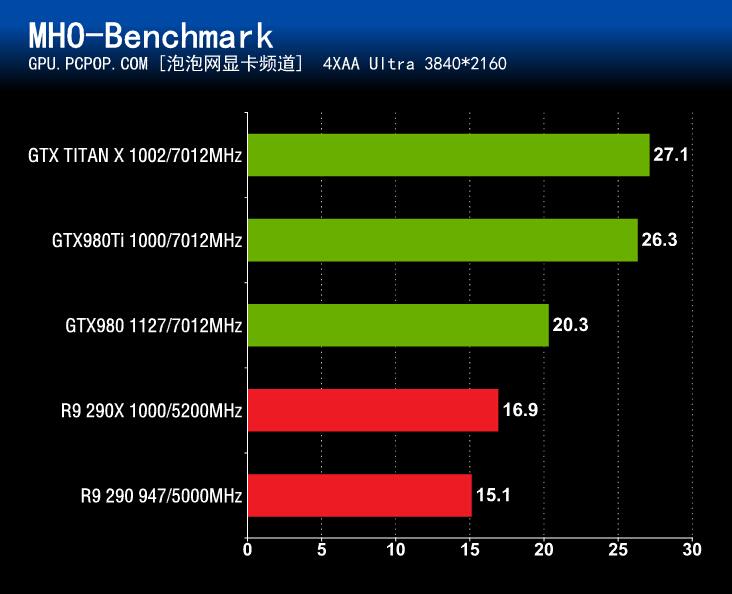
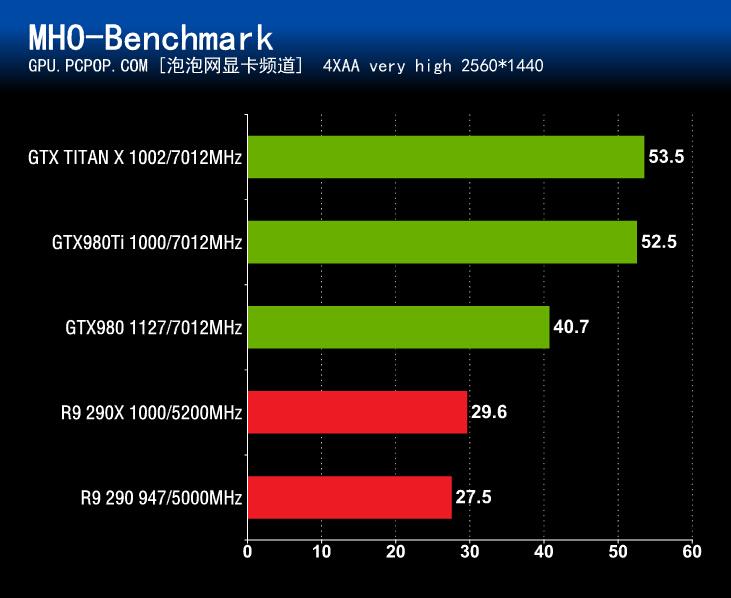
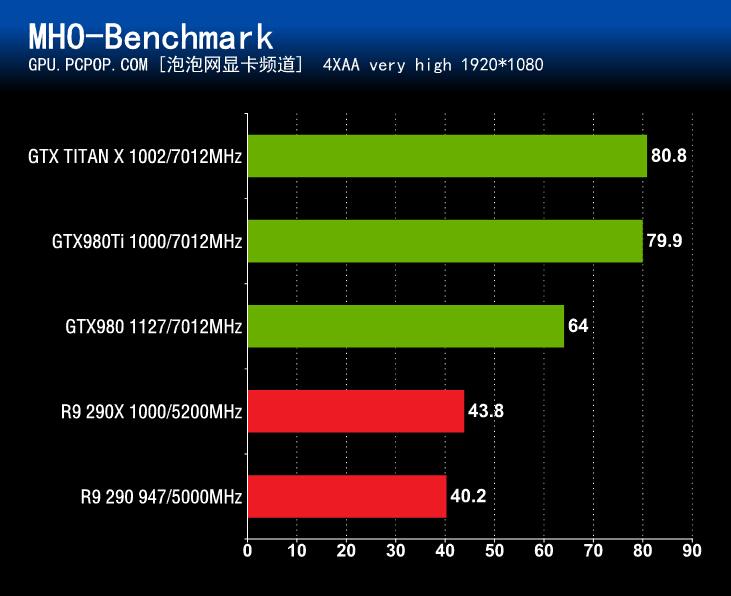
在《怪物猎人OL》性能测试中,GeForce GTX980Ti的成绩毫无疑问是非常出色的,无论是之前NV在9月份推出的旗舰卡GTX 980还是曾经和GTX Titan大战过300回合的R9 290X,与GTX980Ti相比均要弱不少。
《刺客信条:大革命》是育碧最新出品的动作冒险类游戏,本作的背景设定于18世纪法国大革命时期,玩家将会在浪漫之都巴黎完成各式各样的冒险,游戏的地图面积非常庞大,如巴黎圣母院、凡尔赛宫等著名场所甚至将以1:1呈现,力求带给玩家最真实的体验,游戏内容也基于历史制作,虽然玩家并不能改变历史,但却有机会融入其中。此外,由于采用全新技术制作,《刺客信条:大革命》在提供了逼真游戏内容的同时,也对硬件性能提出了相当高的要求。

如此逼真的画质特效打来的“副作用”也是非常明显的,《刺客信条:大革命》的PC硬件需求可以说非常高,最低要求就已经是Core i5-2500K级别处理器、6GB内存和GTX 680/HD 7970级别显卡,推荐配置则是Core i7-3770级别处理器、8GB内存和GTX 780/R9 290X级别显卡,这回恐怕连游戏发烧友都要表示“电脑压力山大”了。
测试成绩展示:
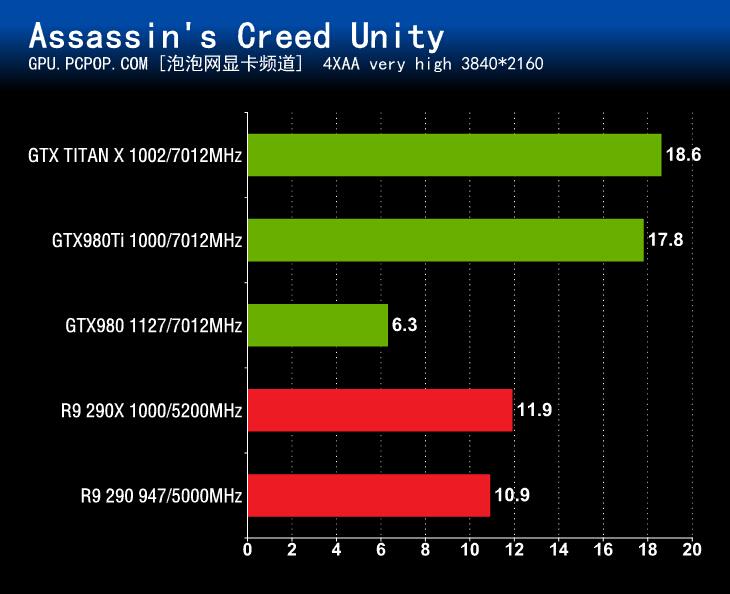
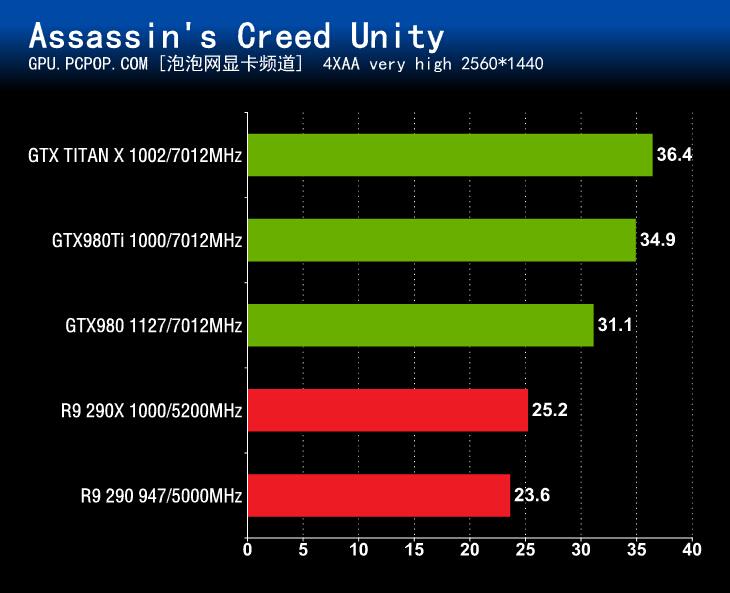
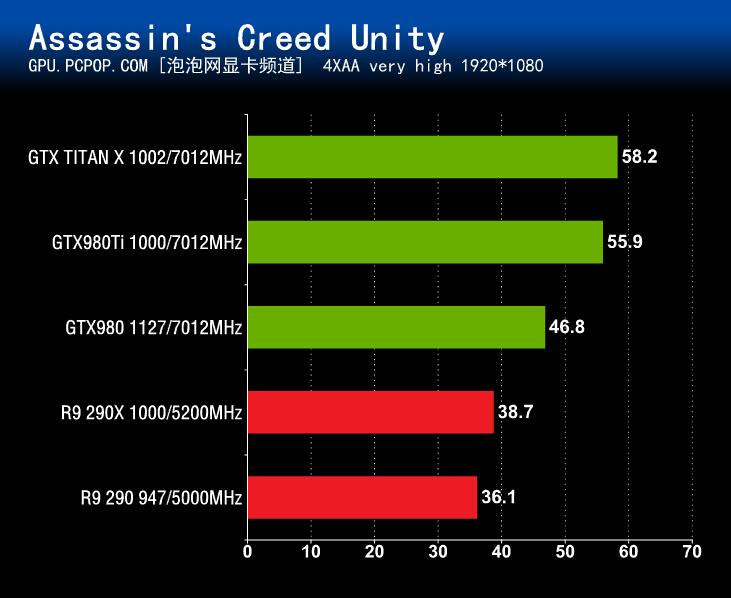
游戏性能测试的最后一项是《刺客信条:大革命》,在这项测试中,GeForce GTX980Ti一如既往的成为了参测显卡中表现耀眼的产品。而GTX980则在这次测试时我们出现了一点“意外”,有可能是显存容量不够或者游戏优化不足或者两者同时生效导致帧数暴跌,A卡和N卡显存调用机制还是有所不同的。
超频不仅可以获得免费性能,也是检测显卡稳定性的一项重要手段,所以重要产品的测试超频环节是必不可少的。GeForce GTX980Ti的默频性能固然非常强大,那它的超频潜力又怎么样呢?我们下面通过实际测试验证一下即可见分晓。
经过调试之后,笔者将GeForce GTX980Ti的核心/显存频率超到1180/7500MHz,并成功进行了多次3DMark跑分测试,下面我们就来看一看超频后的GeForce GTX980Ti在性能上有多少提升。
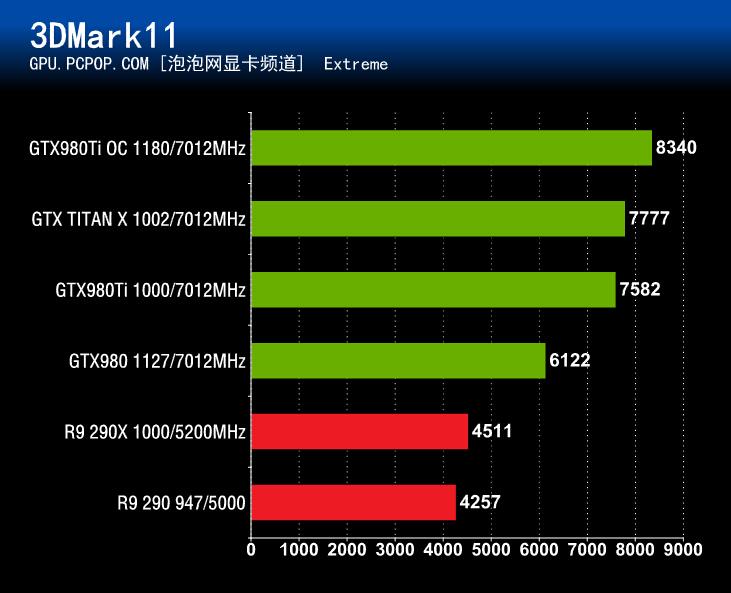
3DMark 11成绩展示:
3DMark Fire Stirke成绩展示:
3DMark Fire Stirke Extreme成绩展示:
3DMark Fire Stirke Ultra成绩展示:
通过上述成绩我们可以看到,GeForce GTX980Ti在超频能力方面的表现可以说比较不错,在不加压的情况下超个200MHz应该不是问题。而且在超频之后,这款显卡的GPU实际运行频率可以提升到1.4GHz,性能自然也就会有不小的增加,算下来应该能提升个15%左右。
好了,到此关于GeForce GTX980Ti的性能测试环节就告一段落了。接下来,我们将给大家带来本篇评测的功耗、温度以及噪音测试成绩。
GeForce GTX980Ti功耗测试:
GeForce GTX980Ti的核心规格相当强大,而它在功耗控制方面的表现同样出色。在Furmark拷机测试中,搭载GeForce GTX980Ti的平台(其它配置请参看前面的平台配置介绍,不带显示器)的满载功耗大概是353W,与本次测试中的搭载Radeon R9 290X的平台处于同一水平,但和使用GTX 980的平台相比要高大概80多W。不过,对于一款卡皇级别的优异单芯显卡,GeForce GTX980Ti在功耗控制方面已经相当出色了。
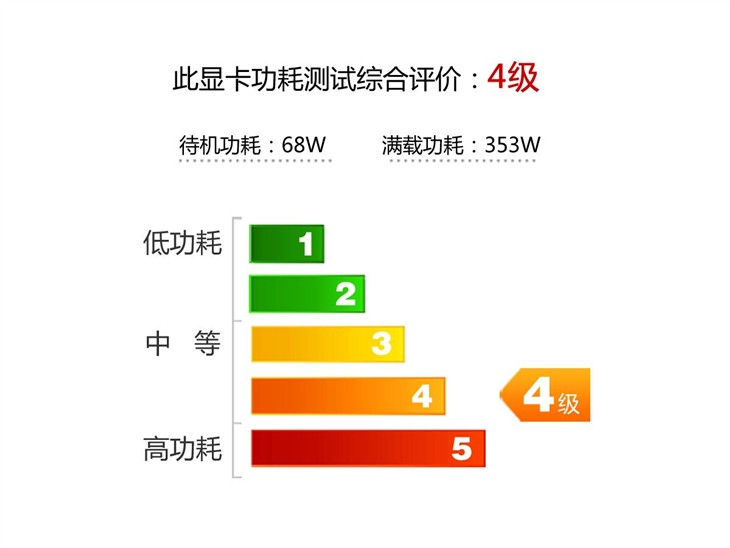
而在平台闲置功耗测试中,搭载GeForce GTX980Ti的平台整体功耗大概是68W,同样与搭载Radeon R9 290X的平台处于同一水平。
GeForce GTX980Ti温度测试:本次测试时的环境温度为26℃。
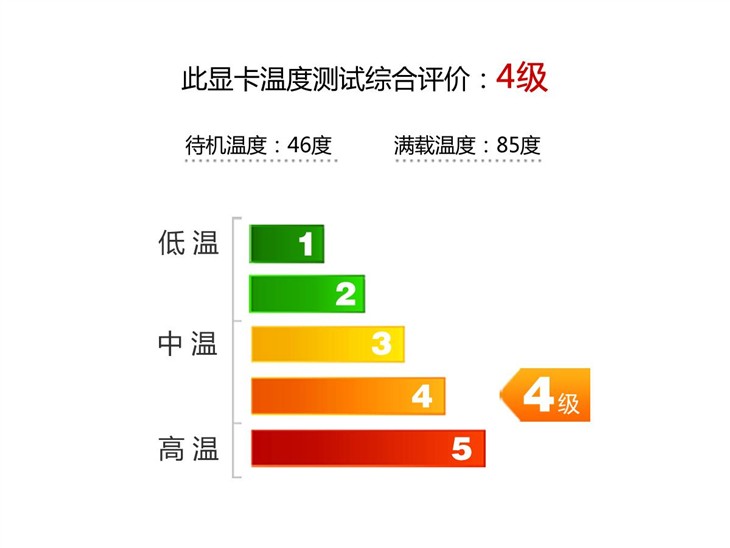
▲GeForce GTX980Ti的满载温度为85℃,待机温度为46℃
由于这款显卡的核心规格与核心面积相当庞大,这就使得GeForce GTX980Ti的核心发热量增加了不少。在用Furmark进行拷机一阵子之后,GeForce GTX980Ti的满载温度维持在了85℃,而在待机状态下,GeForce GTX980Ti显卡的温度则维持在46℃左右。这样的温度测试表现对于一款采用公版散热方案的优异卡皇来说完全可以接受。
GeForce GTX980Ti噪音测试:
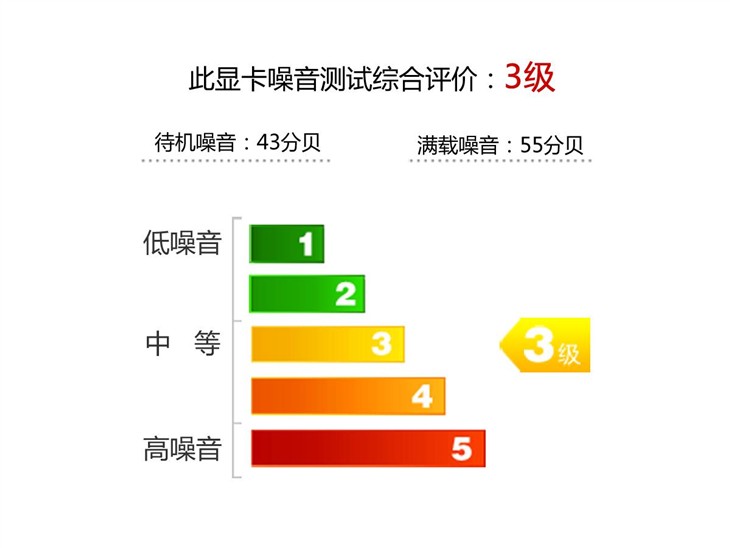
在环境噪音大概40分贝的情况下,GeForce GTX980Ti在显卡处于满载状态下的最高噪音为55分贝,而待机时的显卡运行时发出的噪音为43分贝,如果我们将它放置在机箱中,相距1M几乎听不到显卡风扇的声音。另外,困扰许多玩家的“高频啸叫”问题似乎没有出现在GeForce GTX980Ti显卡上,这得归功于使用了模压电感和极化电容,它们可以最大限度地消除这种现象,大幅提升玩家的游戏体验。
&nbs
前不久,采用Maxwell架构优异GPU GM200的GeForce GTX TITAN X显卡凭借着优异的架构、强大的规格轻而易举的从NV自家的GeForce GTX 980手中接过了“地球最强单芯显卡”的桂冠。它的每一项优势,都是压倒性的,都是之前的卡皇、旗舰们所不能比拟的。

但如果用GTX TITAN X来玩游戏或许有点大材小用了,它标配12GB显存决定了它的定位并不仅仅是玩游戏,而且设计开发等对显存需求变态的领域。这次采用了删减版GM200核心,标配6GB显存的GTX980Ti才是真正的游戏利器,通过上面的测试我们发现,GTX980Ti和GTX TITAN X在各个游戏中的表现非常接近,TITAN X确实比GTX 980Ti强但程度有限,事实上目前即使开启4K分辨率,也没有什么游戏能用到6GB以上显存,除非打开DSR,后台渲染8K!这么变态的设置,一般人就不要去尝试了。综上所述,GeForce GTX980Ti是NVIDIA旗下专门为4K分辨率准备的单芯游戏显卡。

价格方面,GeForce GTX980Ti自然要比GTX TITAN X要亲民不少,后者的官方指导价为7999人民币,与之前GTX Titan、GTX Titan BE的首发价保持不变,GTX 980Ti嘛,至少便宜30%问题不大。

GTX980Ti再次展现了GM200核心的实力,目前看来NVIDIA高端对AMD显卡形成了碾压之势,但高端独显市场NVIDIA独领风骚这种情况能持续多少时间并不好说。六月份AMD大杀器Radeon R9 390X将和大家见面。毕竟HBM 2.5D立体堆积显存被誉为显存历史上第一次直立行走,虽然实卡还没发售,但在功耗、性能甚至显卡大小方面都会有惊喜!而据说是真正3D堆积的HMC显存的下一代N卡也快要量产了,显卡市场山雨欲来,A/N卡皇之战即将拉开序幕!■<
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}