

Conroe强在哪儿?Core vs K8架构解析
接下来让我们来看一下这有趣的对比:Core 微架构的3组简单解码单元与1组复杂解码单元 vs. K8 处理器的3组复杂解码单元。
K7 处理器有2种解码方法,向量路径(Vector Path)和直接路径(Direct Path)。向量路径解码会生成多于2条的类似RISC的指令(AMD称为Macro-Op,即宏指令)。直接路径解码会生成1条或者2条宏指令。K7 处理器的每组解码单元都可以进行向量路径解码和直接路径解码,但是从性能的角度讲,直接路径解码无疑是更好的选择,因为它会生成数量较少的宏指令。怎么,你觉得突然谈论 K7 处理器有点奇怪?不,因为就像 Core 微架构是基于 P6 微架构一样,K8 处理器很大程度上也是基于 K7 处理器的。
K7 处理器的3组复杂解码单元是强大的,可以解码绝大多数X86指令,只有很少一部分指令需要使用向量路径解码。它们仅有的缺点是一些浮点指令和SSE指令需要使用向量路径解码。而 K8 处理器拥有更强大的复杂解码单元——几乎所有的浮点指令和SSE指令都可以使用直接路径解码了。这是因为K8 处理器的取指与解码单元的流水线比 K7 处理器的更长。当涉及到SIMD指令时,K8 处理器尤其强于 K7 处理器。
显然,Intel 的宏指令融合技术在AMD 的 K8 处理器上并不存在。但是,AMD拥有与微指令融合技术类似的技术。首先需要注意的是,Intel 与 AMD 使用的名词“宏指令”与“微指令”具有不同的含义,很容易使人混淆。这里我们给出下面的表格,对它们进行分辨。
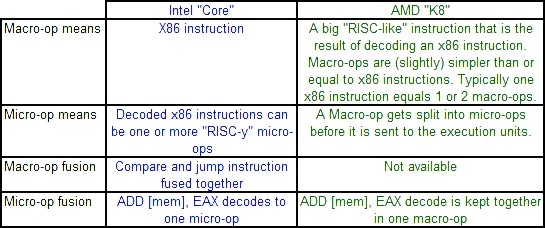
 名词辨析
名词辨析
在 Athlon 处理器中,也存在有微指令融合技术。例如,一条 ADD [mem], EAX 指令在真正执行前中始终保持为一条指令。因此,它在缓冲区中也只会占据1个单元的空间。不过,在 Core 微架构中 load 操作和 SSE 操作等也可以被融合,而 K8 处理器则不行,它会把SSE操作解码成2条宏指令。
那么,在解码单元方面,Intel 的 Core 微架构与 AMD 的 K8 处理器比较的结果是什么呢?就目前的资料来看,还很难确切的说到底哪个更加有实力。不过,我们有一个初步的看法:Core 微架构要更具有优势。因为在一般情况下,它每个时钟周期可以解码4条X86指令,加上宏指令融合技术的话则最多可以解码5条X86指令。而 AMD 的 K8 处理器每个时钟周期只能解码3条。
总而言之,AMD 的3组复杂解码单元胜过 Core 微架构的3组简单解码单元加上1组复杂解码单元的情况不大可能发生。仅当多条复杂指令同时需要复杂解码单元进行解码的时候,K8 处理器的解码单元会胜过 Core 微架构的解码单元。但是考虑到实际程序中的绝大多数X86指令对应简单解码单元的事实,这种情况不大可能发生。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}