

Conroe强在哪儿?Core vs K8架构解析
自从采用 P6 微架构的 Pentium Pro 处理器之后,X86 处理器开始拥有乱序发射和执行指令的能力。不过,乱序缓冲区内平均大约三分之一的指令很难重排序——就是那些 load 操作。把 load 操作提前执行可以极大的提高性能。与需要数据的时候才进行 load 操作相比,尽可能早的开始 load 操作十分有用,因为这可以更有效的把一级缓存及二级缓存的延迟隐藏掉。
这很容易理解。假设现在有一个 ALU 操作需要某数据,可是该数据不在一级缓存中。如果 load 该数据的操作在该 ALU 操作之前就已经执行完毕,那么访问二级缓存的延迟就不会对性能产生影响。不过,需要注意的是,如果 load 操作针对的数据在程序中还有 store 操作要对其进行写入,那么就不能把 load 操作提前到该 store 操作之前执行。因为这样的情况下,如果提前执行 load 操作的话,意味着你得到的会是错误的数据,而不是最新的。
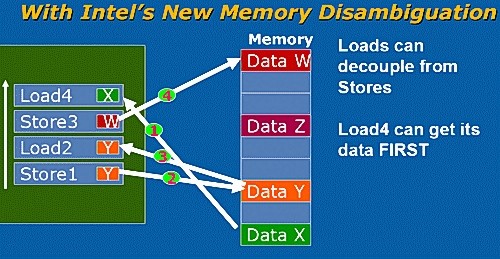
 Intel 内存相关性预测技术
Intel 内存相关性预测技术
上图中的 Load 2 操作不能提前执行,因为它操作的数据与 Store 1 操作的数据相同,需要等待 Store 1 操作先完成。只有 Store 1 执行完毕,数据Y才拥有正确的值。不过 Load 4 操作没有理由不能提前进行,它不需要等待 Store 1 或者 Store 3 操作完成。这样,通过把 Load 4 操作提前,load 单元有更多的时间去获得正确的操作数。
不过,之前的处理器在这种情况下——有 store 操作存在——都不会把 load 操作提前。因为处理器不知道 store 操作针对的数据单元与 load 操作是否相同。如果想要搞清楚是否相同的话,需要计算存储器地址。这十分困难,因为在指令乱序和调度的时候,存储器地址还是未知的。
这时需要注意一个事实:load 操作读取到一个错误数据的概率相当小,只有1%到2%。所以,Intel 的 Core 微架构设计师 Jack Doweck 决定,允许所有的 load 操作提前执行,假设所有的 load 操作读取到的数据都是正确的。而为了应对错误的发生,Intel 加入了一个预测器。
根据 Jack Doweck 的描述,以及我们对以前的 P6 微架构和 Pentium M 处理器的了解,我们制作了下面的图表。注意这并非 Intel 官方的图表。
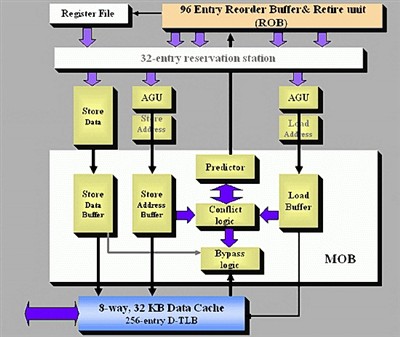
Core 微架构乱序执行引擎
预测器做出预测,并指示乱序缓冲区是否可以把某 load 操作提前执行。在 load 操作提前执行之后,冲突监测单元会扫描MOB(Memory Reorder Buffer),查看是否有 store 操作与 load 操作冲突。如果有冲突发生的话,load 操作必须重新执行,这时大约会损失20个时钟周期。不过与之前的处理方式相比,Core 微架构采用的这种处理方式总体上肯定可以提高处理器的效率。
检测某 load 操作和某 store 操作是否是针对同一内存地址的行为称作内存相关性预测(memory disambiguation)。Core 微架构允许 load 操作提前到 store 操作之前执行的处理方式可以带来性能上的巨大提升。在某些测试代码中,这个提升甚至达到了40%。虽然我们在实际的应用程序中不会看到如此大的提升,但是无疑这项技术会带来令人印象深刻的提升——我们可以期待10%到20%的性能提升。
不要忘记,load 操作可能是所有操作中最重要的操作。不仅仅因为 load 指令占了X86处理器内所有微指令的三分之一强,还因为当 load 操作发生时可能导致的巨大延迟会引起处理器的等待。那么,这项极其灵活的 load 操作乱序执行技术与其它架构的处理器相比是什么情况呢?
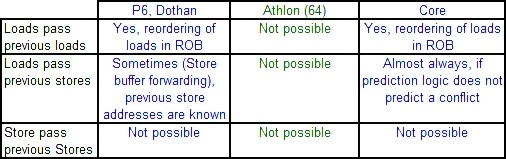
Load 操作处理方式比较
旧的 P6 微架构和 Penium M 处理器也已经可以较好的处理 load 操作,可以把某 load 操作提前到另外的 load 操作之前进行,也可以提前到已知不会发生冲突的 store 操作之前进行。P6 微架构的内存乱序缓冲区(Memory Reorder Buffer,简称MOB)采用如下的规则:如果在乱序执行窗口中存在与某load操作内存地址相同的store操作,则该load操作不能提前执行;如果在乱序执行窗口中存在内存地址未知的store操作,则任何load操作不能提前执行;某store操作不能提前到另外一个store操作之前执行。
相比之下,K8 处理器要逊色的多,它只能把 load 操作移动到不相关的 ALU 操作之前进行,而不能移动到其它 load 操作之前,当一个 load 操作等待某 store 操作执行的时候,处理器会浪费大量的时钟周期。这意味着 K8 处理器在指令乱序这方面受到极大的限制。
这也许是 K8 处理器在游戏和整数计算等方面输给 Core 微架构的最重要的原因之一,尽管它拥有延迟更低的内存子系统和更多的整数执行资源。整数运算进行的存储器操作经常有许多未知的地址需要计算,而浮点运算则不是这样,它对存储器的访问是更加规范的。这也是 K8 处理器在浮点运算方面不输给 Dothan 处理器的原因之一。
当 load 操作和 store 操作都已经进入 Load/Store 单元的队列中的时候,K8 处理器允许 load 操作在不冲突的 store 操作之前执行。不幸的是,这时把 load 操作提前执行已经不能隐藏缓存缺失所带来的延迟。你可以认为这是 K8 处理器拥有的 Load/Store 乱序机制,但是它在流水线中的位置太靠后,比起 P6 微架构、Pentium M 处理器和 Core 微架构所采用的技术相差甚远。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}