

完美DX10!ATI新王者HD2900XT权威评测
自从ATI在R300(9700)上面首次使用256Bit显存位宽之后,高端显卡的显存控制器已经连续五年停滞不前,显存带宽的提升只能依赖于DRAM厂商生产出速度更快的显存颗粒,从GDDR1一直发展到GDDR2/3/4,高频显存对显卡的PCB和散热设计提出了很高要求,显存在显卡成本中所占比例也越来越高,显卡性能一定程度上受到了显存带宽的制约。新一代DX10游戏对显存带宽需求变本加厉,所以NVIDIA和ATI不约而同的升级了显存控制器,G80支持384Bit,而R600则是翻了一倍达到512Bit!

 512Bit显存带来性能飞跃
512Bit显存带来性能飞跃第四章\\第十节 Memory Control(显存控制器)
G80的显存控制器很容易理解,与G71相比就是添加了两组64Bit控制器,每组显存控制器都与ROP绑定,从而组成了384Bit的位宽,依然是(Crossbar)交叉式结构。之所以不用512Bit,一方面是出于显存成本方面的考虑,当然还有一个原因就是交叉存取的结构在规模较大时管理非常复杂,PCB布线难度大增,信号延迟容易增大。
G80的ROP和显存控制器
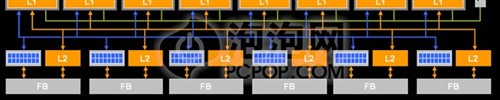
这就是ATI引入环形总线的原因,从R520开始我们就接触到了Ring Bus这个词,R520内部显存总线其实是512Bit(即两个256Bit环形管道),4个环站和8组32Bit显存组成:
R520的显存控制器
为什么要这么设计呢?主要是在提高带宽的同时减缓显存控制器的压力。当程序指令提出显存读取要求时,显存控制器会安排数据从显存颗粒中读取,但数据不会回传至显存控制器,而是只把数据放在环形总线之中,然后程序自行通过环站取回所需数据包,从而减轻控制器的压力。这种方式对于单个的存取操作有可能会使延迟变大,但总体来说能够降低大多数操作的延迟,而且提高数据命中率!
环形总线围绕在控制器的外围,这样可以简化线路设计使连接处于最优化状态。这意味着任何时候内核各部件都能处于最短的连接线路状态,这样在显存进行数据写入操作过程中有效降低延迟及降低信号品质。当然环形总线的另一大优势就势可以轻松达到高频率,传统显存控制器则由于显存控制器内部线路之间的串扰等原因很难保证GDDR4这种高频显存的效能!
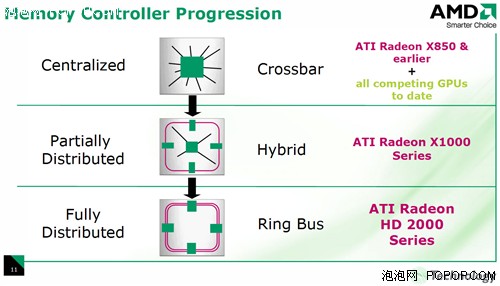
ATI显存控制器的演化
但是,X1000系列的显存控制器并非是真正的环形总线,它只是通过引入两条环形管道来分担中央控制器的压力,这可以说是ATI做出的一个大胆尝试,X1000系列属于半分布式的混合型控制器。而在R600上面,ATI真正实现了全分布式的环形总线:
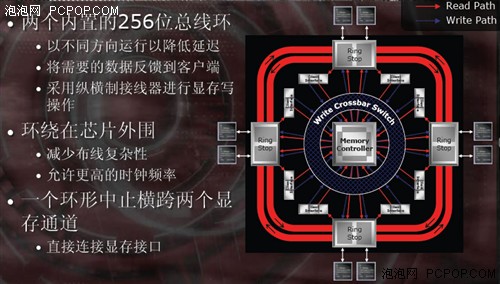
 R600内部1024Bit环形总线,外部512Bit总线
R600内部1024Bit环形总线,外部512Bit总线R600的显存控制器拥有2条512Bit环形通道和四个环站,每个环站控制两个64Bit显存通道,可以看到R600不存在中央控制器,所有显存读写操作都由四个环站经过仲裁器判定后执行:
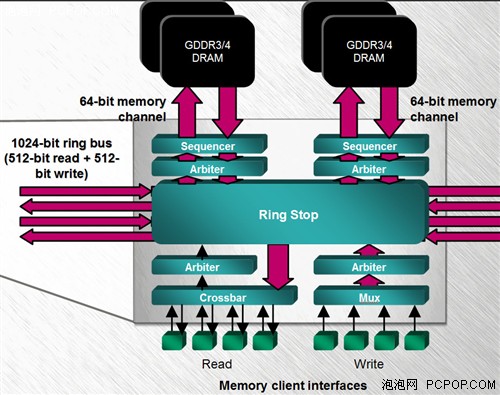 R600显存控制器之环站结构
R600显存控制器之环站结构可以这么认为,如果是传统交叉式显存控制器的话,必须统一指挥8个64Bit通道,而R600的4个环站只需各自管辖2个64Bit通道就可以了,然后四个环站通过1024Bit(读写各512Bit)内部总线连接起来,所有操作都通过仲裁器优化和排序后执行,比起混乱的交叉操作更加有序和高效!
如此一来,R600的环形总线可以达到更低的延迟、更高的频率、更大的带宽。同时也可以一定程度上降低PCB布线难度,将16颗显存之间的干扰降至最低,稳定性更容易保证,对于GDDR4提供了完美支持。在现有的技术条件下,R600可以轻松实现1GB 512Bit和512MB 512Bit两种实用的组合方案,今天发布的HD 2900XT就是512MB 512Bit(16颗8M×32Bit颗粒)的规格,未来还会有1GB 512Bit GDDR3/4的XTX版本。
另外,ATI的双向环路总线是可编程设计的,显存仲裁操作可以交由驱动程序控制,或者是用户通过驱动程序的“CATALYST A.I(智能参数设定)”功能为特定的应用程序设定仲裁优先次序,以便GPU可以优先处理最迫切、对性能影响最明显的数据读写请求。

关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}