

完美DX10!ATI新王者HD2900XT权威评测
分享
第六章\\第二节 抗锯齿技术的发展
虽然MSAA基本被所有游戏所支持,但不可否认无论MSAA还是SSAA都存在很大的局限性,因此图形芯片厂商都在不断的改进抗锯齿算法或者启用新的抗锯齿技术,下面就来看看一些通过显卡驱动实现的特殊抗锯齿:
● 暂时性(Temporal)抗锯齿(ATI专用)
X800时代,ATI除了改进Z轴压缩效率之外(可提升AA效能),还加入了Temporal Anti-Aliasing(暂时性抗锯齿)这种新的模式。此前的抗锯齿采样点是不变的,但Temporal抗锯齿(需要打开垂直同步)使用不同的采样格式,它通过奇偶帧随机采样并合成的方法来达到效果,因为人眼的视觉有暂停残留的特点,这样产生的影像就如同实际采样的两倍,采用2x Temporal抗锯齿效果就相当于4xMSAA了。因此Temporal 抗锯齿在工作量与一般的全屏抗锯齿相同的情况下,使画面又提升了一个等级。
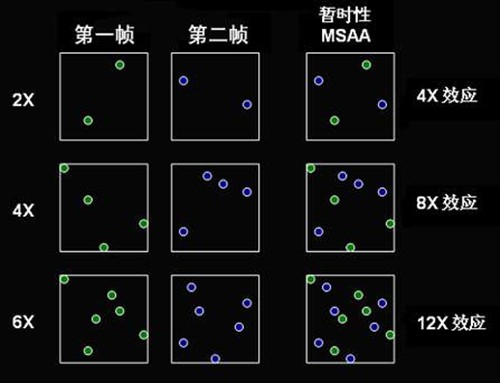
但Temporal抗锯齿在应用方面有一定局限性,由于整个渲染场景是通过奇偶帧显示,如果FPS过低时,屏幕就会产生闪烁。实际使用中当FPS低于60, ATI的驱动就会自动关闭Temporal抗锯齿而改用普通MSAA,直到FPS增加到60帧以上为止。
由于目前的游戏极其消耗资源,高端显卡都很难保证60帧以上的运行速度,Temporal抗锯齿由于采用垂直刷新同步,最高刷新率值还要受到显示设备(特别是液晶显示器)刷新率的限制,因此使用面比较狭窄。
● 自适应(Adaptive)抗锯齿
MSAA虽然得到了大量使用,但有一个重要缺陷就是不能处理Alpha材质,因此在一些栅栏、树叶、铁丝网等细长的物体上就不能起作用了。为了解决这种问题,NVIDIA在GeForce 7系列加入了透明(Transparency)抗锯齿,ATI在X1000系列加入了自适应(Adaptive)抗锯齿,通过额外的多重采样甚至是超级采样来强制提升画质。
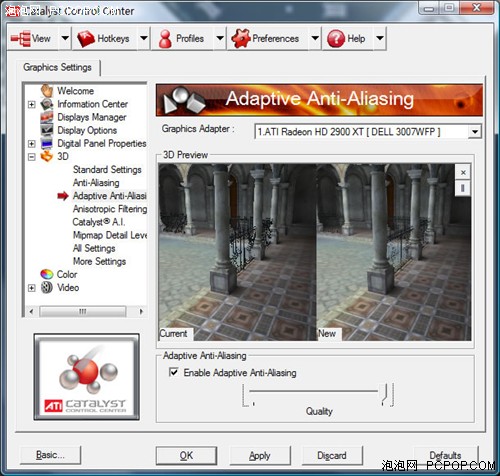
 催化剂驱动中的自适应抗锯齿开关
催化剂驱动中的自适应抗锯齿开关
普通的抗锯齿(左图)与透明自适应抗锯齿(右图)
自适应抗锯齿可以专门针对Alpha材质选择性的进行多级或是超级采样,这样就比完全采用SSAA拥有更低的性能损失,画面质量依旧完美!
● 双卡互联,让AA等级成倍提高
受限于GPU处理能力以及显存带宽,单显卡很难实现高倍AA,比如常用的MSAA采样数一般为2x或者4x,几乎所有的主流显卡和游戏都能支持这两种模式,而ATI为了进一步提高图像画质,加入了更高级的6x模式,因此A卡用户在很多游戏中就能直接打开6xAA(HD 2000系列提高到8xAA),而N卡最高只能到4xAA(GeForce 8系列提高到8xAA)。
为了在有限的技术条件下进一步提升抗锯齿精度,有两条路可选:一是采用组合算法(MSAA+SSAA),二是双显卡分别采样然后复合。这两种方案目前已经被ATI和NVIDIA广泛使用:
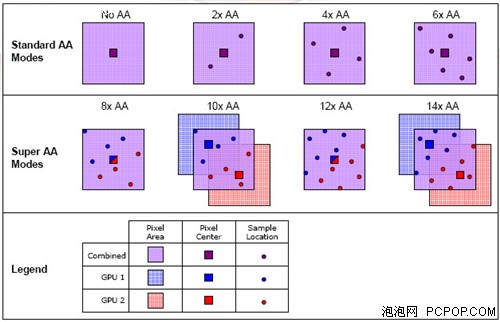
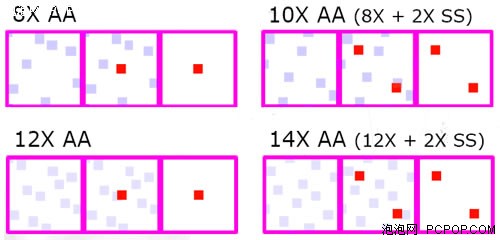
由上图可以看出,组建交火系统之后,让两颗GPU分别进行不同位置的采样,然后复合,这样就能直接生成8xAA(4+4)和12xAA(6+6)两种模式。ATI将双卡提供的高倍AA称为Super AA,因为下面要介绍的两种组合AA模式中包含了超级采样。
● 组合AA技术:
为了进一步提升抗锯齿精度,NVIDIA和ATI都选择了以MSAA为主,SSAA为辅的组合方式,由此诞生了更高等级的AA算法,虽然游戏无法直接支持,但通过驱动强制开启后,画面品质可以得到明显改善。
ATI在双卡实现8x和12x的基础上,如果再加入2xSSAA,就能最高提升到14xAA。为什么不加入更高倍数的SSAA呢?因为性能损失太大就失去了实用价值,让双显卡共同完成2xSSAA代价就少了很多。
实际上,NVIDIA很早就采用了组合AA技术。由于N卡的MSAA采样数要低于A卡,因此NVIDIA加入了8xS模式(4xMSAA+2xSSAA),在AA等级上超过了A卡。这种模式起初被称为6xS,但其中的2xSSAA效果明显高于2xMSAA,接近4xMSAA的效果而且还附带透明抗锯齿效果,因此被改名为8xSAA以表示该模式画质高于ATI的6xMSAA。事实的确如此,但8xS性能损失太大,只敢在较早的游戏中开启这种模式。
NVIDIA双卡组建SLI技术之后也能够轻松将AA精度翻倍,从而获得8xSLIAA(4xMSAA+4xMSAA)和16xSLIAA(8xSAA+8xSAA=4xMSAA+4xMSAA+2xSSAA+2xSSAA),与ATI的14xSuperAA相比,NVIDIA需要进行两次2xSSAA而ATI只需要一次,开销非常大,导致16xSLIAA效能低下,最实用的还是8xSLIAA。相比之下ATI还有10xSuperAA、12xAA等灵活的模式。

0人已赞
第1页:完美DX10!ATI新王者HD2900XT权威评测第2页:完美DX10!ATI HD2000系列评测提纲第3页:2007显卡年!AMD/NVIDIA决战图形市场第4页:奋起直追!全新Radeon HD 2000产品线解析第5页:功能化发展!Radeon HD2000系列亮点逐个看第6页:第二章:统一渲染架构解析第7页:第二章/第二节:革命!R600的统一渲染架构第8页:4第9页:第三章:DirectX发展回顾以及DirectX10详细介绍第10页:第二节 DX10的架构特性 以及带来的好处第11页:第三章/第三节:ATI 3Dc功能回顾第12页:3第13页:3第14页:3第15页:3第16页:集众家之长,R600架构总览第17页:R600架构分块介绍第18页:Setup Engine(装配引擎)第19页:Ultra-Threaded Dispatch Processor(超线程分配处理器)第20页:Stream Processing Units(流处理器)第21页:R600的超标量SIMD架构第22页:4第23页:5第24页:ATI片内缓存相关技术第25页:Memory Control(显存控制器)第26页:第六章 R600的神工鬼斧——Tessellation技术第27页:第六章\\第二节 传统的虚拟3D技术回顾第28页:第二小节 凹凸贴图 Bump mapping第29页:第六章\\第二节\\第三小节 法线贴图(normal mapping)第30页:视差贴图技术parallax occlusion mapping第31页:位移贴图(displacement mapping)第32页:Ati的独门秘籍 Trumform 第33页:Tessellation技术第34页:神奇的小数点——细分网格算法中小数位的意义第35页:Tessellation效率的源泉——控制“笼子”第36页:Tessellation技术的流程第37页:Tessellation技术的应用和前景第38页:1第39页:AA发展第40页:CFAA第41页:123第42页:ATI显卡产品形象代言人——Ruby四度出击第43页:X800 & X850 Ruby第44页:DX9C的最高境界 X1800 Ruby第45页:R600 DX10 Ruby高清晰截图赏析第46页:R600 DX10 Ruby引擎和技术解析第47页:23第48页:R600 DX10 Ruby所用图形引擎揭秘第49页:1第50页:2第51页:第九章\\第二节第52页:庞大的运算资源,R600单卡就能物理加速第53页:3第54页:第四章:AMD高清视频功能解析第55页:22第56页:第三节 硬件视频加速第57页:第四节 UVD 引擎解码流程第58页:第五节 UVD测试第59页:第一节 电脑音频的数码之路第60页:第二节 HDMI数字音频技术背景第61页:第三节 各种显卡HDMI接口方案第62页:第四节 R600系列方案第63页:第五节:实战R600音频播放第64页:第六节 HD 2900XT怎么用?第65页:显卡介绍第66页:123123第67页:显卡介绍第68页:123第69页:显卡介绍第70页:3第71页:123123第72页:测试系统配置和设置第73页:阿苏大发送颠覆第74页:113123第75页:4第76页:05第77页:06第78页:游戏第79页:游戏第80页:123第81页:6第82页:6第83页:交火第84页:功耗测试第85页:1第86页:第二节 客观,公正,专业,全面,泡泡网为您带来最权威的DX10测试第87页:第三节 Call of Juarez游戏DX10测试 第88页:第四节 DirectX SDK测试(微软官方2007年四月版)第89页:第四小节:Draw Predicated第90页:第七小节:MotionBlur10第91页:第十小节:Skining 10第92页:第十四章 总结 另觅蓝海!AMD让ATI看得更远第93页:123
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}