

完美DX10!ATI新王者HD2900XT权威评测
分享
第六章\\第三节 DX10时代,NVIDIA和ATI大幅改进AA算法和精度
随着时代的发展和GPU性能的飞跃,玩家对游戏画质提出了更高的要求,传统的4xMSAA已经难入苛刻玩家的法眼,于是到了DX10这一代,NVIDIA和ATI相继改进AA算法,将精度提升到了之前难以想象的境界!
● NVIDIA GeForce 8系列全新CSAA(Coverage Sampled,覆盖采样)技术:
由于上代产品中N卡4xMSAA小于A卡6xMSAA,8xSAA效能太低,16xSLIAA也存在相似的局限性问题。因此NVIDIA在GeForce 8系列做出了大幅改进,将色彩样本数目提高至8个,从而直接支持8xMSAA,同时也将覆盖样本数提高至16个,这样通过不同的组合模式就能够支持8xCSAA、16xCSAA和16xQAA等多种模式。其中效率最高的模式就是8xCSAA和16xCSAA(Coverage Sampled Antialiasing,覆盖采样抗锯齿)。
NVIDIA GeForce 8系列显卡抗锯齿模式 | ||||||
抗锯齿模式 | 2x | 4x | 8x | 8xQ | 16x | 16xQ |
色彩/深度值采样数 | 2 | 4 | 4 | 8 | 4 | 8 |
覆盖采样数 | 2 | 4 | 8 | 8 | 16 | 16 |
可以看出,NVIDIA GeForce 8系列的CSAA可以在确保完成16或者8倍覆盖采样的情况下,像素只需要保存4份深度值和色彩值,由此显著降低内存带宽压力,从而让AA效率大幅提高。
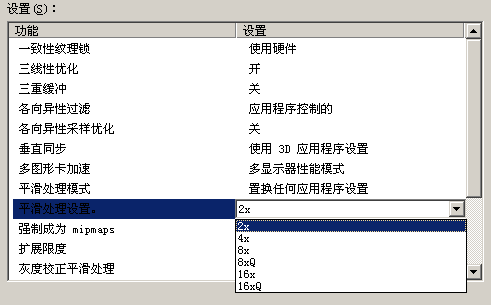
 驱动中提供了8x(CS)、8xQ(MS)、16x(CS)和16xQ(CS)四种新AA模式
驱动中提供了8x(CS)、8xQ(MS)、16x(CS)和16xQ(CS)四种新AA模式 由于色彩/深度只进行4次采样,因此8xCSAA和16xCSAA相比普通的4xMSAA性能损失非常小,但所带来的画质改善却是非常显著的!如果您拥有8800GTX/Ultra这样的优异显卡,那么就可以尝试打开8xQ(就是8xMSAA)和16xQ(8xMSAA+额外的8份覆盖采样)这种高精度模式,从而获得非常好的画质。
● ATI HD 2000系列全新CFAA(Custom Filter,定制筛选)技术
ATI上代产品的确在AA方面占据了很大的优势,AA运算效能高,6xMSAA精度高(很多游戏可直接支持),但是单卡也只能止步于6xAA,双卡最高14xAA,离高清晰游戏的标准还很远。NVIDIA率先将AA精度提高至单卡16x、双卡32x,接近于CG级的画面品质,ATI在新一代产品上面显然不会示弱。
首先,R600也将色彩采样数目提高至8个,从而直接支持8xMSAA,与G80处在同一级别。这时可能有人会问,为什么NVIDIA和ATI不约而同的选择了8xMSAA,而不是直接提供更高的16xMSAA呢?原因在于传统MSAA如果采样16份色彩缓存的话,仅此一项的显存带宽消耗可达30GB/s以上,即便R600拥有100GB/s的显存带宽也将不堪重负(纹理缓存也要占用很多的带宽),效能十分低下。
在4xMSAA和8xMSAA的基础上,NVIDIA通过组合多倍覆盖采样提供了8xCSAA、16xCSAA两种效能模式和16xQAA这种高精度模式。而ATI则使用了更加灵活的可编程方案,除了保留以往的Adaptive SSAA/MSAA,Temporal AA,Super AA之外,还通过选择性的采样临近象素点,从而扩大采样精度,最高提供了24xCFAA,下面就来看看如此高倍AA是如何实现的。
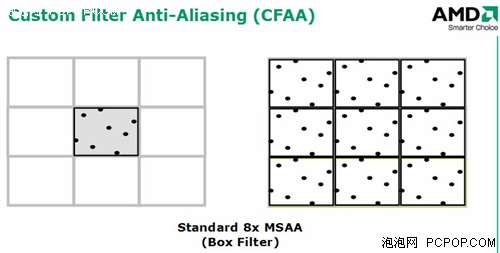
上图所示就是普通的8xMSAA,G80和R600都支持,很多游戏也能直接支持。其中每一个栅格就是一个像素,MSAA只在栅格类进行采样,8x就是8个像素点。
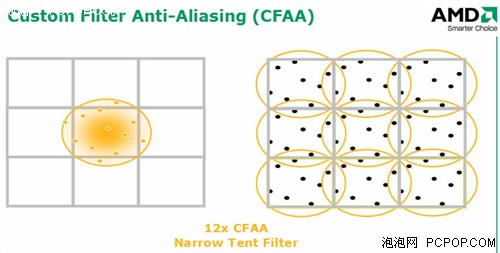
12xCFAA就是扩大了采样范围,并且小幅超出了栅格的范围,在栅格内8个象素的基础上将栅格外的4个象素纳入采样范畴,从而实现了12x精度。但是这种栅格外的象素可能会让结果模糊或者失真,因此在最后合成时栅格内外象素的权重值是不同的,距离栅格中心越远所占比重越小,ATI通过一些补偿算法消除了这个缺陷。
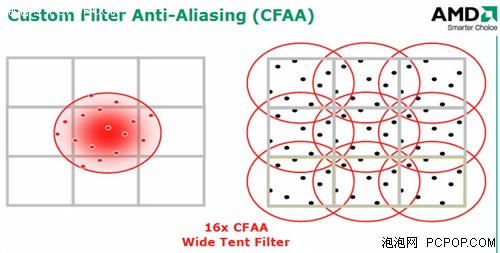
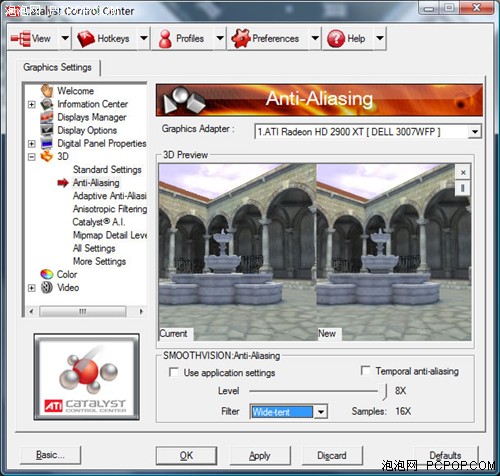 驱动AA选项特别丰富,8xMSAA+Wide-tent就是16xCFAA
驱动AA选项特别丰富,8xMSAA+Wide-tent就是16xCFAA 16xCFAA也是同样的道理,只不过采样范围更大,栅格内外各有8个象素被加入。如此一来每个象素的色彩值都可以被更加精确的计算出来,看上去资源消耗会非常大,而实际上由于大量的象素都是被重复利用的,因此显存带宽占用依然保持在8xMSAA的水平,而重复性的数据计算可以利用Stream Out技术大幅提高效率。
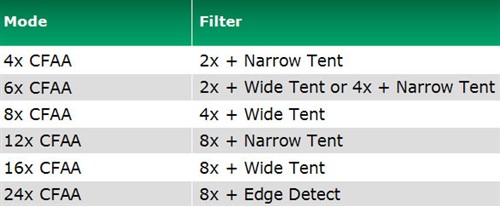
以上就是目前ATI在R600上所提供的6种CFAA模式,在2xMSAA、4xMSAA、8xMSAA的基础上进行小范围、大范围和超大范围栅格外采样合成。

0人已赞
第1页:完美DX10!ATI新王者HD2900XT权威评测第2页:完美DX10!ATI HD2000系列评测提纲第3页:2007显卡年!AMD/NVIDIA决战图形市场第4页:奋起直追!全新Radeon HD 2000产品线解析第5页:功能化发展!Radeon HD2000系列亮点逐个看第6页:第二章:统一渲染架构解析第7页:第二章/第二节:革命!R600的统一渲染架构第8页:4第9页:第三章:DirectX发展回顾以及DirectX10详细介绍第10页:第二节 DX10的架构特性 以及带来的好处第11页:第三章/第三节:ATI 3Dc功能回顾第12页:3第13页:3第14页:3第15页:3第16页:集众家之长,R600架构总览第17页:R600架构分块介绍第18页:Setup Engine(装配引擎)第19页:Ultra-Threaded Dispatch Processor(超线程分配处理器)第20页:Stream Processing Units(流处理器)第21页:R600的超标量SIMD架构第22页:4第23页:5第24页:ATI片内缓存相关技术第25页:Memory Control(显存控制器)第26页:第六章 R600的神工鬼斧——Tessellation技术第27页:第六章\\第二节 传统的虚拟3D技术回顾第28页:第二小节 凹凸贴图 Bump mapping第29页:第六章\\第二节\\第三小节 法线贴图(normal mapping)第30页:视差贴图技术parallax occlusion mapping第31页:位移贴图(displacement mapping)第32页:Ati的独门秘籍 Trumform 第33页:Tessellation技术第34页:神奇的小数点——细分网格算法中小数位的意义第35页:Tessellation效率的源泉——控制“笼子”第36页:Tessellation技术的流程第37页:Tessellation技术的应用和前景第38页:1第39页:AA发展第40页:CFAA第41页:123第42页:ATI显卡产品形象代言人——Ruby四度出击第43页:X800 & X850 Ruby第44页:DX9C的最高境界 X1800 Ruby第45页:R600 DX10 Ruby高清晰截图赏析第46页:R600 DX10 Ruby引擎和技术解析第47页:23第48页:R600 DX10 Ruby所用图形引擎揭秘第49页:1第50页:2第51页:第九章\\第二节第52页:庞大的运算资源,R600单卡就能物理加速第53页:3第54页:第四章:AMD高清视频功能解析第55页:22第56页:第三节 硬件视频加速第57页:第四节 UVD 引擎解码流程第58页:第五节 UVD测试第59页:第一节 电脑音频的数码之路第60页:第二节 HDMI数字音频技术背景第61页:第三节 各种显卡HDMI接口方案第62页:第四节 R600系列方案第63页:第五节:实战R600音频播放第64页:第六节 HD 2900XT怎么用?第65页:显卡介绍第66页:123123第67页:显卡介绍第68页:123第69页:显卡介绍第70页:3第71页:123123第72页:测试系统配置和设置第73页:阿苏大发送颠覆第74页:113123第75页:4第76页:05第77页:06第78页:游戏第79页:游戏第80页:123第81页:6第82页:6第83页:交火第84页:功耗测试第85页:1第86页:第二节 客观,公正,专业,全面,泡泡网为您带来最权威的DX10测试第87页:第三节 Call of Juarez游戏DX10测试 第88页:第四节 DirectX SDK测试(微软官方2007年四月版)第89页:第四小节:Draw Predicated第90页:第七小节:MotionBlur10第91页:第十小节:Skining 10第92页:第十四章 总结 另觅蓝海!AMD让ATI看得更远第93页:123
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}