

完美DX10!ATI新王者HD2900XT权威评测
●第二章 第二节:二次革命!R600的统一渲染架构
上面我们介绍了3D图形管线的整个工作过程,那么在这一节中我们将介绍R600的第二代统一渲染架构。
●第二章 第二节 第一小节:传统的显示芯片架构
我们已经在第一节中介绍了3D游戏的处理的全部过程,那么在为大家介绍R600的统一渲染架构之前,我们有必要先了解一下传统图形架构的相关知识。
如前一节所述,3D图形管线是一种顺序处理的过程,这种顺序执行的结构就像是一个管道一样,各种数据就像是管道里的水,不断留向下一级,所以人们也就根据这种特性为这种结构的处理单元起了一个更为形象的名字,这就是“管线”(Pipeline)的由来。
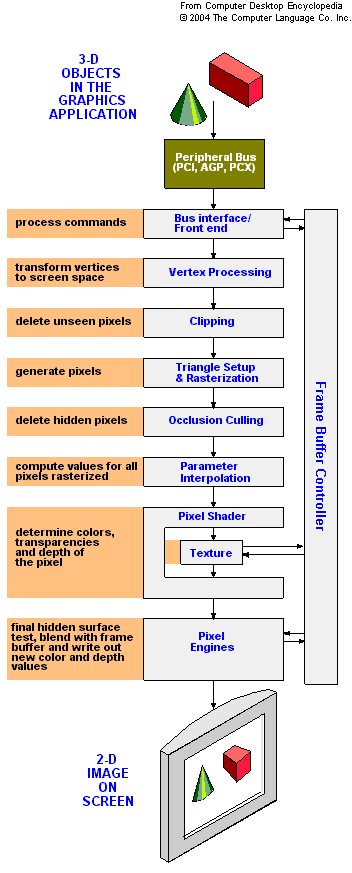
 传统3D管线
传统3D管线不过在目前的显示芯片中,管线通常有多种类型,比如像素渲染管线、顶点着色管线、像素着色管线。其中,像素渲染管线是一直存在于图形芯片中的,和三角形生成一样成为早期图形核心的标志性功能。目前像素渲染管线演变为ROP单元,也就是说对于目前的GPU,有几个ROP单元就相当与有几条像素渲染管线。
像素着色管线、顶点着色管线是从DirectX8开始被引入,具有可编程性。从此以后像素渲染管线逐渐退居到一个相对次要的地位,顶点着色管线、尤其是像素着色管线成为显卡的决定性因素。
● 第二章 第二节 第二小节,传统架构的劣势和不足
我们注意到,在之前的显示芯片设计的时候,显示芯片厂商在设计的时候并不会将顶点管线和象素管线按照相同的数目去做。而是将顶点管线相对放的少一些,多放一些象素渲染管线。
那么显示芯片厂商为什么要这么做呢?答案是:这样的结构和比例是芯片设计厂商根据常见游戏的情况而决定的。
不同的游戏在开发的过程中,设计的游戏复杂度是不同的,有的游戏就非常简单,3D模型也相对简单,这样游戏就可以在更多的玩家的电脑上运行。有的游戏的3D模型和后期特效就非常复杂,这样在保证了游戏的效果的同时就让很多配置不是那么好的玩家无法运行或者运行起来特别慢。
除去游戏复杂度的区别,游戏的开发商和显示芯片厂商还处在一个更加难以解决的怪圈中,这就是,游戏开发商无法在游戏的资源消耗定向上达成一致,所以带给了显示芯片厂商很大的麻烦。
具体来说就是,有的厂商会开发一些3D模型很复杂,顶点数目很多的游戏,这些游戏就需要耗费很大的顶点渲染管线的资源,这类游戏可以把通常场景很复杂,里面的3D模型的细节非常到位。而另一类厂商则会将焦点放在后期的象素级别的特效,这样的好处就是可以给游戏带来更炫的视觉效果。
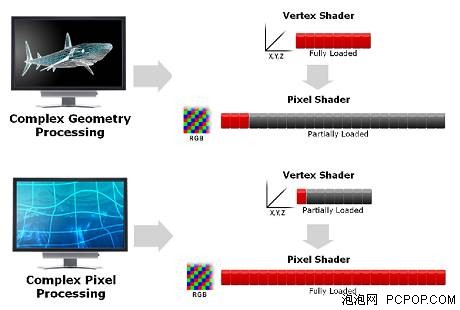
Vertex Shader、Pixel Shader负载不均衡
举例来说,上图可以看到一个典型的例子,第一场景(鲨鱼)主要是由框架以及三角形来构成的,因此对于Vertex Shader的计算量是相当高的,而Pixel Shader计算的部分却非常少,Pixel Shader的管线资源被闲置。
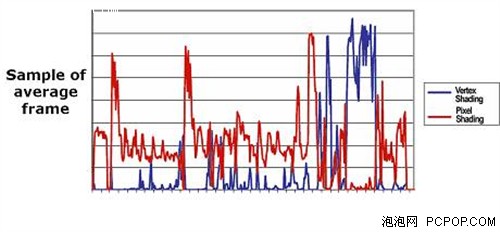 实际中的Vertex Shader、Pixel Shader负载
实际中的Vertex Shader、Pixel Shader负载而第二个例子描绘的是一个复杂水体模拟场景,是由大量的光影特效都是依靠像素处理实现的,因此对于Pixel Shader单元的要求却非常高,而Vertex Shader的操作早已完成,导致了资源的浪费。这两个例子充分的证明了这样一个事实,大部分的应用中,Vertex Shader和Pixel Shader处理不平衡的现象非常普遍,导致部分Shader单元闲置,从而浪费宝贵的资源。这也正式Shader单元分离式设计显示卡的最大弊端之一。
在这种情况下,显示芯片厂商只能按照最常见的游戏的情况来设计显示芯片,尽最大能力去满足不同的游戏。
而游戏厂商在设计游戏的时候也不能随心所欲的设计游戏,必须满足显示芯片的性能配比,这样才能在消耗性能最小的情况下达到最好的游戏效果。
这个矛盾一天不得到解决,显示芯片最大的效能就不能充分的得到发挥,这也一直是显示芯片的性能提高的最大瓶颈所在,在这样的架构上,不断的加“管线”,提高频率是显示芯片厂商唯一能作的事情。
传统显示芯片架构的缺点
1 游戏厂商无法按照需要设计游戏,必须向硬件性能妥协。
2 显示芯片的利用效率不高,运算单元被闲置的现象经常发生。
统一渲染架构的优点
1.动态分配运算单元,提升利用率
在这样的统一渲染架构下,每个处理单元都可以进行Vertex Shader的运算和Pixel Shader的运算,这样一来,无论是怎样的游戏,都能够充分利用显卡的资源,再也不会有一些处理单元闲置,一些处理单元负载过高的情况出现了。
在需要大量顶点运算的游戏中, Unified Shader将被分配去做顶点的运算,而在需要大量后期象素级别特效的时候, Unified Shader将被安排去做Pixel Shader的事情。
2.并行处理,提高利用效率
除了动态分配方面带来的好处,这样的结构还有利于处理并行性的提升,因为这些处理单元可以并行运行,不像原来的串行的结构那样顺序执行。




{kind=link}
{kind=link}
{kind=link}
{kind=link}