

最高提升115% 英特尔45nm Penryn实测
● Intel 45nm处理器大军Penryn铁定本年第四季上阵

2006年下半年,Intel正式发布新一代「Core」微架构,取代面市5年、疲态毕露的「Netburst」微架构,成功令Intel谷底回春,重新站上x86处理器产品领导地位,而为保持此一优势,Intel同时也宣布全新「规则律动」「Tick-Tock」硅与微架构发展战略,于每年推出新处理器技术时,皆具备改良的微架构或是全新设计微架构,以迎合未来十年甚至更远的处理器市场。
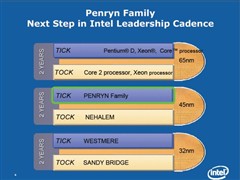
每个「Tick」代表推出具有增强微架构的新一代硅制程技术,与相对的「Tock」代表推出全新微架构,而每个「Tick-Tock」周期大约为2年。
因此按照既定规划,「Conroe」面市1年后,Intel 亦正计划推出代号为「Penryn 」的下一代 Core 2 处理器家族。Penryn 家族将基于全新45nmHigh-K金属闸极 (high-k metal gate) 技术,及经改良的微架构设计,是最近一次的「Tick」,达成 Intel目标每年推出具增强微架构或全新微架构处理器产品的承诺。
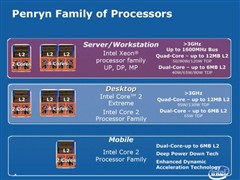
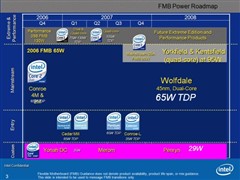
全新45nmPenryn家族共有7名成员,包括双核心桌面处理器Wolfdate、四核心桌面处理器Yorkfield、双核心行动处理器 Penryn、双核心Xeon DP处理器 Wolfdate DP、四核心 Xeon DP处理器Harpertown、双核心 Xeon MP处理器Dunnington DC及四核心Xeon MP处理器Dunnington QC。
Penryn双核心版本内建 4.1 亿个晶体管,四核心则有8.2亿个晶体管,微架构经强化后,在相同频率下较上代Core产品拥有更高性能,同时L 2 Cache容量亦提升50%,明显提高数据读取执行的命中率。此外,亦加入47条全新Intel SSE4指令,提高媒体性能和实现高性能运算应用。
● 2008年Nehalem、2009年Westm
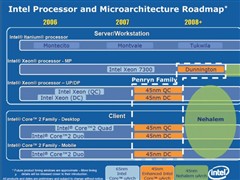
根据Intel最新处理器规划,首颗45nm桌面处理器将会是四核心Yorkfield,预定2007年第四季正式面市,紧接着登场的则是桌面双核心Wolfdate,预计2008年上半年,45nm处理器出货将占整体桌面产品比重约3成份额。
笔记本处理器方面,45nm核心Penryn将于2008年第一季上阵,首季出货比重将占整体NB处理器产品逾2成,而在第二季推出全新Centrino平台Montevina后, 45nm处理器比重将会超过5成,迅速完成世代交替。
另在服务器布局计划方面,Xeon DP四核心Harpertown将于2007年第四季与桌面四核心同步登场,Xeon DP双核心Wolfdale-DP则晚一季,与桌面双核心Wolfdate同时于2008年首季发表,而Xeon MP双核心Dunnington-DC及四核心Dunnington-QC,则规划于2008年下半年现身。
2008年即将登场的下一代「Tock」全新微架构,产品代号为「Nehalem」,加入动态管理内核设计,类似对手AMD的Interconnect及Crossbar设计,支持1至16个线程和1至8个内核的可伸缩架构,并支持集成内存控制器。
「Nehalem」将再次加入经改良的Hyper-Threading技术,性能和效能表现显著强化,新增SSE 4.2指令集及ATA指令集令系统性能全面提升。值得注意的是,「Nehalem」预留集成高效能绘图核心的架构,与对手AMD Fusion处理器的CPU-GPU架构极为类似,不让对手专美于前。
接着「Nehalem」之后登场的是「Westmere」家族,其采用全新Tri-gate晶体管、High-K物料及Strained Silicon技术,代号为P1268的32nm制程,2010年将会再推出全新微架构的32nm处理器「Sandy Bridge」。
为令「Tick-Tock」硅与微架构发展战略成功延续,新微架构将由不同团队同步研发,力促未来不同世代的制程技术平台转换顺畅,Intel执行长Paul Otellini极具信心表示,Intel可望在2010年前,让每瓦效能(performance per watt)比现今处理器增加高达300%,不仅持续精进功耗与效能表现,同时亦会不断研发与制造崭新产品,许多令人振奋的全新功能将会是市场焦点所在 。
● 全新45nm High-K金属栅极技术 能效表现再提高
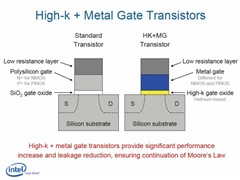
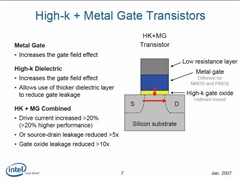
由于深知漏电问题将会阻碍芯片和个人计算机的设计、大小、耗电量、噪声与成本开发,因此,新一代Penryn处理器家族将采用全新材料制作的45nm晶体管绝缘层(insulating wall)和开关闸极 (switching gate),减低晶体管漏电(electrical leakage)情况。
为能达到大幅降低漏电情形且可同时提升效能目标,Intel采用被称为High-k的新材料制作晶体管闸极电介质(transistor gate dielectric),而晶体管闸极的电极 (transistor gate electrode)也将搭配采用全新金属材料组合,增加驱动电流20%以上,不仅提升晶体管效能,同时源极 - 汲极 (source-drain) 漏电也可减少逾5倍,明显改善晶体管耗电量。
据了解,由于二氧化硅具有易制性 (manufacturability),且能减少厚度以持续改善晶体管效能,因此过去40余年来,业者主要均采用二氧化硅做为制作闸极电介质的材料。
虽然Intel于导入65nm制程时,已全力将二氧化硅闸极电介质厚度降低至1.2nm,相当于5层原子,但由于晶体管缩至原子大小的尺寸时,耗电和散热亦会同时增加,产生电流浪费和不必要的热能,因此若继续采用目前材料,进一步减少厚度,闸极电介质的漏电情况势将会明显攀升,令缩小晶体管技术遭遇极限。
为解决此关键问题,Intel正规划改用较厚的High-k材料(铪hafnium元素为基础的物质)作为闸极电介质,取代沿用至今已超过40年的二氧化硅,此举也成功令漏电量降低10倍以上。
由于High-k闸极电介质和现有硅闸极并不兼容,Intel全新45nm晶体管设计也必须开发新金属闸极材料,目前新金属的细节仍属商业机密,Intel现阶段尚未说明其金属材料的组合。
另与上一代技术相较,Intel的45奈制程令晶体管密度提升近2倍,得以增加处理器的晶体管总数或缩小处理器体积,令产品较对手更具竞争力,此外,晶体管开关动作所需电力更低,耗电量减少近30%,内部连接线 (interconnects) 采用铜线搭配 low-k电介质,顺利提升效能并降低耗电量,开关动作速度约加快 20%。
值得注意的是,Intel成功令新一代 45 nm制程产品的漏电情况降低逾5倍,其中晶体管闸极氧化物漏电量更降低超过10倍,相较上代65nm制程产品,在同一功耗表现下,频率下可提升约20%,或是在同一频率下功耗更低,电池续航力也明显大幅提升。
另一方面,Intel使用创新设计法则和先进光罩技术,将193nm干式微影技术 (dry lithography) 延伸应用在45nm处理器上,全力发挥成本优势和高易制性。
● 全新焊钖合金技术 Penryn 将采用无铅生产


为积极朝全球环境永续发展而努力,Intel 也宣布自采用新一代high-k金属闸极 (high-k metal gate)的45nm制程开始,未来Intel处理器将会采用100%无铅设计。
据Intel副总裁、技术与制造事业群组装测试技术开发总监Nasser Grayeli表示, Intel正积极朝协助环境永续发展而努力,包含全面采用无铅制程、重视产品能源效率运用、减少废气排放,以及大规模回收再利用水资源与制造材料等。
数十年以来,由于铅具备适当的电气和机械特性,因此广泛应用在电子零组件等产品中,但近年来研究发现,铅制产品已严重影响全球生态环境和公众健康,因此包括全球各大业者皆全力寻找能满足效能和可靠性需求的铅替代材料。
以Intel为例,多年来在与供货商和其它半导体及电子零组件公司合作下,已陆续开发无铅解决方案,2002年,Intel推出了第一个采无铅方式制造的无铅闪存产品,自2004年起,英特尔出货产品含铅量已较前一代微处理器和芯片组封装大幅减少95%。
Intel针对以往仍存于处理器封装之内部连接点(interconnect)第一层内之5% (约 0.02公克)的含铅焊锡(lead solder),焊点用来连接硅晶粒和封装基板,Intel 将以锡、银、铜合金 (tin/silver/copper alloy) 取代以铅/锡为主的焊锡。由于 Intel 先进硅晶技术含有复杂的连接结构,必须投入大量的工程资源,才能使 Intel 处理器封装完全不使用铅,并推动整合新的焊锡合金系统。
无论是采用何种封装设计,包括PGA (pin grid array)、BGA (ball grid array)和LGA (land grid array)等方式,Intel已确定45nmHi-k技术均将100%使用无铅设计,另外,2008年采用65nm制程生产的芯片组产品亦会全面改采100%无铅技术。
根据Intel最新制程发展蓝图,2007年将会推出代号为P1266的45nm制程,持续朝每2年更新制程一次的速度前进,2009年会推出代号为P1268的32nm制程,2011年将推出P1270的22 nm制程。
现时,Intel 计划以3座晶圆厂生产45nm产品,位于美国奥勒岗洲 (Oregon, USA)的D1D晶圆厂及美国亚利桑那洲 (Arizona, USA)的Fab32晶圆厂,将率先于2007年下半年导入45nm制程,而以色列(Israel)的Fab 28则预定于2008年上半年投入45nm生产行列。
<
● 技术研讨:45nm究竟有多小?

晶体管之父「William Shockley」
自1947年晶体管发明迄今,科技进步的速度惊人,催生了功能更为先进强大,又能兼顾成本效益和耗电量的产品。虽然科技进展迅速,但晶体管产生的废热和漏电,仍是缩小设计及延续摩尔定律 (Moore '' s Law) 的最大障碍,因此业界必须以新材料取代过去 40 年来制作晶体管的材料。
翻查晶体管历史,2007年正好是晶体管诞生60周年,首颗晶体管出现于1947年12月16日,贝尔实验室 (Bell Labs)的William Shockley、John Bardeen和Walter Brattain成功制作第一个晶体管,改变了人类的历史。到了1950年,William Shockley开发出双极性接面晶体管(bipolar junction transistor),也就是现时俗称的晶体管。
首款采用晶体管技术且商业化的装置于1953年上市,但却是一款助听器。1954 年10月18日,第一台晶体管收音机Regency TR1问世,采用4颗锗晶体管。虽然一开始晶体管设计已足以应付收音机和电话产品需求,但为令新型电子设备更加细小,集成电路技术开始发展并广泛应用,直至1961年4月25日,Intel创办人之一Robert Noyce,取得首件集成电路专利。
1965年,Intel 创办人之一Gordon Moore于电子杂志 (Electronics Magazine)撰文预测,未来芯片上的晶体管数目约每年倍增速度成长,之后10年改为每2年倍增,摩尔定律就此正式诞生。
1968年7月,Robert Noyce和Gordon Moore自快捷半导体 (Fairchild Semiconductor)公司离职,创立Intel公司。Intel是由积体电子 (integrated electronics)缩写而成。
Intel成立后一直在晶体管技术拥有领先地位,1969 ,率先成功开发PMOS硅闸极晶体管技术,除传统的二氧化硅(SiO2)闸极电介质 (gate dielectric) 外,也引进新多晶硅(polysilicon)闸极技术。1971年,Intel推出首个微处理器4004,1/8 x 1/16 英吋大小内含2,000余颗晶体管,以10微米(micron) PMOS技术制成。
1978年,16位的Intel 8088微处理器诞生,内含29,000颗晶体管,执行速度为5MHz、8MHz和10MH;8088于1981年成功获得IBM新个人计算机部门采用,此项关键性交易除令Intel 8088微处理器成为IBM个人计算机 (IBM PC)的头脑外, Intel也跻身成为财星杂志Fortune 500大公司之一及 1970年代商业成功典范之一, PC历史亦由这一刻开始。
由于nm不像厘米和毫米,肉眼即可来量度察看,多数人对于nm可能没有概念,其实1米约相为10亿nm,相比1947年贝尔实验室 (Bell Labs) 第一颗晶体管大到可以握在手中,而数百颗 45 nm晶体管加起来,才相等于1个红血球细胞的表面积那么丁点大,可想而知这60年来电晶体技术的进步十分神速。
如果日常用品以nm作为直径量度单位,小钉子约等于2千万nm,3 万余颗 45 nm晶体管加起来只有针头大小,约为 150 万nm左右。1 人类毛发约等于9万nm,2 千多颗 45 nm晶体管加起来才相当于人类一根毛发的宽度,连看不到的细菌,原来它的直径也有2,000nm,因此,肉眼要看到45nm晶体管,必须需要非常先进的显微镜工具才能达成。

Bell实验室开发的双极性接面晶体管 (bipolar junction transistor)模型
由于科技日渐普及,Intel下一代Penryn 理器中,每颗晶体管的平均价格约只有 1968年每颗晶体管价格的百万分之一,如果汽车降价也这么快速,现在的1辆汽车要价可能只需1美分。此外,1颗45nm晶体管每秒可开关约3千亿次,在1颗45nm晶体管开关1次的期间内,光线行经的距离还不到1/ 10英吋。 <
● Penryn :新增47条SSE4指令


自Intel Pentium MMX 处理器开始,处理器新增SIMD(Single Instruction Multiple Data)多媒体指令集,可把多个批次性的指令组变成单一指令,以提升数据处理能力,后来Intel基于MMX指令发展出SSE(Streaming SIMD Extensions)指令集,直至Penryn处理器已发展至SSE4指令集。
MMX:1997年发布,全名为 MultiMedia eXtension,首颗支持MMX产品为 Pentium MMX 处理器,主要用作提升多媒体数据的处理能力,共有57条指令。
SSE:1999 年发布,全名为 Streaming SIMD Extensions,首颗支持SSE产品为 Pentium III处理器,除新增70条指令,进一步提升多媒体数据的处理能力,最重要的是解决了MMX指令与浮点指令不能同时处理的问题。
SSE2 :2001年发布,全名为Streaming SIMD Extensions 2,首颗支持SSE2产品为Pentium 4处理器,新增指令共144条,主要加入 64 位双精度浮点数及整型运算指令,以及加入处理器对Cache的控制指令以减低延迟,更重要的是完全解决SSE集指令需要占用浮点数据缓存器问题。
SSE3 :2004年发布,全名为Streaming SIMD Extensions 3,首颗支持的处理器为 Prescott核心的Pentium 4处理器,新增指令仅13条,主要特点是加入水平式缓存器整数运算,可对多笔数值同时进行加法或减法运算,令处理器能大量执行 DSP及3D性质的运算。浮点数数值转换成整数数值而不需要进行运算模式切换,避免模式切换时导致其它执行绪被延误,减损系统运算效能。
此外,SSE3 更针对多执行绪的应用程序进行执行非常好的化,使处理器原有的 Hyper-Theading 功能获得更佳的发挥。
SSE3指令集的补充版本,全名为 Supplemental Streaming SIMD Extension 3,首颗支持Intel Core微架构处理器,新增指令共16条,进一步增强 CPU在多媒体、图形图像和Internet等方面的处理能力,该16条指令原收录为 SSE4指令集中,之后决定提早加入至Core微架构产品中。
SSE4 :全名为Streaming SIMD Extension 4,被视为继2001年以来最重要的媒体指令集架构的改进,除扩展Intel 64指令集架构外,还加入有关图形、视频编码及处理、三维成像及游戏应用等指令,令涉及音频、图像和数据压缩算法的应用程序大幅受益。
据了解,SSE4将分为4.1版本及4.2版本,4.1版本将会首次出现于Penryn处理器中,共新增47条指令,主要针对向量绘图运算、3D游戏加速、视像编码加速及协同处理加速动作,包括:
Penryn SSE4 Instruction summary | ||
Instruction Category | Instructions | Benefits |
Packed DWORD Multiplies | PMULLD, PMULDQ | 提升编译器矢量运算效能 |
Floating Point Dot Product | DPPS, DPPD | 3D立体制作及游戏,支持CG及HLSL等语言 |
Multi-packed sum of absolute diffs& min pos | MPSADBW, PHMINPOSUW | 视频编码处理 |
Streaming Load | MOVNTDQA | 视频编码处理、绘图及GPU数据分享 |
Floating Point Round | ROUNDPS, ROUNDSS, ROUNDPD, ROUNDSD | 视频编码处理 、绘图、影音处理、2D/3D应用、多媒体及游戏等 |
Packed Blending | BLENDPS, BLENDPD, BLENDVPS, BLENDVPD, PBLENDVB, PBLENDDW | 编译器矢量运算及影音处理、多媒体、游戏等应用 |
Packed Integer Min and Max | PMINSB, PMAXSB, PMINUW, PMAXUW, PMINUD, PMAXUD, PMINDS, PMAXSD | |
Register Insertion/Extraction | INSERTPS, PINSRB, PINSRD, PINSRQ, EXTRACTPS, PEXTRB, PEXTRD, PEXTRW, PEXTRQ | |
Packed Format Conversion | PMOVSXBW, PMOVZXBW, PMOVSXBD, PMOVZXBD, PMOVSXBQ, PMOVZXBQ, PMOVSXWD, PMOVZXWD, PMOVSXWQ, PMOVZXWQ, PMOVSXDQ, PMOVZXDQ | |
Packed Test & Set | PTEST | |
Packed Compare for Equal | PCMPEQQ | |
Pack DWORD to Unsigned WORD | PACKUSDW | |
● SSE4 :向量、浮点运算专门化 加入串流式负载指令
据Intel指出,在应用SSE4指令集后,Penryn增加了2个不同的32Bit向量整数乘法运算支持,引入了8 位无符号 (Unsigned)最小值及最大值运算,以及16Bit 及32Bit 有符号 (Signed) 及无符号运算,并有效地改善编译器效率及提高向量化整数及单精度代码的运算能力。同时,SSE4 改良插入、提取、寻找、离散、跨步负载及存储等动作,令向量运算进一步专门化。
SSE4加入了6条浮点型点积运算指令,支持单精度、双精度浮点运算及浮点产生操作,且IEEE 754指令 (Nearest, -Inf, +Inf, and Truncate) 可立即转换其路径模式,大大减少延误,这些改变将对游戏及 3D 内容制作应用有重要意义。
此外,SSE4加入串流式负载指令,可提高以图形帧缓冲区的读取数据频宽,理论上可获取完整的快取缓存行,即每次读取64Bit而非8Bit,并可保持在临时缓冲区内,让指令最多可带来8倍的读取频宽效能提升,对于视讯处理、成像以及图形处理器与中央处理器之间的共享数据应用,有着明显的效能提升。<
● Penryn :SSE4指令集强化视讯编码效率
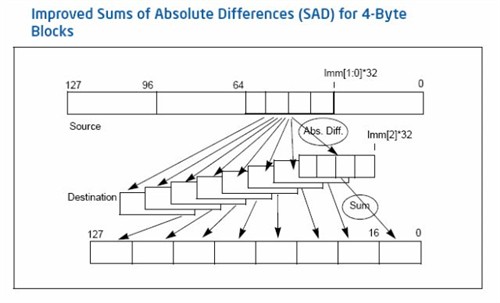
SSE4指令集进一步强讯编码效果,例如可同时处理8个4-byte宽度的SAD(Sums of Absolute Differences)运算,常用于新一代高清影像编码如VC.1及H.264等规格中,令视频编码速度进一步提升。
据了解,在进行视讯编码时需要进行动态预测(Motion Estimation)及差分编码方式去除相邻2张影像之相关性,这是一个非常复杂的运算动作,在没有SSE4指令集时,以上工作所需指令如下:
for (int moveblock=0;moveblock<16;moveblock++)
for(int line=0; line<16; line++) // Does the 16 pixels large in 4 iteration
{
int i=0;
sum0+=abs( pBlock1[j]-pBlock2[i])+abs(pBlock1[j+1]-pBlock2[i+1])+abs(pBlock1[j+2]-pBlock2[i+2])+abs(pBlock1[j+3]-pBlock2[i+3]); // Compare with 0 pixel offset
sum1+=abs(pBlock1[j+1]-pBlock2[i])+abs(pBlock1[j+2]-pBlock2[i+1])+abs(pBlock1[j+3]-pBlock2[i+2])+abs(pBlock1[j+4]-pBlock2[i+3]); // Compare with 1 pixel offset
sum2+=abs(pBlock1[j+2]-pBlock2[i])+abs(pBlock1[j+3]-pBlock2[i+1])+abs(pBlock1[j+4]-pBlock2[i+2])+abs(pBlock1[j+5]-pBlock2[i+3]); // Compare with 2 pixel offset
sum3+=abs(pBlock1[j+3]-pBlock2[i])+abs(pBlock1[j+4]-pBlock2[i+1])+abs(pBlock1[j+5]-pBlock2[i+2])+abs(pBlock1[j+6]-pBlock2[i+3]); // Compare with 3 pixel offset
sum4+=abs(pBlock1[j+4]-pBlock2[i])+abs(pBlock1[j+5]-pBlock2[i+1])+abs(pBlock1[j+6]-pBlock2[i+2])+abs(pBlock1[j+7]-pBlock2[i+3]); // Compare with 4 pixel offset
sum5+=abs(pBlock1[j+5]-pBlock2[i])+abs(pBlock1[j+6]-pBlock2[i+1])+abs(pBlock1[j+7]-pBlock2[i+2])+abs(pBlock1[j+8]-pBlock2[i+3]); // Compare with 5 pixel offset
sum6+=abs(pBlock1[j+6]-pBlock2[i])+abs(pBlock1[j+7]-pBlock2[i+1])+abs(pBlock1[j+8]-pBlock2[i+2])+abs(pBlock1[j+9]-pBlock2[i+3]); // Compare with 6 pixel offset
sum7+=abs(pBlock1[j+7]-pBlock2[i])+abs(pBlock1[j+8]-pBlock2[i+1])+abs(pBlock1[j+9]-pBlock2[i+2])+abs(pBlock1[j+10]-pBlock2[i+3]); // Compare with 7 pixel offset
i=4;
j=moveblock+4;
…
… }
}
一大串的运算动作包括了ABS、Subtracion及Addition等,极度浪费处理器资源,但当处理器支持SSE4指令集,只需要采用4 SAD运算指令:
MPSADBW xmm0,xmm1,0
可以完全代替了以上繁复的指令串,大幅提升动态预测(Motion Estimation)及差分编码的运算速度。
除此之外,视讯编码需要寻找非常好的的SAD(Sums of Absolute Differences),由于旧有处理器只支持垂直寻找,十分浪费处理器资源,令视讯编码工作变得冗长,在没有SSE4指令集时,以上工作所需指令如下:
if (ret
ret=sum1;
best_mv->x=mv.x;
best_mv->y=mv.y+line;
}
if (ret
{
ret=sum1;
best_mv->x=mv.x+1;
best_mv->y=mv.y+line;
}
if (ret
{
ret=sum2;
best_mv->x=mv.x+2;
best_mv->y=mv.y+line;
}
if (ret
{
ret=sum3;
best_mv->x=mv.x+3;
best_mv->y=mv.y+line;
}
if (ret
{
ret=sum4;
best_mv->x=mv.x+4;
best_mv->y=mv.y+line;
}
if (ret
{
ret=sum5;
best_mv->x=mv.x+5;
best_mv->y=mv.y+line;
}
if (ret
{
ret=sum6;
best_mv->x=mv.x+6;
best_mv->y=mv.y+line;
}
if (ret
{
ret=sum7;
best_mv->x=mv.x+7;
best_mv->y=mv.y+line;
}
当软件支持SSE4指令集,以上复杂的指令组却只需要1条水平式搜查指令便可完成:
Phminposuw xmm7,xmm7
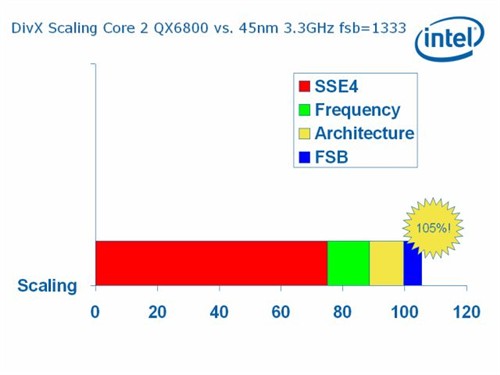
据 Intel 资深工程师兼 Penryn 微架构主管 Stephen Fischer 表示,全新 DivX Alaph 内部测试版本已完全支持 SSE4 指令集,1 颗 3.33G Hz 的 Yorkfield 的运算效能,相比上代 Intel Core 2 Duo QX6800 快约 105% ,其中约 7 成的增益来自 SSE4 指令集,效果令人满意。
● Penryn :基于Core 微架构再作改良
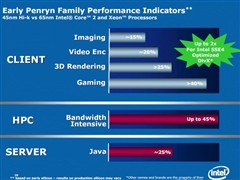

除了采用更先进的45奈米制程及加入全新 SSE4 指令集外,Penryn 亦基于Intel Core微架构设计作出多项改良,称为「Enhanced Intel Core Microarchitecture」,并加入了:
Fast Radix-16 Divider(快速 Radix-16 除法器)
Super Shuffle Engine(超级洗牌引擎)
Split Load Cache Enhancement(增强型缓存拆分负载)
Improved Store Forwarding(存储转发)
Faster OS Primitive Support(高速操作系统同步原始支持)
Virtualization Performance Improvements (增强的Intel 虚拟化技术)
Deep Power Down Technology(深度节能技术)
Enhanced Dynamic Acceleration Technology(增强型动态加速技术)
据Intel资深工程师兼Penryn微架构主管Stephen Fischer表示,与上代处理器产品相比,Penryn处理器在绘图效能约超过15%、视讯编码平均可提高20%、3D内容制作可提高逾30%,3D游戏效能更可高达40%,视乎软件设计而定。
◎ Enhanced Core MA :Fast Radix-16 Divider
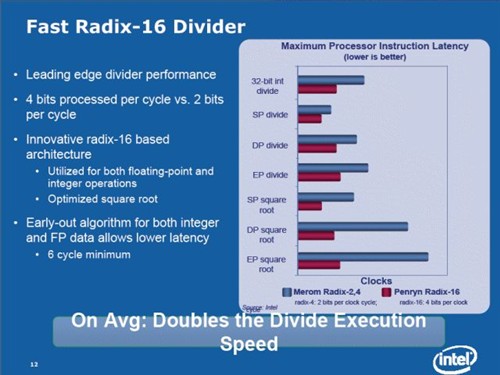
Intel在Core微架构中支持每个周期可处理多达4个指令(对比旧有处理器最多只能同时处理3个指令),且重新采用较高效率的14层Pipeline Stages,为提升分支预测的能力及准确性,Branch Predictor的Bandwitdh提升至20Byte (K8、Banias 为16B,Netburst为4B),令指令执行效率大大提高。
此外,Core微架构更加入Macro-Fusion技术,可把部份指令组合成单一Micro-Op 指令,令特定情况下每个周期可执行5个指令,更保留Micro-op Fusion技术,把相同的Macro-ops混合成单一个Micro-ops 透过Out-of-order逻辑可减少10% 的Micro-op指令执行数,除提升核心的执行效率,同时也保持高能源效益。
Penryn处理器除沿袭Core微架构的优点外,并进一步改良除法器的设计,在科学计算、三维坐标转换和其它数学运算密集型功能中,其带来约2倍的除法器速度,所包含的新一代的快速除法技术称为 Radix-16,可加速浮点和整数的除法运算速度。
据了解,基数为4的算法会在每次迭代运算中计算其2位的商值,当提高到基数为16的算法时,则允许在每次迭代中计算4位的商值,进而使延迟缩减一半。
◎ Enhanced Core MA :Super Shuffle Engine

Intel在 Core微架构中加入128Bit-SIMD interger arithmetic及128bit SIMD双倍精准度Floating-Point Operations单元。旧有的处理器执行128Bit的SSE、SSE2及SSE3指令时,需要把指令分拆为2个64Bit指令,在2个频率周期完成,但Core微架构则只需要1个频率周期便能完成,执行效率提升达1倍,现时SSE指令集已普遍使用于主流软件中,包括绘图、影像、音效、加密、数学运算等用途,单周期128Bit处理器能力利用频率以外的方法提升效能。
另一方面,Penryn处理器也有显著改良,其加入全新Super Shuffle Engine,令SSE 指令运算更具效率,以往处理Unpacking、Packing、Align Concatenated Sources、Wide Shifts、Insertion及Horizontal Arithmetic Functions Setup等128Bit宽度的字节、字及Dword SSE数据时,均无法在单一周期内完成,但Super Shuffle Engine设计除可让这些不同性质的128Bit SSE指令,在1个周期内便可完成,减低延迟及吞吐量外,更不用在软件端中作出改良即可实现。
◎ Enhanced Core MA :Split Load Cache Enhancement

Intel Core微架构明显强化处理器的Cache架构,传统的双核心设计中,每个独立的核心都有自己的L2 Cache,但Intel Core微架构则是透过核心内部的Shared Bus Router共享相同的L2 Cache,当CPU 1运算完毕后把结果存在L2 Cache时, CPU 0便可透过Shared Bus Router读取CPU 1放在共享L2 Cache上的数据,大幅减低读取上的延迟并减少使用 FSB 频宽。同时加入L2 & DCU Data Pre-fetchers及Deeper Write output缓冲存储器,大幅增加Cach 的命中率。
Shared Bus Router 除更有效处理L2 Cache读取外,亦为双核心使用FSB传输进行排程,新加入的Bandwidth Adaptation机制改善了双核心共享FSB时的效率,减少不必要的延迟。
Penryn处理器的L2 Cach 容量增加了50%,双核心产品L2 Cach 容量最大可达至6MB、四核心更可高达12MB,并提升至24路联合(24-way set Associative) ,令L2 Cache命中率进一步提升,并大幅度提升使用率。
此外,亦加入全新增强高速缓存行拆分负载功能(Split Load Cache Enhancement),当读取数值时,若数据位于2个不同的高速缓存中,则会对负载行进行拆分。即便单个高速缓存行中的数据未经过适当调整,而自单个高速缓存行中读取数据,亦较自2个高速缓存行中读取数据快上数倍。
◎ Enhanced Core MA :Improved Store Forwarding
据了解,Penryn能在通过其它负载或存储之前作出推测,并快速分派两部份拆分负载,大大提高读取性能,可拉升执行数据扫描的应用程序的效率,例如视讯动态评估等工作。
Intel Core微架构加入了Memory Disambiguation设计,透过Out of Order过程分析内存读取次序,分析数据是否独立读取执行,如果与前面的数据存取动作并无关系,可令其提早执行,降低处理器的等候时间,减少闲置及延迟值。
另外,也进一步改内存系统效能,加速超过8bit的地址边界、令处于管线中的杂乱存储结果的读取速度,可立即向负载中的数据转发存储结果,且毋须等待存储完成再写入内存内。
◎ Enhanced Core MA :Faster OS Primitive Support
在启动某一个关键代码段、并要以独占的方式访问某一个资源时(例如系列内的 I/O设备) ,某些操作系统会临时阻止或屏敝中断,因此Penryn加入高速操作系统同步原始支持(Faster OS Primitive Support),能更快速清除中断、设置中断功能 (CLI/STI),迅速进入及退出此一模式,进而显著提高执行此类代码段的性能。
Penryn处理器可以更快速地执行锁定的指令,例如XCHG、ADD/XADD/NEG/BTS/AND及CMPXCHG,且可更快速访问时间戳数器 (RDTSC),以上这些功能常用于数据库或事务处理的服务器。
◎ Enhanced Core MA :Virtualization Performance Improvements
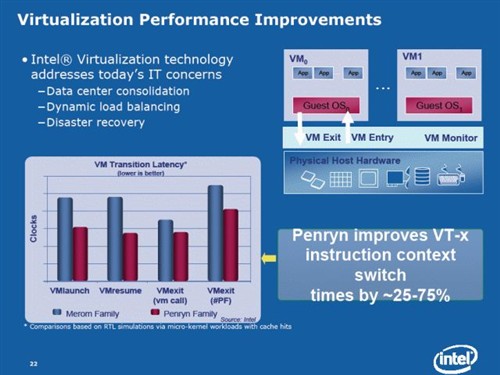
Penryn处理器在VT (Virtualization Technology)技术上进行显著改良,其支持EPT 延伸分页,并改良VT-x指令对虚拟主机转换、进入及退出的速度,平均可提升25%至75%,且只需要通过微架构上的改良,不用更改任何虚拟主机软件设计。
◎ Enhanced Core MA :Deep Power Down Technology

Penryn行动处理器加入全新高级电源管理状态(C-Status ,可显著降低闲置期间处理器的功耗,并有效防止晶体管漏电情况。
而此最新的处理器睡眠状态称为C-6 (Deep Power Down),处理器可实时清除L1 Cache内所有数据,在保存处理器微架构状态下,关掉内核(Core Clock 与 PPL 将停止 )及L2 Cache,虽然芯片组会继续为I/O提供内存交换动作,但却不会唤醒处理器。
只有需要内核时,电压才会攀升,Core Clock与 PPL 会打开,处理器将进行重置,把Cache数据从内存中回传,微架构状态将完全恢复,并继续执行指令。
据Intel指出,C6 (Deep Power Down)模式将会是DC4 (Enhanced Deeper Sleep)模式,电压再降低一半,且L 1 C ache也会进入关闭状态,处理器功耗更进一步减少逾75%,但返回活跃状态所需时间则比DC4多出约50%。
由于C-Status越深,进入该状态和返回活跃状态的能源损耗也会越高,时间亦较长,过于频繁地切换至深度C-Status会造成更大的能耗,因此,新一代Penryn处理器加入自身降级功能,该功能采用智能试探法,可确定闲置期间的节省,能否补偿关闭处理器后再重新恢复所需要的能耗成本。
如果不能,处理器只会被置于C4模式,这是一个深度较浅的C-Status电源管理状态,结果会产生可能与DC4或C6模式的能耗节省,但在返回活跃状态的时间将大大减少。
◎ Enhanced Core MA :Enhanced Dynamic Acceleration Technology
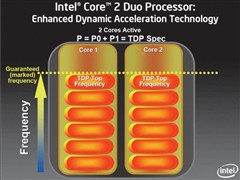
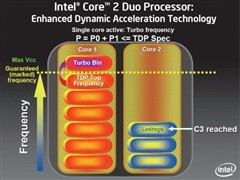
事实上,Enhanced Dynamic Acceleration Technology (IDA)功能并非首度应用于Penryn处理器,先前Socket P版本的Merom处理器就已加入,是一项因应旧有的单线程软件而生的技术。
旧式软件由于未对多核心作出优化,因此在运作时只会使用其中1颗核心,而另一颗核心将会被闲置,因此,IDA技术会自己运作,当其中一颗核心处于完全负载水平,而另一颗核心却被闲置而进入C3 Deep Sleep 模式(Core Clock、PPL、L 1 C ache停止运作),完全负载的核心将会进入Turbo Bin状态,核心频率将会被提高,加速运作令工作提早完成。
读者可以另外想象为1间具有2个莲蓬头的浴室,当其中1个莲蓬头被关闭,另一个莲蓬头的水压将会提升。
虽然核心频率进一步提升,但处理器的TDP水平仍未超过规格上限,全因双核心处理器的最高TDP数值,是计算2颗核心在近乎完全负载下的表现,由于IDA是当1颗核心已进入C3 Deep Sleep模式下,另一颗核心才会进入Turbo Bin模式,整体TDP表现将会比双颗核心在几近完全负载下更低,PC厂商因此不需为IDA技术,提升处理器散热要求。
据了解,核心的倍频数值在Turbo Bin状态下增加1x,以正常情况下其核心频率为12 x 200M Hz = 2.4G Hz,但在Turbo Bin模式下,核心频率将会变成13 x 200M Hz = 2.6G Hz,而Intel则保证每颗支持IDA技术的处理器均可安全地提升至 Turbo Bin的频率水平。
● 45nm Penryn 桌面双核心:Wolfdale 2.33GHz 工程样本

图为Intel下一代45nm「Penryn」家族桌面双核心处理器,处理器序号为「80570PJ0536M」,其中「80570」代表核心为「Wolfdale」、「P」为桌面级主流级至效能级产品、「J」是1333MHz FSB、「053」代表频率为2.33GHz、「6M」则代表L2 Cache 容量为6MB。
其支持MX、SSE、SSE2、SSE3及SSE4.1指令集、Intel Virtualization Technology、Enhanced Intel SpeedStep、Intel 64Bit支持、Execute Bit技术及Intel Trust Execution Technology(TXT)。
「Wolfdate」核心内建4.1亿个晶体管,相比上代「Conroe」核心多出1.19亿个,主要原因为L2 Cache容量提升50%,约占9.6千万个晶体管,余下部份则为SSE4指令运算单元及微架构的改良部份。

左为45nm Wolfdate核心、右为65nm Conroe核心

虽然内建晶体管数目上升约40%,但由于改采45nm制程,芯片大小由上代的143平方毫米,减至只有103平方毫米,有助成本进一步下降。
「Wolfdale」处理器采用全新45nmHigh-K金属闸极技术,VTT电压由上代1.2V减至1.1V,同时单晶粒功耗亦降低约15%,因此能耗表现十分出色。
此外,Intel上代65nm精品频率约为3GHz,频率超过3GHz后,功耗将会出现明显增长,而45nm精品可达约4GHz,意味着Intel新一代45nm将有一定的频率提升空间。
由于新一代45nm产品在CPU GTLREF Ratio设定上有所变更,因此旧有主机板可能需要更新BIOS才能正常启动。
值得注意的是,尽管Intel一直强调只有「3」系列芯片组才能支持45nm,但有主机板业者指出,其实965芯片组也能透过BIOS更新作出支持,不过VTT电压将会被设定至1.2V,处理器功耗会随之提高,减低产品寿命,965芯片组方案虽然可行,但并不建议采用。
● 测试平台:
Intel Core 2 Duo E6550 (2.33GHz/4MB L2/1333MHz FSB)
Intel Wolfdate ES Sample (2.33GHz/6MB L2/1333MHz FSB)
Evercool Euffalo HPFI-10025 Cooler
Gigabyte GA-P35T-DQ6 (P35 + ICH9R + DDR3)
Gigabyte GA-G33-DS3R (G33 + ICH9R)
ADATA DDR3-1066 CL 6-6-6-18 1GB x 2
MSI GeForce 8800Ultra VGA Card
Gigabyte ODIT 800W Power Supply
Maxtor DiamondMax 10 160GB 7200rpm SATA II
Windows Vista Ultimate 32Bit Edition
● 性能测试:45nm V.S 65nm Dual Core
Intel Core 2 Duo | Intel "Wolfdate" | Performance | |
PC Mark 05 | |||
Overall | 6922 | 7305 | +5.53% |
CPU | 5995 | 6029 | +0.78% |
Memory | 5401 | 5613 | +3.94% |
Graphics | 13627 | 14062 | +3.19% |
CineBench 9.5 | |||
Single-Core/CPU | 390 | 430 | +10.26% |
Multi-Core/CPU | 742 | 798 | +7.55% |
C4D Shading | 462 | 503 | +8.87% |
OpenGL Software | 1458 | 1738 | +19.20% |
C4D Shading | 2683 | 2435 | +9.24% |
SicenceMark 2.0 | |||
Overall | 1378.07 | 1463.85 | +6.22% |
Molecular Dynamics | 1127.43 | 1276.33 | +13.21% |
Primordia | 1255.55 | 1325.30 | +7.14% |
Cryptography | 1057.07 | 1069.19 | +1.15% |
STREAM | 1647.49 | 1768.80 | +6.72% |
Memory | 1642.07 | 1758.84 | +7.11% |
BLAS/FLOPs | 1800.54 | 1864.61 | +3.56% |
SiSoftware Sandra 2007 | |||
ALU | 21323 | 21671 | +1.63% |
SSE3 | 14829 | 17076 | +15.15% |
Int | 129258 | 129539 | +0.22% |
Float | 69658 | 69987 | +0.47% |
RAM Bandwidth Int | 6318 | 6919 | +9.51% |
RAM Bandwidth Float | 6285 | 6891 | +9.64% |
Divx 6.6 Alpha w/SSE4 | |||
1080p Mpeg2 to Mpeg4 | 69s | 32s | +115.63% |
Mainconcept H.264 Encoder | |||
1080p Mpeg2 to H.264 | 204.78s | 179.20s | +12.49% |
Windows Movie Maker | |||
Publishing Movie | 158.45s | 153.41s | +3.19% |
Windows Photo Gallery | |||
Print to XPS | 34.86s | 33.25s | +4.62% |
Send to Mail | 34.89s | 33.43s | +4.17% |
Adobe Photo Elements | |||
SmartFix | 177.91s | 163.99s | +7.82% |
Album Creation | 38.92s | 36.52s | +6.17% |
Microsoft Office 2007 | |||
Word - Merge | 50.33s | 38.1s | +6.30% |
PowerPoint - Print to XPS | 75s | 69s | +8.00% |
Excel - Big Number Crunch | 13.64s | 12.97s | +4.85% |
Excel - Option Pricing | 49.53 | 45.32 | +8.51% |
3DMark 05 | |||
Default | 14055 | 15316 | +8.97% |
CPU | 12403 | 12891 | +3.96% |
CPU Test 1 | 7.1 | 7.6 | +6.58% |
CPU Test 2 | 9.0 | 9.2 | +2.22% |
3DMark 06 | |||
Default | 10227 | 10467 | +2.35% |
CPU | 2047 | 2164 | +5.72% |
CPU Test 1 | 0.640 | 0.680 | +6.25% |
CPU Test 2 | 1.048 | 1.102 | +5.15% |
Doom3 | |||
1024 x 768 (UHQ) | 187.9 | 208.1 | +10.75% |
FarCry | |||
1024 x 768 (HQ) | 114.91 | 126.95 | +10.48% |
F.E.A.R | |||
1024 x 768 (FMOMFBMMFFM) | 259 | 281 | +8.49% |
Half-Life 2 | |||
1024 x 768 (HQ) | 132 | 181 | +31.12% |
Serious Sam 2 | |||
1024 x 768 (UHQ) | 134.6 | 157.1 | +16.72% |
● 温度/功耗测试:
65nm | |
Idle (EIST Disable) | |
Intel Core 2 Duo E6550 | Power - 61W |
Temp - | |
Intel Wolfdate 2.33GHz ES | Power - 43W |
Temp - | |
Max Power Loading Tools for | |
Intel Core 2 Duo E6550 | Power - 83W |
Temp - | |
Intel Wolfdate 2.33GHz ES | Power - 59W |
Temp - |
此次编辑部找来Intel 「Wolfdale」2.33GHz工程样本,与甫上市的Intel Core 2 Duo E6550进行对比测试,由于两者核心频率相同,测试后即即可得知全新「Penryn」家族在微架构改良后的增幅变化。根据结果显示,在大部份视讯编码处理、绘图、影音处理、2D/3D应用、多媒体及游戏等应用上有5%-10%的增益,效果令人满意。
其中,「Penryn」处理器家族改用Radix-16 Divider (除法器),同时可处理每笔4Bit的数据,相较以往Radix-2或Radix-4 divider只可处理每笔2Bit的数据,在整数及浮点数运算能力明显提升,因此在Science Mark 2中已能反映。
此外,由于游戏会大量使用平方根运算,拥有Radix-16 Divider的「Wolfdale」,在3D游戏测试项目中,相比上代至少有10%的增长,而大量采用平方根运算的Half-Life 2更为明显,效能提升达31%。
SSE指令执行表现,可从Sandra 2007指出「Wolfdale」的SSE3执行效率部份上升了约15%,反映出全新Super Shuffle Engine设计有着明显改善,如果软件支持SSE指令集,这颗处理器的效能增益将会更为显著。
由于大部份测试软件均未支持全新SSE4指令集,因此令「Wolfdale」的真正实力被埋没,此次测试中仅DivX 6.6 Alaph支持SSE4,测试显示其增益可达115.63%,令人惊讶,预期未来会有更多软件加入SSE4指令集,测试成绩更会更理想。
值得注意的,此次效能测试并未包括45nm制程是否能为处理器带来的频率提升空间,因此「Penryn」的真正实力未能由以上测试结果解悉,仅能获知改良后微架构所带来的增益,敬请注意。
功耗表现方面,采用全新45nmHigh-K制程的「Wolfdale」,除晶体管数目提升达40%,但功耗下降约28%,表现更加出色,且温度亦大幅降低,证明Intel 45nm制程导入应用已十分成熟,2007年第四季供货将顺利无虞。
[总结]:Intel「Penryn」如期现身,每年推出具增强微架构或全新微架构处理器产品的承诺顺利达阵,其不仅仅是单纯制程提升,更重要的是,微架构设计经全力改良后,成效更较当年Intel P4 Willamette提升至Northwood核心,有过之而无不及。
面对着AMD全新K10微架构来袭,单纯以微架构而论,Intel「Penryn」家族或许在效能表现略有不及,但由于拥有更为先进制程、核心频率及成本等优势,整体而言,AMD K10未必能占得上风,双雄胜负难料,现时下结论为时过早。
而值得注意的是,Intel已向主机板业者透露,将于10月提供下一代微架构「 Nehalem」处理器样本,预计2008年下半年面市,「Penryn」家族只需要支撑半年至9个月,就会降格至中低阶,与新一代「Nehalem」处理器连手夹击AMD K10处理器。如此精细缜密布局,相信Intel已记取先前惨遭AMD K8痛击的教训,做好万全准备,显示龙头绝不退让的决心。
Intel 45nm大军全力备战,高举全新「Tick-Tock」硅与微架构发展战略大旗,力图强势封锁对手攻势,AMD能否稳守得来不易江山,双雄激战备受关注。<
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}