

Phenom VS Penryn 双雄大战锁定年底
◎ Enhanced Core MA :Split Load Cache Enhancement

Intel Core微架构明显强化处理器的Cache架构,传统的双核心设计中,每个独立的核心都有自己的L2 Cache,但Intel Core微架构则是透过核心内部的Shared Bus Router共享相同的L2 Cache,当CPU 1运算完毕后把结果存在L2 Cache时, CPU 0便可透过Shared Bus Router读取CPU 1放在共享L2 Cache上的数据,大幅减低读取上的延迟并减少使用 FSB 频宽。同时加入L2 & DCU Data Pre-fetchers及Deeper Write output缓冲存储器,大幅增加Cach 的命中率。
Shared Bus Router 除更有效处理L2 Cache读取外,亦为双核心使用FSB传输进行排程,新加入的Bandwidth Adaptation机制改善了双核心共享FSB时的效率,减少不必要的延迟。
Penryn处理器的L2 Cach 容量增加了50%,双核心产品L2 Cach 容量最大可达至6MB、四核心更可高达12MB,并提升至24路联合(24-way set Associative) ,令L2 Cache命中率进一步提升,并大幅度提升使用率。
此外,亦加入全新增强高速缓存行拆分负载功能(Split Load Cache Enhancement),当读取数值时,若数据位于2个不同的高速缓存中,则会对负载行进行拆分。即便单个高速缓存行中的数据未经过适当调整,而自单个高速缓存行中读取数据,亦较自2个高速缓存行中读取数据快上数倍。
◎ Enhanced Core MA :Improved Store Forwarding
据了解,Penryn能在通过其它负载或存储之前作出推测,并快速分派两部份拆分负载,大大提高读取性能,可拉升执行数据扫描的应用程序的效率,例如视讯动态评估等工作。
Intel Core微架构加入了Memory Disambiguation设计,透过Out of Order过程分析内存读取次序,分析数据是否独立读取执行,如果与前面的数据存取动作并无关系,可令其提早执行,降低处理器的等候时间,减少闲置及延迟值。
另外,也进一步改内存系统效能,加速超过8bit的地址边界、令处于管线中的杂乱存储结果的读取速度,可立即向负载中的数据转发存储结果,且毋须等待存储完成再写入内存内。
◎ Enhanced Core MA :Faster OS Primitive Support
在启动某一个关键代码段、并要以独占的方式访问某一个资源时(例如系列内的 I/O设备) ,某些操作系统会临时阻止或屏敝中断,因此Penryn加入高速操作系统同步原始支持(Faster OS Primitive Support),能更快速清除中断、设置中断功能 (CLI/STI),迅速进入及退出此一模式,进而显著提高执行此类代码段的性能。
Penryn处理器可以更快速地执行锁定的指令,例如XCHG、ADD/XADD/NEG/BTS/AND及CMPXCHG,且可更快速访问时间戳数器 (RDTSC),以上这些功能常用于数据库或事务处理的服务器。
◎ Enhanced Core MA :Virtualization Performance Improvements
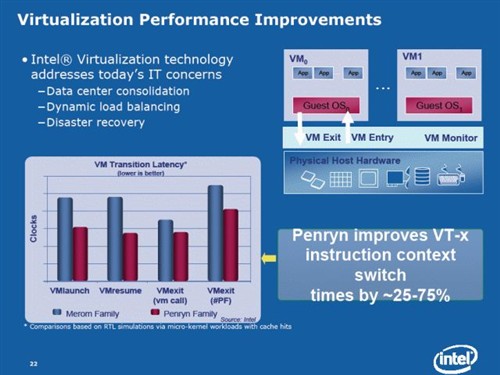
Penryn处理器在VT (Virtualization Technology)技术上进行显著改良,其支持EPT 延伸分页,并改良VT-x指令对虚拟主机转换、进入及退出的速度,平均可提升25%至75%,且只需要通过微架构上的改良,不用更改任何虚拟主机软件设计。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}