

Phenom VS Penryn 双雄大战锁定年底

AMD 9月10日首发9款巴塞罗那新品
9月10日AMD发布的K10架构Barcelona四核心Opteron处理器,主要针对服务器市场,共包括9款新品。其中4款为对应多路系统的83xx系列,五款为对应双路系统的23xx系列,全部为原生四核心,4x512KB二级缓存,2MB三级缓存,1000MHz HyperTransport总线。其中,较为高端的8350、2350(2GHz)和8347、2347(1.9GHz)的TDP为95W;8347 HE、2347 HE(1.9GHz)、8346 HE、2347 HE(1.8GHz)和2344 HE(1.7GHz)的为68W。AMD今天公布的首发价格如下:

AMD K10架构桌面版Phenom将在12月发布
相信大多数用户更关心桌面平台K10架构何时才会到来,在10日的发布会上AMD表示,针对桌面平台的K10架构新品将会在今年的12月份正式发布。桌面版K10将采用启用全新的品牌——Phenom,目前其中文名称还没有公布确定,很多网友猜测其为“飞龙”。关于Phenom的产品型号,请参看《巴塞罗那已出货 AMD K10型号规格预览》一文。

Phenom桌面处理器同样采用K10架构
那么Phenom的性能究竟如何呢?虽然目前产品还未正式发布,但国外一些网站已经有了相关的Phenom的模拟测试,但用的是Barcelona Opteron平台进行的修改,虽然这个数据不能起到最终的性能指导作用,但这个成绩对于我们了解Phenom的性能有很大的指导意义。而在今年第四季度,还有一个重要的选手登场,相信很多朋友也有所了解,就是Intel 45nm大军Penryn的发布。那么,第四季度K10 Phenom的真正对手将是Penryn,新一轮的大战即将拉开序幕。
相信很多对于K10架构的优势,已经有了一些了解,但对于45nm Penryn的新增加的功能以及架构改良,还有一些陌生。今天,我们就带着大家了解一下45nm Penryn的几大全新特点。
● Intel 45nm处理器大军Penryn铁定本年第四季上阵

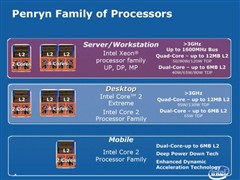
2006年下半年,Intel正式发布新一代「Core」微架构,取代面市5年、疲态毕露的「Netburst」微架构,成功令Intel谷底回春,重新站上x86处理器产品领导地位,而为保持此一优势,Intel同时也宣布全新「规则律动」「Tick-Tock」硅与微架构发展战略,于每年推出新处理器技术时,皆具备改良的微架构或是全新设计微架构,以迎合未来十年甚至更远的处理器市场。
全新45nmPenryn家族共有7名成员,包括双核心桌面处理器Wolfdate、四核心桌面处理器Yorkfield、双核心行动处理器 Penryn、双核心Xeon DP处理器 Wolfdate DP、四核心 Xeon DP处理器Harpertown、双核心 Xeon MP处理器Dunnington DC及四核心Xeon MP处理器Dunnington QC。
Penryn双核心版本内建 4.1 亿个晶体管,四核心则有8.2亿个晶体管,微架构经强化后,在相同频率下较上代Core产品拥有更高性能,同时L 2 Cache容量亦提升50%,明显提高数据读取执行的命中率。此外,亦加入47条全新Intel SSE4指令,提高媒体性能和实现高性能运算应用。
● 全新45nm High-K金属栅极技术 能效表现再提高
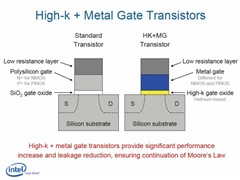
由于深知漏电问题将会阻碍芯片和个人计算机的设计、大小、耗电量、噪声与成本开发,因此,新一代Penryn处理器家族将采用全新材料制作的45nm晶体管绝缘层(insulating wall)和开关闸极 (switching gate),减低晶体管漏电(electrical leakage)情况。
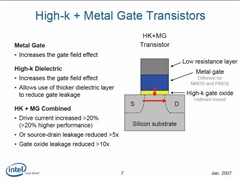
为能达到大幅降低漏电情形且可同时提升效能目标,Intel采用被称为High-k的新材料制作晶体管闸极电介质(transistor gate dielectric),而晶体管闸极的电极 (transistor gate electrode)也将搭配采用全新金属材料组合,增加驱动电流20%以上,不仅提升晶体管效能,同时源极 - 汲极 (source-drain) 漏电也可减少逾5倍,明显改善晶体管耗电量。
据了解,由于二氧化硅具有易制性 (manufacturability),且能减少厚度以持续改善晶体管效能,因此过去40余年来,业者主要均采用二氧化硅做为制作闸极电介质的材料。
虽然Intel于导入65nm制程时,已全力将二氧化硅闸极电介质厚度降低至1.2nm,相当于5层原子,但由于晶体管缩至原子大小的尺寸时,耗电和散热亦会同时增加,产生电流浪费和不必要的热能,因此若继续采用目前材料,进一步减少厚度,闸极电介质的漏电情况势将会明显攀升,令缩小晶体管技术遭遇极限。
为解决此关键问题,Intel正规划改用较厚的High-k材料(铪hafnium元素为基础的物质)作为闸极电介质,取代沿用至今已超过40年的二氧化硅,此举也成功令漏电量降低10倍以上。
由于High-k闸极电介质和现有硅闸极并不兼容,Intel全新45nm晶体管设计也必须开发新金属闸极材料,目前新金属的细节仍属商业机密,Intel现阶段尚未说明其金属材料的组合。
另与上一代技术相较,Intel的45奈制程令晶体管密度提升近2倍,得以增加处理器的晶体管总数或缩小处理器体积,令产品较对手更具竞争力,此外,晶体管开关动作所需电力更低,耗电量减少近30%,内部连接线 (interconnects) 采用铜线搭配 low-k电介质,顺利提升效能并降低耗电量,开关动作速度约加快 20%。
值得注意的是,Intel成功令新一代 45 nm制程产品的漏电情况降低逾5倍,其中晶体管闸极氧化物漏电量更降低超过10倍,相较上代65nm制程产品,在同一功耗表现下,频率下可提升约20%,或是在同一频率下功耗更低,电池续航力也明显大幅提升。
另一方面,Intel使用创新设计法则和先进光罩技术,将193nm干式微影技术 (dry lithography) 延伸应用在45nm处理器上,全力发挥成本优势和高易制性。
● Penryn :新增47条SSE4指令


自Intel Pentium MMX 处理器开始,处理器新增SIMD(Single Instruction Multiple Data)多媒体指令集,可把多个批次性的指令组变成单一指令,以提升数据处理能力,后来Intel基于MMX指令发展出SSE(Streaming SIMD Extensions)指令集,直至Penryn处理器已发展至SSE4指令集。
MMX:1997年发布,全名为 MultiMedia eXtension,首颗支持MMX产品为 Pentium MMX 处理器,主要用作提升多媒体数据的处理能力,共有57条指令。
SSE:1999 年发布,全名为 Streaming SIMD Extensions,首颗支持SSE产品为 Pentium III处理器,除新增70条指令,进一步提升多媒体数据的处理能力,最重要的是解决了MMX指令与浮点指令不能同时处理的问题。
SSE2 :2001年发布,全名为Streaming SIMD Extensions 2,首颗支持SSE2产品为Pentium 4处理器,新增指令共144条,主要加入 64 位双精度浮点数及整型运算指令,以及加入处理器对Cache的控制指令以减低延迟,更重要的是完全解决SSE集指令需要占用浮点数据缓存器问题。
SSE3 :2004年发布,全名为Streaming SIMD Extensions 3,首颗支持的处理器为 Prescott核心的Pentium 4处理器,新增指令仅13条,主要特点是加入水平式缓存器整数运算,可对多笔数值同时进行加法或减法运算,令处理器能大量执行 DSP及3D性质的运算。浮点数数值转换成整数数值而不需要进行运算模式切换,避免模式切换时导致其它执行绪被延误,减损系统运算效能。
此外,SSE3 更针对多执行绪的应用程序进行执行非常好的化,使处理器原有的 Hyper-Theading 功能获得更佳的发挥。
SSE3指令集的补充版本,全名为 Supplemental Streaming SIMD Extension 3,首颗支持Intel Core微架构处理器,新增指令共16条,进一步增强 CPU在多媒体、图形图像和Internet等方面的处理能力,该16条指令原收录为 SSE4指令集中,之后决定提早加入至Core微架构产品中。
SSE4 :全名为Streaming SIMD Extension 4,被视为继2001年以来最重要的媒体指令集架构的改进,除扩展Intel 64指令集架构外,还加入有关图形、视频编码及处理、三维成像及游戏应用等指令,令涉及音频、图像和数据压缩算法的应用程序大幅受益。
据了解,SSE4将分为4.1版本及4.2版本,4.1版本将会首次出现于Penryn处理器中,共新增47条指令,主要针对向量绘图运算、3D游戏加速、视像编码加速及协同处理加速动作,包括:
Penryn SSE4 Instruction summary | ||
Instruction Category | Instructions | Benefits |
Packed DWORD Multiplies | PMULLD, PMULDQ | 提升编译器矢量运算效能 |
Floating Point Dot Product | DPPS, DPPD | 3D立体制作及游戏,支持CG及HLSL等语言 |
Multi-packed sum of absolute diffs& min pos | MPSADBW, PHMINPOSUW | 视频编码处理 |
Streaming Load | MOVNTDQA | 视频编码处理、绘图及GPU数据分享 |
Floating Point Round | ROUNDPS, ROUNDSS, ROUNDPD, ROUNDSD | 视频编码处理 、绘图、影音处理、2D/3D应用、多媒体及游戏等 |
Packed Blending | BLENDPS, BLENDPD, BLENDVPS, BLENDVPD, PBLENDVB, PBLENDDW | 编译器矢量运算及影音处理、多媒体、游戏等应用 |
Packed Integer Min and Max | PMINSB, PMAXSB, PMINUW, PMAXUW, PMINUD, PMAXUD, PMINDS, PMAXSD | |
Register Insertion/Extraction | INSERTPS, PINSRB, PINSRD, PINSRQ, EXTRACTPS, PEXTRB, PEXTRD, PEXTRW, PEXTRQ | |
Packed Format Conversion | PMOVSXBW, PMOVZXBW, PMOVSXBD, PMOVZXBD, PMOVSXBQ, PMOVZXBQ, PMOVSXWD, PMOVZXWD, PMOVSXWQ, PMOVZXWQ, PMOVSXDQ, PMOVZXDQ | |
Packed Test & Set | PTEST | |
Packed Compare for Equal | PCMPEQQ | |
Pack DWORD to Unsigned WORD | PACKUSDW | |
● SSE4 :向量、浮点运算专门化 加入串流式负载指令
据Intel指出,在应用SSE4指令集后,Penryn增加了2个不同的32Bit向量整数乘法运算支持,引入了8 位无符号 (Unsigned)最小值及最大值运算,以及16Bit 及32Bit 有符号 (Signed) 及无符号运算,并有效地改善编译器效率及提高向量化整数及单精度代码的运算能力。同时,SSE4 改良插入、提取、寻找、离散、跨步负载及存储等动作,令向量运算进一步专门化。
SSE4加入了6条浮点型点积运算指令,支持单精度、双精度浮点运算及浮点产生操作,且IEEE 754指令 (Nearest, -Inf, +Inf, and Truncate) 可立即转换其路径模式,大大减少延误,这些改变将对游戏及 3D 内容制作应用有重要意义。
此外,SSE4加入串流式负载指令,可提高以图形帧缓冲区的读取数据频宽,理论上可获取完整的快取缓存行,即每次读取64Bit而非8Bit,并可保持在临时缓冲区内,让指令最多可带来8倍的读取频宽效能提升,对于视讯处理、成像以及图形处理器与中央处理器之间的共享数据应用,有着明显的效能提升。
● Penryn :SSE4指令集强化视讯编码效率
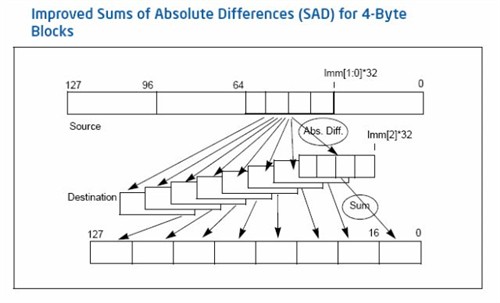
SSE4指令集进一步强讯编码效果,例如可同时处理8个4-byte宽度的SAD(Sums of Absolute Differences)运算,常用于新一代高清影像编码如VC.1及H.264等规格中,令视频编码速度进一步提升。
● Penryn :基于Core 微架构再作改良

除了采用更先进的45奈米制程及加入全新 SSE4 指令集外,Penryn 亦基于Intel Core微架构设计作出多项改良,称为「Enhanced Intel Core Microarchitecture」,并加入了:
Fast Radix-16 Divider(快速 Radix-16 除法器)
Super Shuffle Engine(超级洗牌引擎)
Split Load Cache Enhancement(增强型缓存拆分负载)
Improved Store Forwarding(存储转发)
Faster OS Primitive Support(高速操作系统同步原始支持)
Virtualization Performance Improvements (增强的Intel 虚拟化技术)
Deep Power Down Technology(深度节能技术)
Enhanced Dynamic Acceleration Technology(增强型动态加速技术)
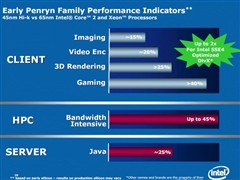
据Intel资深工程师兼Penryn微架构主管Stephen Fischer表示,与上代处理器产品相比,Penryn处理器在绘图效能约超过15%、视讯编码平均可提高20%、3D内容制作可提高逾30%,3D游戏效能更可高达40%,视乎软件设计而定。
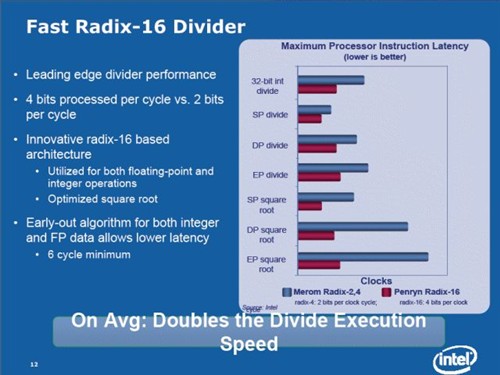
◎ Enhanced Core MA :Fast Radix-16 Divider
Intel在Core微架构中支持每个周期可处理多达4个指令(对比旧有处理器最多只能同时处理3个指令),且重新采用较高效率的14层Pipeline Stages,为提升分支预测的能力及准确性,Branch Predictor的Bandwitdh提升至20Byte (K8、Banias 为16B,Netburst为4B),令指令执行效率大大提高。
此外,Core微架构更加入Macro-Fusion技术,可把部份指令组合成单一Micro-Op 指令,令特定情况下每个周期可执行5个指令,更保留Micro-op Fusion技术,把相同的Macro-ops混合成单一个Micro-ops 透过Out-of-order逻辑可减少10% 的Micro-op指令执行数,除提升核心的执行效率,同时也保持高能源效益。
Penryn处理器除沿袭Core微架构的优点外,并进一步改良除法器的设计,在科学计算、三维坐标转换和其它数学运算密集型功能中,其带来约2倍的除法器速度,所包含的新一代的快速除法技术称为 Radix-16,可加速浮点和整数的除法运算速度。
据了解,基数为4的算法会在每次迭代运算中计算其2位的商值,当提高到基数为16的算法时,则允许在每次迭代中计算4位的商值,进而使延迟缩减一半。
◎ Enhanced Core MA :Super Shuffle Engine

Intel在 Core微架构中加入128Bit-SIMD interger arithmetic及128bit SIMD双倍精准度Floating-Point Operations单元。旧有的处理器执行128Bit的SSE、SSE2及SSE3指令时,需要把指令分拆为2个64Bit指令,在2个频率周期完成,但Core微架构则只需要1个频率周期便能完成,执行效率提升达1倍,现时SSE指令集已普遍使用于主流软件中,包括绘图、影像、音效、加密、数学运算等用途,单周期128Bit处理器能力利用频率以外的方法提升效能。
另一方面,Penryn处理器也有显著改良,其加入全新Super Shuffle Engine,令SSE 指令运算更具效率,以往处理Unpacking、Packing、Align Concatenated Sources、Wide Shifts、Insertion及Horizontal Arithmetic Functions Setup等128Bit宽度的字节、字及Dword SSE数据时,均无法在单一周期内完成,但Super Shuffle Engine设计除可让这些不同性质的128Bit SSE指令,在1个周期内便可完成,减低延迟及吞吐量外,更不用在软件端中作出改良即可实现。
◎ Enhanced Core MA :Split Load Cache Enhancement

Intel Core微架构明显强化处理器的Cache架构,传统的双核心设计中,每个独立的核心都有自己的L2 Cache,但Intel Core微架构则是透过核心内部的Shared Bus Router共享相同的L2 Cache,当CPU 1运算完毕后把结果存在L2 Cache时, CPU 0便可透过Shared Bus Router读取CPU 1放在共享L2 Cache上的数据,大幅减低读取上的延迟并减少使用 FSB 频宽。同时加入L2 & DCU Data Pre-fetchers及Deeper Write output缓冲存储器,大幅增加Cach 的命中率。
Shared Bus Router 除更有效处理L2 Cache读取外,亦为双核心使用FSB传输进行排程,新加入的Bandwidth Adaptation机制改善了双核心共享FSB时的效率,减少不必要的延迟。
Penryn处理器的L2 Cach 容量增加了50%,双核心产品L2 Cach 容量最大可达至6MB、四核心更可高达12MB,并提升至24路联合(24-way set Associative) ,令L2 Cache命中率进一步提升,并大幅度提升使用率。
此外,亦加入全新增强高速缓存行拆分负载功能(Split Load Cache Enhancement),当读取数值时,若数据位于2个不同的高速缓存中,则会对负载行进行拆分。即便单个高速缓存行中的数据未经过适当调整,而自单个高速缓存行中读取数据,亦较自2个高速缓存行中读取数据快上数倍。
◎ Enhanced Core MA :Improved Store Forwarding
据了解,Penryn能在通过其它负载或存储之前作出推测,并快速分派两部份拆分负载,大大提高读取性能,可拉升执行数据扫描的应用程序的效率,例如视讯动态评估等工作。
Intel Core微架构加入了Memory Disambiguation设计,透过Out of Order过程分析内存读取次序,分析数据是否独立读取执行,如果与前面的数据存取动作并无关系,可令其提早执行,降低处理器的等候时间,减少闲置及延迟值。
另外,也进一步改内存系统效能,加速超过8bit的地址边界、令处于管线中的杂乱存储结果的读取速度,可立即向负载中的数据转发存储结果,且毋须等待存储完成再写入内存内。
◎ Enhanced Core MA :Faster OS Primitive Support
在启动某一个关键代码段、并要以独占的方式访问某一个资源时(例如系列内的 I/O设备) ,某些操作系统会临时阻止或屏敝中断,因此Penryn加入高速操作系统同步原始支持(Faster OS Primitive Support),能更快速清除中断、设置中断功能 (CLI/STI),迅速进入及退出此一模式,进而显著提高执行此类代码段的性能。
Penryn处理器可以更快速地执行锁定的指令,例如XCHG、ADD/XADD/NEG/BTS/AND及CMPXCHG,且可更快速访问时间戳数器 (RDTSC),以上这些功能常用于数据库或事务处理的服务器。
◎ Enhanced Core MA :Virtualization Performance Improvements
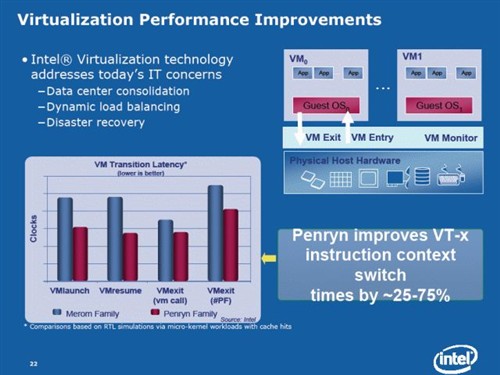
Penryn处理器在VT (Virtualization Technology)技术上进行显著改良,其支持EPT 延伸分页,并改良VT-x指令对虚拟主机转换、进入及退出的速度,平均可提升25%至75%,且只需要通过微架构上的改良,不用更改任何虚拟主机软件设计。
◎ Enhanced Core MA :Deep Power Down Technology

Penryn行动处理器加入全新高级电源管理状态(C-Status ,可显著降低闲置期间处理器的功耗,并有效防止晶体管漏电情况。
而此最新的处理器睡眠状态称为C-6 (Deep Power Down),处理器可实时清除L1 Cache内所有数据,在保存处理器微架构状态下,关掉内核(Core Clock 与 PPL 将停止 )及L2 Cache,虽然芯片组会继续为I/O提供内存交换动作,但却不会唤醒处理器。
只有需要内核时,电压才会攀升,Core Clock与 PPL 会打开,处理器将进行重置,把Cache数据从内存中回传,微架构状态将完全恢复,并继续执行指令。
据Intel指出,C6 (Deep Power Down)模式将会是DC4 (Enhanced Deeper Sleep)模式,电压再降低一半,且L 1 C ache也会进入关闭状态,处理器功耗更进一步减少逾75%,但返回活跃状态所需时间则比DC4多出约50%。
由于C-Status越深,进入该状态和返回活跃状态的能源损耗也会越高,时间亦较长,过于频繁地切换至深度C-Status会造成更大的能耗,因此,新一代Penryn处理器加入自身降级功能,该功能采用智能试探法,可确定闲置期间的节省,能否补偿关闭处理器后再重新恢复所需要的能耗成本。
如果不能,处理器只会被置于C4模式,这是一个深度较浅的C-Status电源管理状态,结果会产生可能与DC4或C6模式的能耗节省,但在返回活跃状态的时间将大大减少。
◎ Enhanced Core MA :Enhanced Dynamic Acceleration Technology
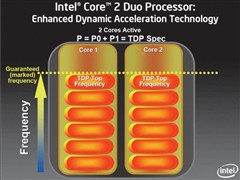
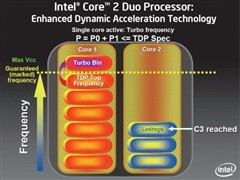
事实上,Enhanced Dynamic Acceleration Technology (IDA)功能并非首度应用于Penryn处理器,先前Socket P版本的Merom处理器就已加入,是一项因应旧有的单线程软件而生的技术。
旧式软件由于未对多核心作出优化,因此在运作时只会使用其中1颗核心,而另一颗核心将会被闲置,因此,IDA技术会自己运作,当其中一颗核心处于完全负载水平,而另一颗核心却被闲置而进入C3 Deep Sleep 模式(Core Clock、PPL、L 1 C ache停止运作),完全负载的核心将会进入Turbo Bin状态,核心频率将会被提高,加速运作令工作提早完成。
读者可以另外想象为1间具有2个莲蓬头的浴室,当其中1个莲蓬头被关闭,另一个莲蓬头的水压将会提升。
虽然核心频率进一步提升,但处理器的TDP水平仍未超过规格上限,全因双核心处理器的最高TDP数值,是计算2颗核心在近乎完全负载下的表现,由于IDA是当1颗核心已进入C3 Deep Sleep模式下,另一颗核心才会进入Turbo Bin模式,整体TDP表现将会比双颗核心在几近完全负载下更低,PC厂商因此不需为IDA技术,提升处理器散热要求。
据了解,核心的倍频数值在Turbo Bin状态下增加1x,以正常情况下其核心频率为12 x 200M Hz = 2.4G Hz,但在Turbo Bin模式下,核心频率将会变成13 x 200M Hz = 2.6G Hz,而Intel则保证每颗支持IDA技术的处理器均可安全地提升至 Turbo Bin的频率水平。
[总结]:Intel 45nm Penryn第四季度的登场,使Intel每年推出具增强微架构或全新微架构处理器产品的承诺顺利兑现,其不仅仅是单纯制程提升,更重要的是,微架构设计经全力改良后,性能更较当年Intel P4 Willamette提升至Northwood核心,有过之而无不及。
而面对着AMD全新K10微架构来袭,单纯以微架构而论,Intel 45nm Penryn家族或许在效能表现略有不及,但由于拥有更为先进制程、核心频率及成本等优势,整体而言,AMD K10未必能占得上风,双雄胜负难料,现时下结论为时过早,还是让我们共同把目光聚焦在第四季度,期待这场具有划时代意思的大战。<
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}