

谨防JS显存大骗局!TC/HM技术深度解析
为了让大家能够更好的理解Turbocache和HyperMemory技术,我们在这里先简单的说一下关于这两个名词。
Turbocache
目前,世界上最大的两家图形芯片生产商,NVIDIA和ATI都推出了各自的内存共享技术TurboCache和HyperMemory(以下简称TC和HM)。其中,率先将这项技术运用到独立显卡的是NVIDIA的GeForce 6200TC系列显卡。TurboCache技术实际上就是让图形芯片(GPU)利用PCI-E总线直接访问系统内存,让内存来完成显存的工作,这样一来就可以使显卡上的板载显存数量和容量减少,从而降低显卡的成本。首先,由于使用了PCI-E高速总线,使得总线带宽远远高于AGP,有效的减少了数据延迟,便得数据能够快速顺利进行交换。其次,TurboCache技术可以有效的利用内存,GPU可实时访问内存地址,进行数据的读取和存储,不需要划分固定的内存区域和容量,而系统也可以根据GPU的工作释放和分配内存。
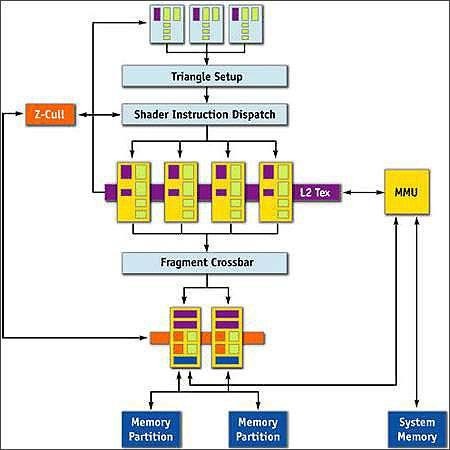
另外,NVIDIA还在6200TC核心中加入了MMU(内存管理单元),它的作用就是允许GPU无缝的分配或者不分配系统内存,并且高效的读取内存。而且MMU管理性能非常强大,可以线性访问系统内存,存储包括纹理缓存、深度缓存、色彩缓存等数据,并且大幅度提高内存的利用率。在NVIDIA的驱动程序中,也针对TC技术进行了相关的修改,使之能够智能化的确定彩色渲染、纹理填充和Z轴缓冲数据的准确位置,也使得GPU的处理能力大大提高。
HyperMemory
早在NVIDIA推出TurboCache技术之前,ATI就已经将HyperMemory技术运用在Radeon Xpress200芯片组上,主要是针对集成显卡对系统内存的使用。但随着NVIDIA推出6200TC以后,ATI也将HyperMemory技术运用到了独立显卡之中。
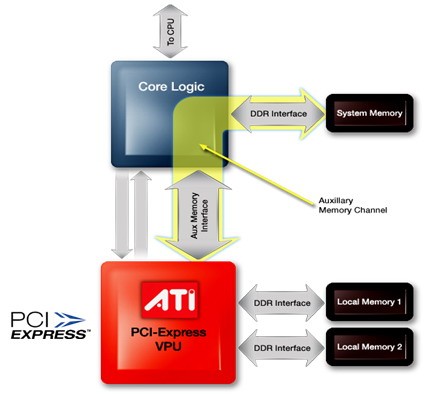
在技术方面,HyperMemory就是一种最优化使用系统内存的技术,显示核心通过PCI-E高速总线对系统内存进行实时访问,这和TurboCache技术并没有太大区别。HyperMemory采用原生PCI-E系统总线界面,保证了显示核心在高带宽的状态下快速访问系统内存。HyperMemory的驱动中含有先进的内存优化管理系统,可以智能化的分配和管理系统内存,从而达到最理想的使用状态。和TurboCache技术一样,HyperMemory对系统内存的使用也是实时性的,数据一旦使用完以后,便会自动释放掉,不会造成系统资源的浪费。

6200TC是NVIDIA第一款采用TurboCache技术的产品
正如NVIDIA对于6200TC的定位,ATI也是将HyperMemory技术首先运用到了面向低端的X300 SE显卡之中,这所以这做,也是为了顺应PCI-E平台发展的趋势。将PCI-E显卡的成本降低,而且是在保障性能的前提之下,从而使用PCI-E平台得到普及。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}