

NVIDIA帕斯卡GP100揭秘:3840流处理器
沉寂了许久的GPU显卡市场终于热闹起来了!AMD的北极星、NVIDIA的帕斯卡两大真正全新的架构即将隆重登场,各种爆料让人激动不已。
今天,TechPowerUp又拿到了帕斯卡家族优异大核心GP100的架构示意图,对它的基本规格也终于有了一个清楚的认识。
可以看出,帕斯卡架构的GP100核心在大体上仍然沿用了NVIDIA GPU这些年的设计思路,但规模更加强大,也有一些增强之处。

GP100核心架构总图
整个核心被分成了6组GPC(图形处理簇),这是具备高度独立性的GPU单元,拥有自己的渲染前端和后端。
每个GPC内包含10组SM(流式多处理器单元),而每个SM拥有64个CUDA核心,也就是整个GPU拥有60组SM、3840个CUDA核心,同时还有240个纹理单元。
已经宣布的高性能计算卡Tesla P100只开启了56组SM、3584个CUDA核心,即便如此也比麦克斯韦家族GM200核心(3072个CUDA核心)大了整整四分之一!
在图片边缘可以看到八组显存控制器,组成了4096-bit HBM2的规格,可提供720GB/s的超高带宽(理论上最高能做到1TB/s)。
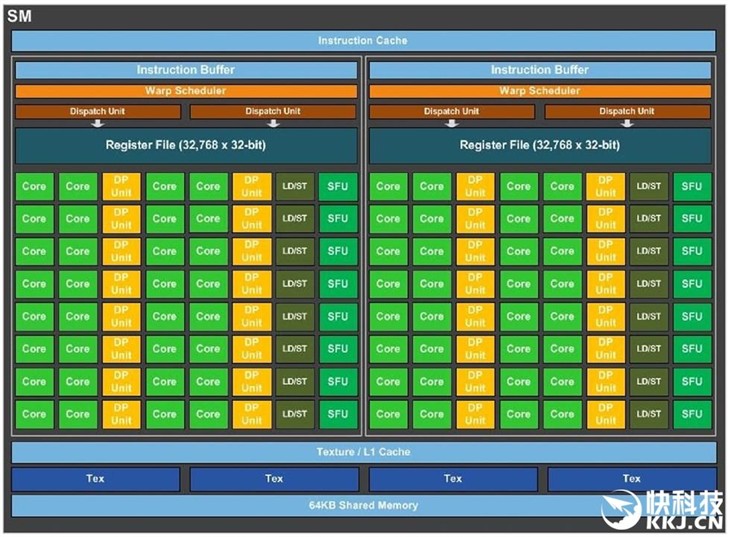
GP100核心SM单元架构图
另外还可以看到一个新的“High-speed Hub”(高速控制中心),由此伸出四个NVLink总线端口,官方号称单向带宽80GB/s,但不清楚是每个端口的,还是集体的。
NVLink总线类似多处理器系统中的Intel QPI、AMD HT,可以高速直连多个GPU,并支持真正的内存虚拟化,可大大加速GPU计算性能。
尽管规模如此庞大,帕斯卡核心依然可以运行在超高频率上,Tesla P100的核心基础、加速频率就分别有1328MHz、1480MHz,热设计功耗300W。
别忘了,GP100核心可是和AMD Fiji一样集成了四颗HBM2显存和中介层,能做到如此大规模、高频率,实在不容易。■
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}