

NVIDIA全新显卡Pascal解析 到底强在哪
2016上半年过得差不多了,显卡市场上这一年来基本上没什么新品,不论是AMD还是NVIDIA主推的还是上一代架构的显卡,恍恍惚惚之间28nm工艺的显卡竟然支撑了4年时间,这在以往的GPU升级历史上可不多见。之所以沉寂这么久是双方都在憋大招,AMD新一代显卡架构为14nm工艺的Polaris(北极星),NVIDIA准备的则是16nm工艺的Pascal(帕斯卡),后者在GTC 2016大会上首次揭开了面纱,NVIDIA发布的Tesla P100专业卡使用了旗舰GP100核心。

也许是久未见新工艺新架构显卡,现在看到GP100这样的庞然大物都觉得兴奋了,这几天我们已经被各种Pascal显卡爆料刷屏了。从Kepler到Maxwell架构,NVIDIA钱两次都是选择首发面向主流游戏市场的核心GK104、GM204(Maxwell首发的其实是GM107这样的低端核心),GK110、GM200大核心产品通常要晚半年时间,但这次的Pascal显卡就跟当年的GF100费米架构一样选择了大核心首发,历史终于轮回了。
作为16nm工艺的新一代旗舰,NVIDIA的GP100核心到底有多强?或者说它与目前的架构有什么质的不同?今天的超能课堂上我们就来分析下GP100核心的特色,回顾下它与Kepler、Maxwell架构有什么不同。
Pascal与Kepler、Maxwell规格对比
切入正题之前我们先来了解下GP100核心与Kepler、Maxwell架构的规格,此前NVIDIA官方也公布了GP100核心与GK110、GM200核心的一些对比,这里我们做了一份更详细的规格表,并加入了GM204及GK104这两款游戏显卡核心。
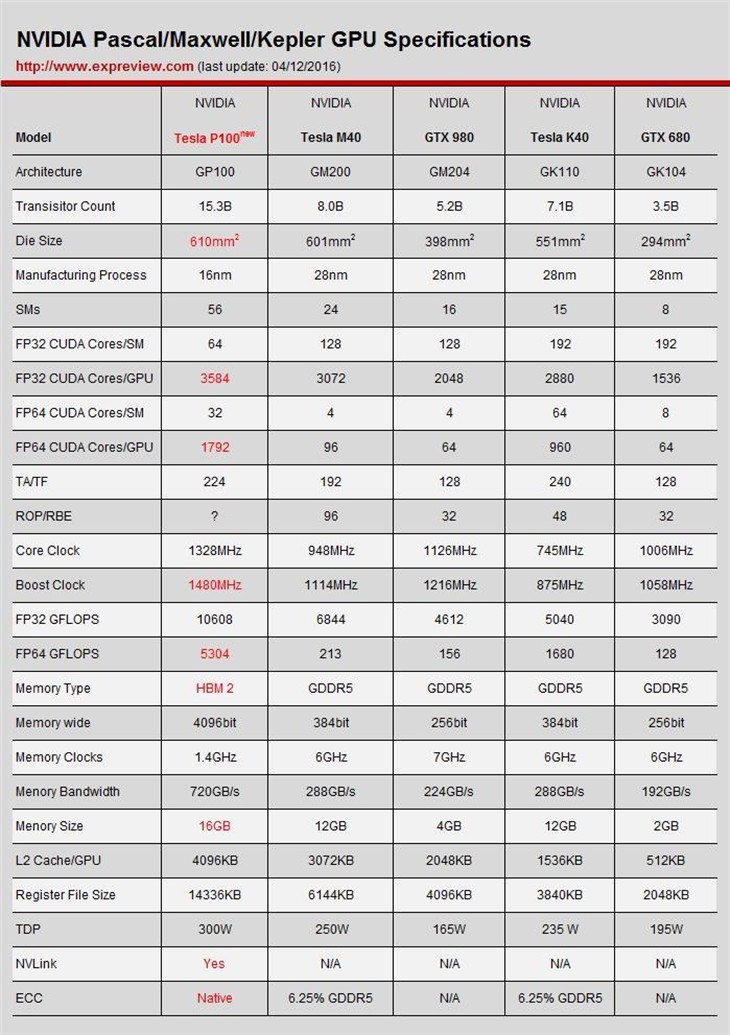
GP100核心与GK110、GM200、GM204、GK104核心规格对比
这份规格表内容非常多,初看之下会觉得手足无措,不过小编把需要重点关注的地方标红了,简单来说就是GP100核心晶体管密度再次攀升、CUDA核心大幅增加、双精度性能逆天增长、缓存/寄存器容量翻倍、HBM 2显存及NVLink总线,这几点基本上能概括GP100核心的特色。
Pascal架构看点之一:计算性能是关键,双精度性能逆市回归
GP100的性能一经公布,给小编的感觉就是NVIDIA这次回归了GK110大核心时代注重双精度运算的设计,而且比之前更加变态——GK110架构中FP64双精度与FP32单精度的比例不过1:3,每组SMX单元中有192个FP32单元,64个FP64单元,但GP100核心中每组SM单元中有64个FP32单元,但有32个FP64单元,FP64与FP32比例是1:2。
要知道,Maxwell架构中单双精度比砍到了1/32,GK104核心中单双精度比是1/24,这都远远低于Pascal核心,唯一能与之媲美的就是当年Fermi核心的Tesla加速卡了。
因此在双精度性能上,GP100核心可以说突破天际了,FP64浮点性能可达5.3TFLOPS,而GK110核心不过1.68TFLOPS,GM200核心更是只有可怜的0.21TFLOPS,GP100双精度性能达到了GK110核心的3倍多,是GM200核心的20多倍。
HPC很多应用需要双精度性能,不过深度计算(deep learning)这样的计算并不需要高精度运算,因为它天生自带纠错能力,而GP100的FP32 CUDA核心可以同时执行2个FP16半精度运算,因此FP16浮点性能高达21.6TFLOPS。NVIDIA在Tesla P100之外还推出了基于GP100核心的DGX-1深度学习超级计算机,由8颗GP100核心及2颗16核Xeon E5处理器组成,深度计算性能达到了170TFLOPS,号称比250台X86服务器还要强大。
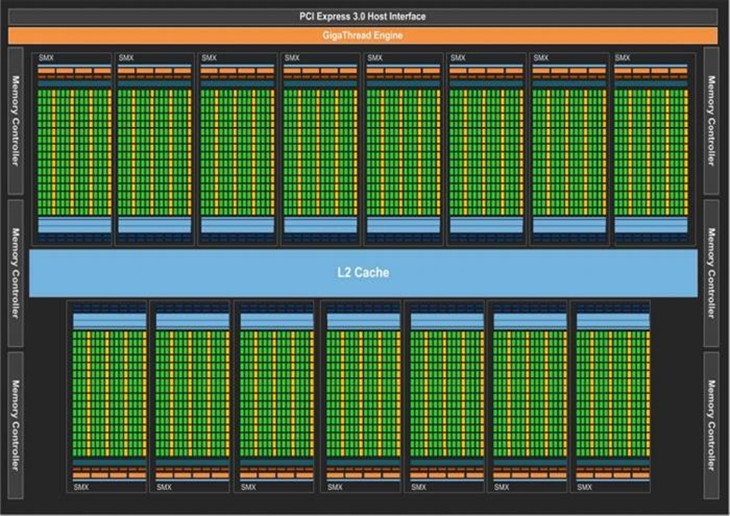
GK110核心架构示意图
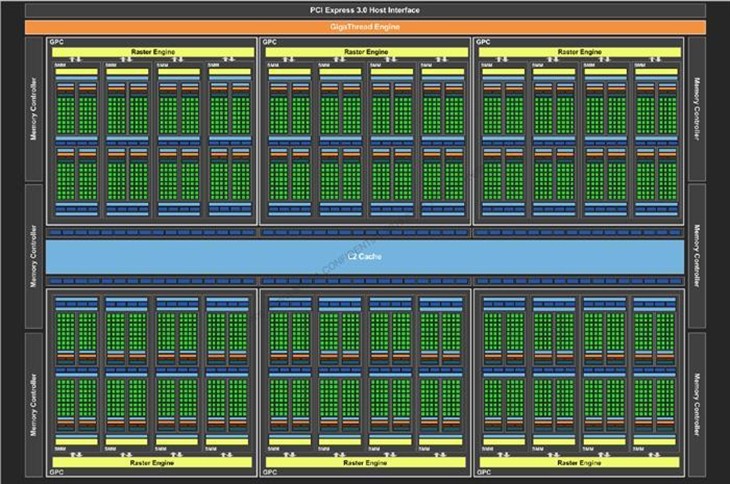
GM200核心架构示意图

GP100核心架构示意图
GP100为了提升计算性能,增强的不仅仅是双精度单元,其L2缓存、寄存器文件也大幅提升,总计拥有4MB L2缓存、14MB寄存器文件。
总之,NVIDIA的GP100核心为了计算性能可谓煞费苦心,双精度性能简直逆天,不过NVIDIA针对高性能运算所做的设计固然讨好HPC市场,但对游戏市场来说双精度是没多少用处的,反而浪费了晶体管单元,提高了成本及功耗。
Pascal架构看点之二:升级16nm工艺,密度、能效提升
从AMD的HD 7970显卡率先使用28nm工艺开始算起,TSMC的28nm工艺已经陪伴我们四年时间了,期间AMD、NVIDIA数次升级的新核心都没有工艺升级,依然坚持28nm工艺,双方都跳过了20nm工艺、直接进入了性能更好的FinFET工艺节点,只不过AMD选择了三星/GF的14nm FinFET LPP工艺,NVIDIA坚持了老朋友TSMC的16nm FinFET Plus工艺。

TSMC的16nm FinFET工艺优势
对半导体芯片来说,升级工艺通常意味着晶体管性能提升、功耗下降,同时晶体管密度大幅提升。具体到TSMC的16nm工艺,该公司此前表示其16nm工艺的晶体管密度是28nm HPM工艺的2倍左右,同样的功耗下性能提升38%,同样的速度下功耗降低54%,对比20nm工艺则是20%速度提升、35%功耗下降。
我们再来看下GP100核心的相关数据:
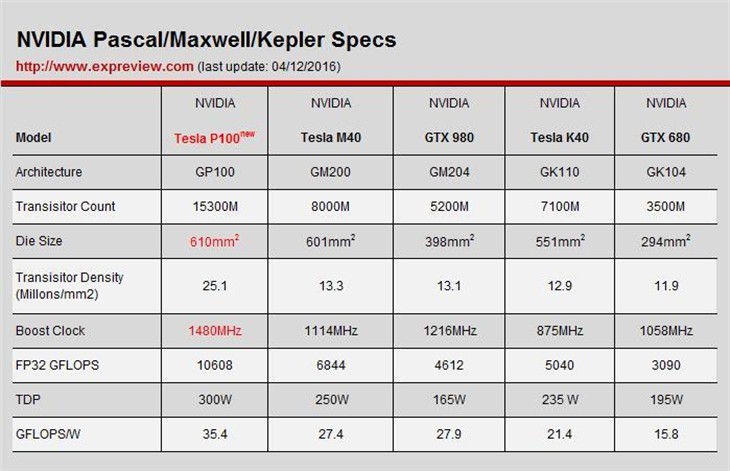
GP100核心的晶体管密度、频率及TDP功耗
我们简单地把几款GPU的晶体管密度换算了下(晶体管数量除以核心面积,由于GPU核心的电路复杂,这种算法不一定精确,仅供参考),16nm工艺的GP100核心晶体管密度大约是2510万每平方毫米,算起来晶体管密度比之前28nm工艺的Maxwell、Kepler恰好多一倍。
至于每瓦性能比,这里使用的是FP32浮点性能与TDP功耗的比值,考虑到上述核心面向的市场不同,我们要知道侧重高性能的GP100与游戏市场的GM204、GK104对比TDP是不公平的,不过最终的结果依然显示出16nm工艺的GP100在每瓦性能比上有明显优势。
从这一点也可以猜测,未来针对游戏市场的Pascal核心(比如GP104、GP106)问世之后,它们势必要阉割掉GP100核心上很多不必要的功能,优化功耗,所以其每瓦性能比无疑会更出色。
Pascal架构看点之三:HBM 2显存登场,16GB很好很强大
早在2年前的GTC大会上,NVIDIA就公布了Pascal显卡的2大特色——一个是NVLink总线,一个就是3D Memory,号称容量、带宽是目前显卡的2-4倍,带宽可达1TB/s,这个显存实际上就是HBM 2显存。有意思的是,NVIDIA此举也意味着尽管AMD Fury显卡抢先使用HBM显存,但NVIDIA还是在新一代HBM显存上抢了先,不知道AMD面对这种情况又是如何看的呢?
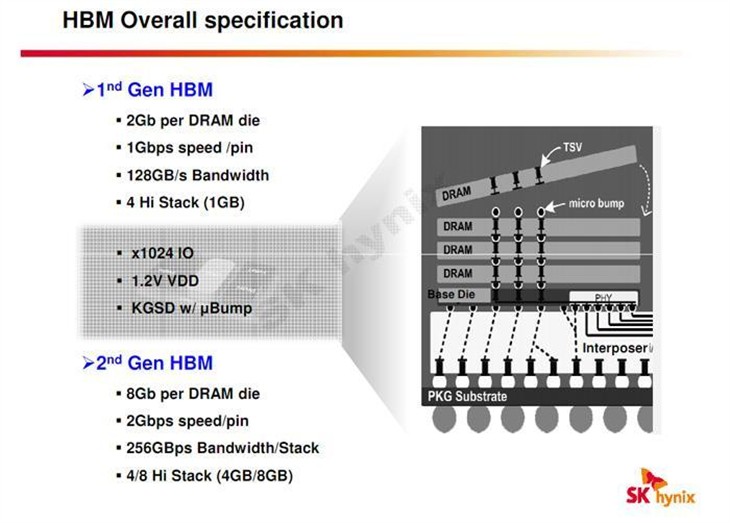
对于HBM 2显存,我们之前也多次做过介绍,HBM 2显存现在已经被JEDEC吸纳为标准。相比第一代HBM显存,HBM 2显存IO位宽不变,但核心容量从2Gb提升到了8Gb,支持4Hi、8Hi堆栈,频率从1Gbps提升到了2Gbps,带宽从512GB/s提升到了1024GB/s,这也是TB/s带宽的由来。
目前三星、SK Hynix已经或者正在量产HBM 2显存,单颗容量是4GB的,NVIDIA的GTC大会上展示了SK Hynix的HBM 2显存,GP100核心使用的应该也是Hynix的产品,每个GP100核心周围堆栈了4颗HBM 2显存,总容量是16GB,要比AMD的Fury显卡的4GB HBM显存容量高得多。
支持HBM显存对NVIDIA来说还有个好处,那就是ECC校验。此前的架构中,NVIDIA Tesla显卡的ECC校验需要占用6.25%的显存空间,这意味着有相当部分的显存要被“浪费”,Tesla K40加速卡的12GB显存中有750MB预留给ECC校验,可用的内存容量就剩下11.25GB,而且这还会影响内存带宽。
相比之下,HBM 2显存原生支持ECC校验,不需要额外的内存占用,这不仅提高了显存利用率,带宽也不会受影响。

GTC大会展示的SK Hynix公司的4GB HBM2显存
16GB HBM2显存总量在Tesla及Quadro专业卡中不算第一,但HBM 2显存超高的带宽是GDDR5显存望尘莫及的。不过值得注意的是,在GTC大会上展示的HBM 2显存频率标明是2Gbps的,但NVIDIA的GP100核心目前带宽只有720GB/s,并没有达到之前宣称的TB/s带宽,算下来频率应该只有1.4Gbps左右,这说明GP100核心的HBM 2显存并没有全速运行,不清楚NVIDIA为何留了一手。
Pascal架构看点之四:NVLink可支持8路显卡并行
如果说3D显存是NVIDIA公布的Pascal的第一个关键特性,那么NV Link总线就是另外一个关键了,它同样是NVIDIA针对高性能运算开发的技术,号称速度是PCI-E总线的5-12倍,前面提到的DGX-1深度计算超级计算机就使用了NV Link技术。

GP100显卡背后的NV Link接口
NV Link的优点就是带宽超高,目前PCI-E 3.0 x16带宽不过16GB/s,用在游戏显卡上是足够的,但在超算中就不够看了,新一代的PCI-E 4.0规范又延期了,这就得靠NV Link总线了。NV Link实际上是NVIDIA与IBM合作开发的,每个通道的带宽是40GB/s,GP100核心支持4个NV Link,双向带宽高达160GB/s,而且带宽效率高达94%,这些都要比PCI-E总线更有优势。
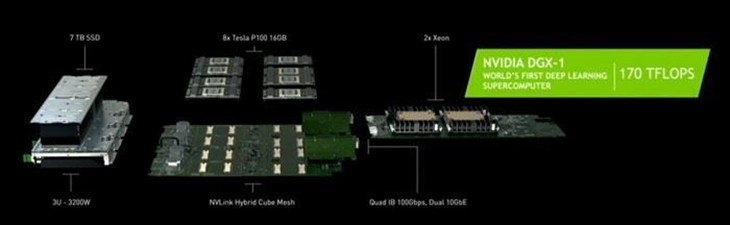
DGX-1的8路GP100显卡并行就靠了NV Link技术
NV Link技术主要是为高性能运算而生的,IBM会在他们的Power 9处理器中使用该技术,Intel就不太可能使用NVIDIA的技术了,他们有自己的并行总线技术。对于普通消费者来说,NV Link意义不大,不过超高的带宽、更低的延迟使得NV Link技术可以支持8路显卡并行,对高玩来说有一定吸引力,不过多卡互联的关键在于目前恐怕没有哪些应用或者游戏能够完美支持8卡运行。
Pascal显卡最关键的问题:消费级显卡如何“阉割”
以上四点只是NVIDIA Pascal显卡的部分特色,由于官方公布的细节还不够多,我们对Pascal显卡的了解还需要进一步深入。毫无疑问的是GP100大核心在高性能计算市场大有用武之地,不论是超高的双精度性能、超高的每瓦性能比还是超高的显存带宽、超高的NV Link总线,GP100大核心都拥有极强的竞争力,也无怪乎该卡刚发布,欧洲最强的超级计算机就准备使用Tesla P100专业卡升级了。

不过非专业用户对GP100最大的担心也来源于此,因为它身上集成了太多的专业技术,双精度运算对游戏应用没多少用处,16GB HBM 2显存虽然够YY,但成本让人担心,NV Link总线对游戏显卡来说更是屠龙之技,只有16nm工艺的高能效对游戏玩家来说是有用的。
今年6月份的台北电脑展上,NVIDIA发布针对游戏市场的GP104显卡基本上是板上钉钉了,届时我们才能看到NVIDIA在GP104核心上又做了哪些针对性改良和优化。此外,AMD同期也会发布Polaris 11和Polaris 11显卡,双方新一代显卡大战很快也要揭幕了。■
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}