

机器学习如何帮助Youtube实现高效转码?
作为世界上最大的视频平台,YouTube 每天都会新增来自世界各地的数百万个视频。这些视频具有非常大的多样性,对 YouTube 来说,要将这些不同的视频和相关的音频都转换成人们可以接受的播放质量是一个相当大的挑战。此外,尽管谷歌的计算和存储资源非常庞大,但也总归是有限的, 要以上传视频的原格式存储网络视频无疑会带来显著的额外成本。

为了提高网络视频的播放质量,关键是要降低视频和音频的压缩损失。增加比特率是一种方法,但同时那也需要更强大的网络连接和更高的带宽。而 YouTube 则选择了另一种更聪明的做法:通过优化视频处理的参数使其在满足最低视频质量标准的同时不会增加额外的比特率和计算周期。
要在视频压缩和转码时满足视频质量、比特率和计算周期的要求,一般的做法是寻找对大量视频(而非所有视频)平均最优的转码参数组合。这种最优组合可以通过尝试每种可能来寻找,直到找到最让人满意的结果。而最近,有一些公司甚至尝试在每一段视频上都使用这种“穷举搜索”的方式来调整参数。
YouTube 通过在这一技术的基础上引入机器学习而开发出了一种新的自动调整参数的方法。目前,这一技术已经在提升 YouTube 和 Google Play视频影片的质量上得到了应用。
并行处理的优劣
据 YouTube 的博客介绍,每分钟都有 400 小时的视频被上传到 YouTube 上。而其中每个视频都需要被不同的转码器转码成几种不同的格式,以便可以在不同的设备上进行播放。为了提高转码速度,让用户更快看到视频,YouTube 将上传的每一个文件都切割成被称为“数据块(chunk)”的片段,然后再将其每一块都独立地在谷歌云计算基础设施的 CPU 中同时进行并行处理。在这一过程中所涉及到分块和重组是 YouTube 的视频转码中的一大难题。而除了重组转码后数据块的机制,保持每一段转码后的视频的质量也是一个挑战。这是因为为了尽可能快地处理,这些数据块之间不会有重叠,而且它们会被切割得非常小——每段只有几秒钟。所以并行处理有提升速度和降低延迟的优势,但它也有劣势:缺失了前后临近视频块的信息,也因此难以保证每个视频块在被处理后都具有看上去相同的质量。小数据块不会给编码器太多时间使其进入一个稳定的状态,所以每一个编码器在处理每一个数据块上都略有不同。
智能并行处理
为了得到稳定的质量,可以在编码器之间沟通同一视频中不同分块的信息,这样每一个编码器都可以根据其处理块的前后块进行调整。但这样做会导致进程间通信的增加,从而提高整个系统的复杂度,并在每一个数据块的处理中都要求额外的迭代。
但“其实,事实上我们在工程方面都很固执,我们想知道我们能将‘不要让数据块彼此通信’的想法推进多远。”YouTube 博客说。
下面的曲线图展示了来自一段使用 H.264 作为编解码器的 720p 视频的两个数据块的峰值信噪比(PSNR,单位:dB每帧)。PSNR值越高,意味着图片(视频每帧)的质量越高;反之则图片质量越低。可以看到每段视频开始时的质量非常不同于结束时的质量。这不仅在平均质量上没有达到我们的要求,这样剧烈的质量变化也会导致恼人的搏动伪影(pulsing artifact)。
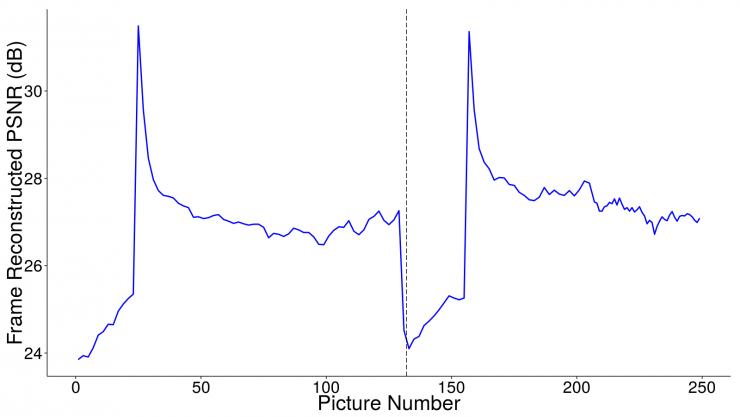
因为数据块很小,还要让每一块的行为都与其前后块的行为类似;所以研究人员需要在连续数据块的编码处理上保持一个大致相同的结果。尽管这在大部分情况下适用,但却不适用于本例。一个直接的解决办法是改变数据块的边界使其与高活动的视频行为保持一致,例如快速运动或场景剪切。但这样做就能让保证数据块的相对质量并使编码后的结果更均匀吗。事实证明这确实能有所改善,但并不能达到我们期望的程度,不稳定性仍经常存在。
关键是要让编码器多次处理每一个数据块,并从每一次迭代中学习怎么调整其参数以为整个数据块中将发生的事做好准备,而非仅其中的一小部分。这将导致每一个数据块的开端和结束拥有相似的质量,而且因为数据块很短,所以总体上不同数据块之间的差异也减少了。但即便如此,要实现这样的目标,就需要很多次的重复迭代。研究人员观察到,重复迭代的次数会受到编码器在第一次迭代上的量化相关参数(CRF)的很大影响。更妙的是,往往存在一个“最好的”CRF 可以在保持期望质量的同时只用一次迭代就能达到目标比特率。但这个“最好的”却会随着每段视频的变化而变化——这就是棘手的地方。所以只要能找到每段视频的最好配置,就能得到一个生成期望编码视频的简单方法。
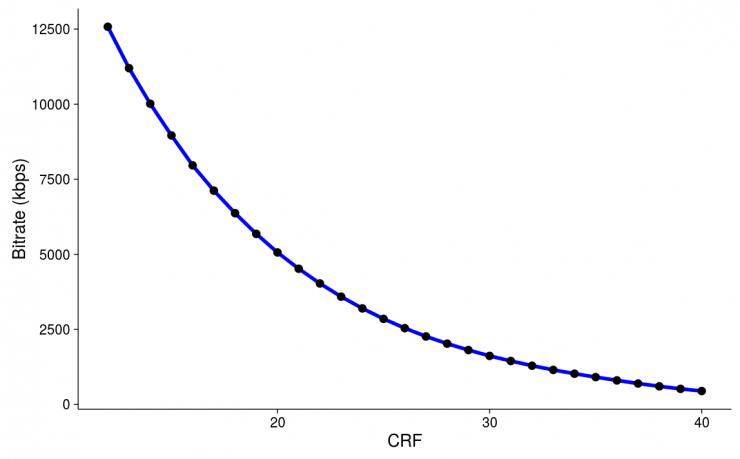
上图展示了 YouTube 的研究人员在同一段 1080p 视频片段上使用他们的编码器实验不同的 CRF 所得到的比特率结果(编码后的视频质量恒定)。可以看出,CRF 和比特率之间存在一个明显的函数关系。事实上这是对使用三个参数的指数拟合的非常好的建模,而且该图也表明建模线(蓝线)与实际观察到的数据(点)拟合得非常好。如果我们知道该线的参数,然后我们想得到一个我们的视频片段的 5 Mbps 版本,那么我们所需的 CRF 大约为 20.
大脑
那么接下来需要的就是一种能够通过对视频片段的低复杂度的测量预测三个曲线拟合参数的方式。这是机器学习、统计学和信号处理中的经典问题。YouTube 研究人员已将其相关的数学细节发表在他们的论文中(见文末1,其中还包括研究人员想法的演化历程)。而简单总结来说:通过已知的关于输入视频片段的信息预测三个参数,并从中读出我们所需的 CRF。其中的预测阶段就是“谷歌大脑(Google Brain)”的用武之地。
前面提到的“关于输入视频片段的信息”被称为视频的“特征(features)”。在 YouTube 研究人员的定义中,这些特征(包括输入比特率、输入文件中的运动矢量位、视频分辨率和帧速率)构成了一个特征向量。对这些特征的测量也包括来自输入视频片段的非常快速的低质量转码(能提供更丰富的信息)。但是,每个视频片段的特征和曲线参数之间的确切关系实际上非常复杂,不是一个简单的方程就能表示的。所以聪明的研究人员并不打算自己来发现这些特征,他们转而寻求谷歌大脑的机器学习的帮助。研究人员首先选择了 10000 段视频,并对其中每一段视频的每一个质量设置都进行了严格的测试,并测量了每一种设置的结果比特率。然后研究人员得到了 10000 条曲线,通过测量这些曲线研究人员又得到了 4×10000 个参数。
有了这些参数,就可以从视频片段中提取特征了。通过这些训练数据和特征集合,YouTube 的机器学习系统学到了一个可以预测特征的参数的“大脑(Brain)”配置。“实际上我们在使用大脑的同时也使用一种简单的‘回归(regression)’技术。这两者都优于我们现有的策略。尽管训练大脑的过程需要相对较多的计算,但得到的系统实际上相当简单且只需要在我们的特征上的一点操作。那意味着生产过程中的计算负载很小。”
这种方法有效吗?
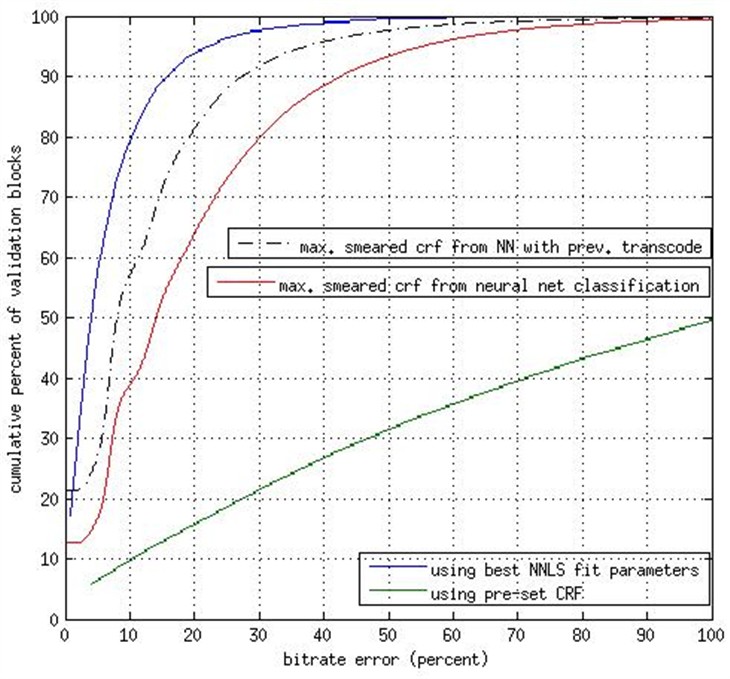
上图展示了在 10000 个视频片段上的各个系统的性能。其中每一个点(x,y)代表了压缩后的结果视频的比特率为原视频的比特率的 x% 时的质量百分比(y 轴)。其中的蓝线表示在每一个视频片段上都使用穷举搜索获取完美的 CRF 所得到的最好的情况。任何接近它的系统都是好系统。可以看到,在比特率为 20% 时,旧系统(绿线)的结果视频质量只有 15 %. 而使用了大脑系统之后,如果仅使用你所上传的视频的特征,质量可以达到 65%;如果还使用一些来自非常快速低质量转码的特征,更是能超过 80%(虚线)。

但是,实际上看起来如何?你可能已经注意到比起画质,YouTube 研究人员似乎更关注比特率。因为“我们对这个问题分析表明这才是根本原因 ”。画质只有真正被看到眼里时我们才知道好不好。下面展示了来自一段 720p 视频的一些帧(从一辆赛车上拍摄)。上一列的两帧来自一个典型数据块的开始和结尾,可以看到第一帧的质量远差于最后一帧。下一列的两帧来自上述的新型自动剪辑适应系统处理后的同一个数据块。两个结果视频的比特率为相同的 2.8 Mbps。可以看到,第一帧的质量已有了显著的提升,最后一帧看起来也更好了。所以质量上的暂时波动消失了,片段的整体质量也得到了提升。
据悉,这一概念在 YouTube 视频基础设施部分的生产中已被使用了大约一年时间。YouTube的博客写道:“我们很高兴地报告:它已经帮助我们为《泰坦尼克号》和最近的《007:幽灵党》这样的电影提供了非常好的视频传输流。我们不期望任何人注意到这一点,因为他们不知道它看起来还能是什么样。”
参考文献:
Optimizing transcoder quality targets using a neural network with an embedded bitrate model, Michele Covell, Martin Arjovsky, Yao-Chung Lin and Anil Kokaram, Proceedings of the Conference on Visual Information Processing and Communications 2016, San Francisco
Multipass Encoding for reducing pulsing artefacts in cloud based video transcoding, Yao-Chung Lin, Anil Kokaram and Hugh Denman, IEEE International Conference on Image Processing, pp 907-911, Quebec 2015
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}