

GPU挑战CPU地位!详解CUDA+OpenCL威力
[泡泡网显卡频道 12月16日] 众所周知,GPU拥有数十倍于CPU的浮点运算能力,但如此强大的实力多数情况下只能用来玩游戏,岂不可惜?因此近年来业界都在致力于发掘GPU的潜能,让它能够在非3D、非图形领域大展拳脚。
- 1999年,首颗GPU(GeForce 256)诞生,GPU从CPU手中接管T&L(坐标转换和光源)
- 2000年,Hopf在GPU上实现小波变换
- 2001年,Larsen利用GPU的多纹理技术做矩阵运算
- 2002年,Harris在GPU上用细胞自动机(CA)仿真各种物理现象,Purcell第一次使用GPU加速光线跟踪算法
- 2003年,是GPGPU领域具有里程碑意义的一年,Kruger实现了线性代数操作;Li实现了Lattice Boltzmann的流体仿真;Lefohn实现了Level Set方法等一大批成果
- 2004年,Govindaraju在数据库领域应用GPU加速取得进展;商业领域,Apple推出支持GPU的视频工具
- 2006年,首颗DX10 GPU(GeForce 8800)诞生,GPU代替CPU进行更高效的Geometry Shader(几何着色)运算
- 2007年,主流DX10 GPU全面上市,将CPU从劳累不堪的高清视频解码运算中解放出来,如今整合GPU都完美支持硬解码
- 2008年,CUDA架构初露锋芒:PhysX引擎发布,GPU代替CPU和PPU进行物理加速运算;Badaboom、TMPGEnc等软件开始利用GPU的并行计算能力来加速视频编码
- 2009年,CUDA、OpenCL、DX11 Compute Shader百花齐放,GPU将会全面取代CPU进行并行计算,大批应用软件改投GPU门下……
可以这么说,CPU是功能较多的,它几乎可以处理任何事情,但由于深度流水作业架构的特性、以及浮点运算能力的限制,它处理一些任务时的效率很低。纵观近年来GPU的发展历程,就是一步步的将那些不适合CPU处理、或CPU算不动的任务转移过来,从而消除程序运算时的瓶颈,大幅提升电脑执行效能,以更小的代价(成本和功耗)实现更强大的性能。

但是,想要让一大批应用软件从CPU移植到GPU上,非一朝一夕所能完成,需要业界的大力推广以及开发平台及编程语言的支持。NVIDIA早在2005年开始就致力于研发CUDA架构及基于CUDA的C语言开发者平台,并于2007年正式推出,而且专门发布了针对科学计算的Tesla品牌,在GPU计算方面一直处于领跑地位。

而今年由苹果所倡导的OpenCL标准发布后,包括NVIDIA、Intel、AMD在内的所有IT巨头都表示出了浓厚的兴趣。有了统一的标准之后,GPU计算的推广与普及就是水到渠成之事,GPU将会在电脑系统中扮演更重要的角色。
那么CUDA与OpenCL之间有什么利害关系呢?未来谁将左右GPU的发展?GPU会否取代CPU成为计算机核心?笔者通过搜集各方资料,并采访NVIDIA相关技术研究人员,为大家深入分析GPU的通用计算之路。
可能很多朋友还心存疑惑:目前CPU的性能已经很强大了,为什么还要花很大的代价让GPU进行辅助运算呢?这个问题可以从两个角度来回答:一般我们认为CPU在浮点运算/并行计算方面的性能远不如GPU强大,所以将GPU的实力释放出来可以将电脑获得新的飞跃;如果从更深层面考虑的话,目前CPU的发展已经遇到了瓶颈,无论核心架构的效率还是核心数量都很难获得大幅提升,而GPU则是新的突破点,它的潜力几乎是无限的!
● CPU核心效率提升举步维艰
就拿目前Intel最强的Core i7处理器来说,架构方面相比上代Core 2 Quad发生了天翻地覆的变化:胶水四核变成了原生四核、引入三级缓存、高速QPI总线、三通道DDR3内存控制器、超线程技术、诸多内核及指令集优化等等……,所有这些技术共同作用的结果就是——同频率下i7 965的综合性能仅比上代QX9770提升了10-20%,这说明了什么呢?说明Intel的处理器架构已经非常优秀了,以至于在此基础上很难再有Pentium D到Core 2 Duo那种飞跃式提升。

Core i7的性能表现没有带来惊喜
AMD方面的情况也大致如此,Phenom II相比Phenom的提升主要来自于45nm工艺带来的高频率,核心架构优化的贡献仅有不到5%。目前两大处理器巨头单核心效能都已接近极限,只能依靠新工艺带来的大缓存、高频率,而获得微弱的性能提升。
● CPU核心数量不能盲目增加
既然单核效率已经很难取得突破,于是处理器巨头近年来都将发展方向转为多核心产品,双核四核六核八核相继诞生。但美国Sandia国家实验室日前的一项模拟测试却让人大跌眼镜:由于存储机制和内存带宽的限制,16核、32核甚至64核处理器对于超级计算机来说,不仅不能带来性能提升,甚至可能导致效率的大幅度下降。
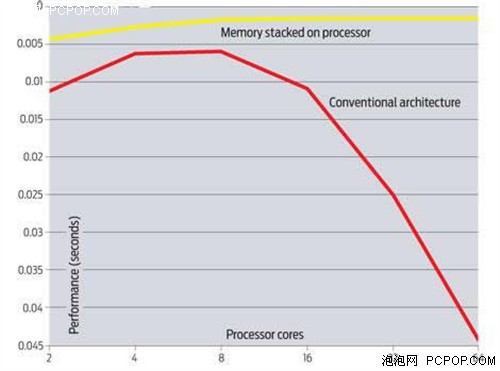
根据他们的模拟,8核心之后再往处理器内塞入更多的核心,并不能带来性能提升,在数据处理应用中反而会出现性能下滑。“16核的表现就和双核差不多”。他们近一年来和业内处理器厂商、超级计算机厂商以及超级计算机用户进行了大量讨论。得出的结论是,如果不对计算机架构作出修改,未来当出现16核32核处理器时,为超级计算机编程的程序员或许只好屏蔽部分核心,或是将这些处理器用于非重点运算应用。
● Intel的"80核CPU"其实是颗GPU
当然业界领袖Intel也意识到了多核CPU发展之路遇到了瓶颈,因此在准备传统六核/八核处理器的同时,也在紧锣密鼓的研制另一种群核处理器——GPU以及类似于GPU架构的混合处理器。

拥有无数颗“核心”的Larrabee图形处理器
就拿Intel代号为“Larrabee”的GPU来说,它是对IA-32(x86)新指令集的一种扩展,其内部是由N颗Pentium处理器核心加上一个16路的向量处理器组合而成的。Larrabee最初的目标是独立显示处理领域,与CPU组合使用。可是Larrabee与GPU相比又有所不同,所谓的Larrabee是能够支持某种程度scalar运算的支持单体OS的CPU。
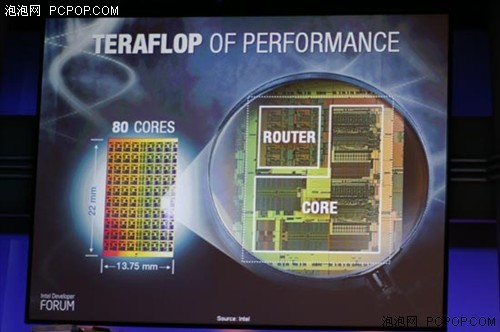
80核心处理器结构示意图
此外,Intel还公布了另一款研发中的80核心处理器实物和架构,事实上这是一颗彻头彻尾的并行计算处理器,每颗核心都包括了两个浮点运算单元,怎么看都像是一颗GPU的架构。从这个意义来看,Larrabee与80核CPU是Intel将来CPU产品的一面镜子。现有的Core 2和Core i7处理器将来会如何向PC&服务器通用处理器进化呢?从这些变种处理器身上我们也可以看到2010年以后Intel的发展方向。
或许我们可以这样认为,未来CPU与GPU之间的界限会非常模糊,多核CPU的架构设计会向现有GPU的模式靠拢,而GPU也不会满足于仅处理一些无聊的3D渲染任务,在特定API及开发平台的支持下,GPU将会取代CPU处理繁重的并行计算任务。
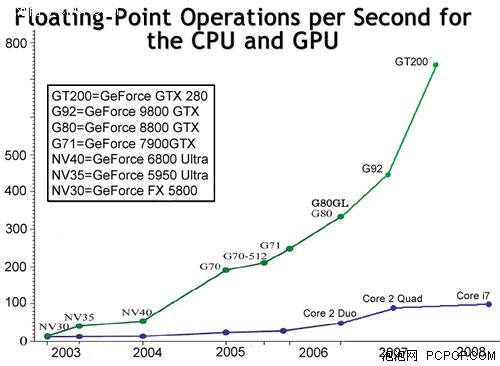
较多核CPU确实很诱人,但只能存在于实验室中,距离我们似乎非常遥远。由于较多核CPU的架构与目前的双核/四核CPU有很大的不同,因此大家不必拘泥于传统处理器的概念。其实较多核处理器“远在天边、近在眼前”——高配置电脑当中肯定拥有一颗GPU(显卡),9800GTX+是128核心、GTX280则拥有240颗核心,GPU的每一个流处理器就是一颗核心。
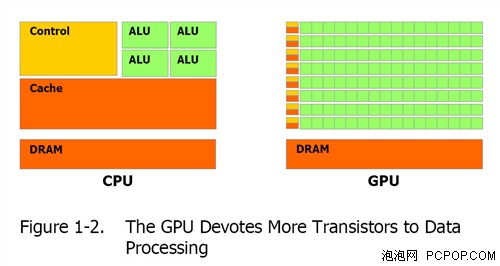
目前X86架构的处理器经过30年的发展,指令集、平台、系统和软件支持已经接近完美,因此使用CPU处理数据是天经地义的。GPU虽然也诞生了近20年,但它从来都只能渲染图形,想要让他进入全新并行计算领域,无论硬件架构还是软件平台都需要作相应的调整。
● GPU在硬件架构方面的进步
传统GPU的核心组成部分是Shader(着色器),分为Pixel Shader(像素单元)和Vertex Shader(顶点单元),每一个Shader是一个4D或5D的矢量运算单元,之所以设计成这样是因为在图形处理中,最常见的像素都是由RGB(红黄蓝)三种颜色构成的,加上它们共有的信息说明(Alpha),总共是4个通道。而顶点数据一般也是由XYZW四个坐标构成,这样也是4个通道。在3D图形进行渲染时,其实就是改变RGBA四个通道或者XYZW四个坐标的数值。为了一次性处理1个完整的像素渲染或几何转换,GPU的像素着色单元和顶点着色单元从一开始就被设计成为同时具备4次运算能力的运算器(ALU)。
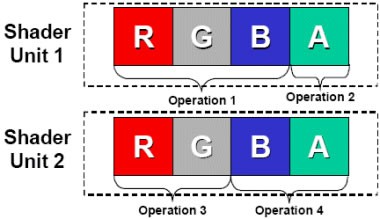
传统Shader结构的GPU只适合做图形渲染
这样的4D矢量运算单元在渲染3D图形时会有很高的效率,但在处理复杂指令时的效率会大打折扣,比如DX10新引入的几何着色、物理加速等,尤其在面对非图形渲染指令时优势全无。
NVIDIA的科学家对图形指令结构进行了深入研究,它们发现标量数据流所占比例正在逐年提升,如果渲染单元还是坚持SIMD(单指令多数据流)设计会让效率下降。为此NVIDIA在G80中做出大胆变革:流处理器不再针对矢量设计,而是统统改成了标量ALU单元。用通俗的话说就是:Shader单元内部ALU完全打散,设计成为各自独立的流处理器,并分配相应的指令发射端和控制单元,这样的架构在面对任何形式的指令(包括组合指令)时都能保证最高的执行效率,这也就是NVIDIA在DX10时代游戏性能大幅领先于竞争对手的根本原因!
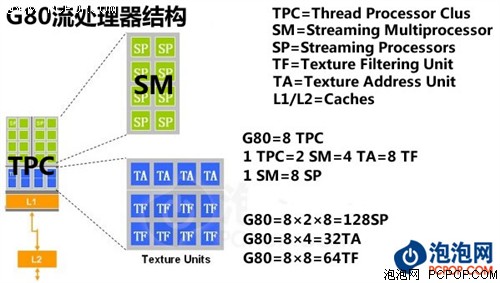
随着图形画面越来越复杂,1D、2D、3D指令所占比例正在逐年增多,而G80在遇到这种指令时可说是如鱼得水,与普通4D指令一样不会有任何效能损失,指令转换效率高并且对指令的适应性非常好,这样G80就将GPU Shader执行效率提升到了新的境界!
这种富有弹性的架构不仅拥有很强的图形渲染能力,而且能够处理以往不敢奢想的非图形运算指令,理论上来讲只要是浮点运算指令都可以交给GPU来处理。而在以往,程序员必须针对GPU的架构特点,对指令重新分类打包并模拟图形指令交给GPU处理器,工作量可想而知,效率也极为低下。
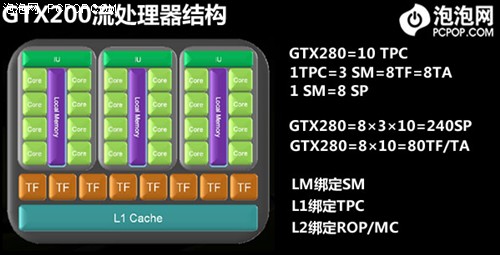
G80的架构无论对于图形渲染还是并行计算都是革命性的,但NVIDIA并没有满足于此,为了进一步提高GPU的并行计算效能,把GPU改造成为一颗真正的通用处理器,NVIDIA在GTX200核心大规模扩充流处理器数量的同时,也对内核架构进行了诸多优化与改进,使之更适合做超大规模并行数据处理。

GTX200核心的主要改进有:
- 每个SM(8个流处理器为一簇)可执行线程从768提升至1024条;
- 每个SM的指令寄存器容量翻倍,从16K提升至32K;
- 将双指令执行(Dual-Issue)效率提升至94%,接近于理论值;
- 512Bit显存控制器,4GB显存容量支持,防止指令排队溢出;
- 支持双精度64Bit浮点运算,55nm版GTX200的双精度运算能力提高4倍!
以上所有的改进(显存位宽除外)并不会让GTX200核心的图形渲染能力得到提高,但却能够大幅提升GPU在进行海量数据处理时的效率。由此我们可以看出NVIDIA的野心与实力——G80与GTX200已经不再是一颗图形处理器,而是较多核通用处理器!而NVIDIA这种图形架构与并行计算架构合二为一的架构就被称为CUDA。
任何硬件想要尽情地发挥性能离不开软件的支持,GPU光有优秀的架构还是远远不够的,如果没有驱动和软件的支持那就是一纸空谈。所以,NVIDIA在G80核心发布之后,一直都在想方设法地释放这种架构的能量。
● GPU在开发平台方面的进步

于是,CUDA的概念诞生了,CUDA是Compute Unified Device Architecture的简写,中文含义是统一计算设备架构,它是建立在NVIDIA GeForce 8架构基础上,并在GeForce 9和GTX200架构上改进优化并发扬光大。

CUDA是NVIDIA推出的一个并行计算架构。这个架构包含有一个ISA(指令集架构)以及并行计算的硬件引擎。就如同CPU的情况一样,X86的架构也包含ISA和执行指令的硬件架构。各种应用程序都基于这个架构进行开发并在此上运行。可以说CUDA架构的GPU是图形渲染架构与并行计算架构的合体!
NVIDIA提供的CUDA开发包中的C语言编译器版本更新很快
CUDA本意就是一种架构,但很多人认为CUDA是一种语言、或者是开发平台,这可能跟NVIDIA最初的宣传、推广策略有关系。在CUDA架构诞生之初(GeForce 8时代),尚不存在专门针对GPU并行计算的开发平台以及编程语言,因此NVIDIA必须给程序员提供一种简单、易上手、并且完整的软件开发解决方案,这样NVIDIA所发布的CUDA包当中就包括了针对GPU的C语言编译器、纠错器/制模器、专用驱动和标准函数库等。

除了支持自家C语言编译器之外,更多的语言及API都能运行在CUDA架构上
现在,越来越多的厂商和开发者意识到了GPU计算的重要性,于是各种开发语言及应用程序编程接口应运而生了,其中除了CUDA编译器所提供的C语言之外,大家所熟知的Fortran、C++也会支持高性能GPU并行计算,另外近期发布的OpenCL及未来的DX11也会专门针对GPU开发相应的API。在整个产业的共同推动下,GPU计算可谓是前途无量!
不难看出,正是对于GPU通用计算敏锐的嗅觉以及前瞻性,让NVIDIA站在了业界的前沿,并且加速了整个行业的发展。
NVIDIA有优秀的CUDA架构,还有自行开发的CUDA C编译器,而AMD只强调开源,因此AMD在很早之前就对CUDA嗤之以鼻,并对OpenCL寄予厚望。然而NVIDIA对于OpenCL的热情反而远比AMD高涨,OpenCL标准出台后就一直赞不绝口,并大力推广,这是为什么呢?

OpenCL一经提出就受到业界的大力支持
首先,CUDA是一种架构,OpenCL是API(应用程序接口),两者是完全不同的概念,不存在竟争关系。既然OpenCL标准能够进一步拓展GPU的应用领域,NVIDIA没有理由不支持,事实上这也正是CUDA架构的设计初衷。
其次,OpenCL标准的倡导者——苹果,是NVIDIA的亲密合作伙伴,苹果新一代MacBook将会全面采用NVIDIA的GeForce 9400M GPU以及GF9300整合GPU。NVIDIA还是第一家展示运行中的OpenCL程序的公司,NVIDIA的GPU自然能够对OpenCL提供完美支持,拥有非常好的的并行计算效率。
最后,NVIDIA是OpenCL的标准制定者之一,NVIDIA公司副总裁Neil Trevett担任Khronos OpenCL工作组的主席,该组织中还有多位骨干成员都是NVIDIA员工。

AMD在内部文档中暗指NVIDIA的CUDA为“封闭技术”
由此可见,与大方空话、诽谤竞争对手的AMD相比,NVIDIA显然要务实很多!在公开标准尚未出台之前,NVIDIA CUDA架构及C编译器早已准备就绪,在GPU计算大势所趋的情况下CUDA受到了开发者及科研人员的一致好评;在OpenCL标准制定过程中,NVIDIA也扮演着举足轻重的角色,并担负起改进与推广的重任;与此同时,对于微软正在开发的DirectX 11,NVIDIA也积极参与其中,绝不放弃任何能够拓宽GPU市场的标准。
不管未来CUDA C语言、OpenCL API以及DX11 Computer Shader谁将成为业界标准、谁的使用率最高,NVIDIA都是GPU并行计算坚定不移的支持者,并对所有的语言及API提供完美支持,就像现有GPU同时支持DirectX 10及OpenGL图形API一样。
理清CUDA架构及OpenCL API之间的关系之后,再来研究下CUDA C语言与OpenCL之间的优劣,两者有很多相似之处,存在着竞争与互补的双重关系,但对于GPU硬件架构(如CUDA)来说是无差别的。
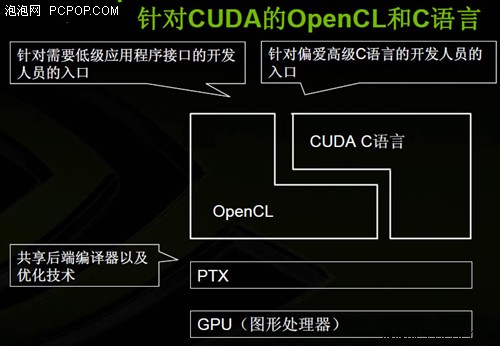
CUDA C语言与OpenCL关系示意图
NVIDIA认为CUDA的基本理念因OpenCL的出现得到了增强。两者的根本原理都是一样的,但OpenCL是一种更底层的架构,需要开发人员自行编写内存管理等等功能的代码,而CUDA则可以让那些非专业编程人员如科研工作者更简单的编制GPGPU程序代码。

CUDA C语言与OpenCL的编程模式不同
简言之,CUDA C语言与OpenCL的定位不同,或者说是用人群不同。CUDA C是一种高级语言,那些对硬件了解不多的非专业人士也能轻松上手;而OpenCL则是针对硬件的应用程序开发接口,它能给程序员更多对硬件的控制权,相应的上手及开发会比较难一些。
另外程序员的使用习惯也是非常重要的一方面,那些在X86 CPU平台使用C语言的人员,会很容易接受基于CUDA GPU平台的C语言;而习惯于使用OpenGL图形开发的人员,看到OpenCL会更加亲切一些,在其基础上开发与图形、视频有关的计算程序会非常容易。

所以说,CUDA C语言与OpenCL是各有所长,是互补而非竞争关系,不会发生一方取代另一方的情况。就拿成熟的X86 CPU架构来讲,各种开发语言不胜枚举,C、C++、Basic、Fortran、Java……,每种语言都有自己的特色、都能找到适合自己的领域。现在针对GPU架构的语言及API还不够多,目前仅有的CUDA C语言和OpenCL都还处在起步阶段,相信未来会有更多的语言/API移植到GPU上来,CUDA架构为此已经做好了充分的准备。
关于GPU并行计算,其实AMD比NVIDIA更早提出了GPGPU(通用GPU)的概念,那么NVIDIA怎么看老对手AMD在并行计算方面的发展呢?现在我们就看看NVIDIA技术人员对于AMD的评价。
● 衡量GPU并行计算的主要指标就是浮点运算能力,根据理论值来看,AMD GPU似乎要比NVIDIA GPU高不少(HD4850达到1TFLOPS、HD4870 1.2TFLOPS),那NVIDIA GPU的优势是什么?
答:的确,GPU的浮点运算能力非常重要,但这只是理论值而已,理论与实际存在很大的差距,尤其是在GPU架构截然不同的情况下,几乎没有可比性。目前超级计算机500强的排名是使用统一的软件进行评估获得的实际浮点运算性能,而并非理论值,采用NVIDIA Tesla GPU的超级计算机初出茅庐就排行第29,实际运算能力得到了充分肯定。
任何架构都有效率高低之分,GPU也不例外,NVIDIA CUDA架构的GPU执行各种复杂的图形指令及非图形指令都有着非常高的效率,而竞争对手的产品听起来拥有较多的流处理器、理论浮点运算能力也很夸张,但实际性能如何呢,通过最新DX10游戏来看其效率很低,GPU的本职工作都做不好,何谈指令更加复杂的并行计算呢?
● 科学研究对运算精度要求非常高,双精度浮点运算使用率很高,NVIDIA GPU的双精度运算能力只有单精度的1/8,而AMD双精度性能是单精度的1/5,这是为什么呢?
答:确实,在不少应用领域都须需要双精度浮点运算,这方面NVIDIA上代GPU做得还不够好,当初主要考虑提升单精度浮点运算的能力和效率,在民用场合会得到非常出色的效能(比如视频转码、物理加速等)。
不过,新一代Tesla产品的双精度浮点运算能力将会提高至原来的4倍之多,新一代核心不仅仅是工艺改进频率提升而已,事实上我们对内核架构作了进一步优化,每个SM内部FP64运算单元达4个,这样NVIDIA下一代GPU的双精度浮点运算能力可以达到单精度的1/2,性能提升非常可观!
● 对于AMD的FireStream流处理加速卡,NVIDIA怎么看?
答:AMD FireStream比NVIDIA Tesla诞生得早,但由于架构和开发平台问题,市场占有率及用户认可度根本无法同Tesla相提并论。大家看到的多是有关产品方面的报道,而不是有关应用及解决方案方面,因为AMD根本拿不出什么像样的应用软件,目前最流行的Folding@Home蛋白质分布式运算以及AVIVO视频转码,其实早在X1000时代就存在了,时至今日产品更新换代了三四代,但GPU运算效率并没有得到提升,为什么呢?
因为AMD没有给用户提供一种系统的开发平台,而是仅使用汇编一类的低级语言去进行GPGPU编程,这样的开发效率极低,而且移植起来非常困难,针对不同架构的GPU需要重新编写软件才能提供支持。举个最简单的例子,HD4000刚发布时候的Folding@Home运算效能甚至还不如HD3000,要知道HD4000的理论性能是后者的2.5倍之多!
可以这么说,AMD的GPU架构纯粹是针对图形渲染设计的,而且很落后,因为NVIDIA很久以前的NV30就是这种SIMD架构,并行计算只是AMD图形架构的副产品,所以AMD在面对并行计算时能有多高的效率值得怀疑。或许OpenCL的出现能给AMD一些机会,但AMD有的NVIDIA都有,而AMD没有的正是NVIDIA的强项,优秀的CUDA架构再加上各类编译器/API可以让NVIDIA GPU大放异彩!
前面我们曾提到过,Intel未来较多核CPU的架构,将会吸取传统CPU与GPU的优势,重点提升浮点运算能力,而Intel也在紧锣密鼓的研发自己的GPU,那么GPU与CPU在未来会发生什么变化呢?是GPU取代CPU,还是GPU与CPU合二为一?
● GPU不会取代CPU,但CPU的重要性正在削弱,GPU扮演更重要的角色
NVIDIA认为GPU是不会取代CPU的,CPU作为中央处理器仍然占有相当重要的位置,GPU只能处理大规模多线程的并行计算,并不是所有的程序都能良好的运行在GPU上,但几乎所有的程序都有运行在CPU上的优秀代码。
不过并行计算对于处理器性能的渴求几乎是无止境的,也是未来推动电脑系统持续高速发展的重要动力,由于CPU在这方面的欠缺,CPU的价值正在快速下滑,随着CUDA及OpenCL走向成熟,未来为GPU和并行运算优化的程序将大行其道。
试想,如果视频编码解码、物理加速、科学计算、穷举算法、数据库分析等这类对CPU要求极为苛刻的应用,都改用GPU来处理器的话,谁还愿意去花那么多钱购买一颗四核CPU呢?四核CPU并不会让操作系统及日常应用变得更快,此时高端显卡将会吸引游戏玩家以外更多用户的注意。
● 整合意味着低端,高性能电脑不需要也无法整合
GPU的重要性是毋庸置疑的,要不然AMD就不会收购ATI,Intel也不会到处挖墙角去研发自己的独立GPU了。在独立GPU高速发展的同时,我们也注意到AMD和Intel相继公布了CPU与GPU整合计划,那么GPU将何去何从呢?
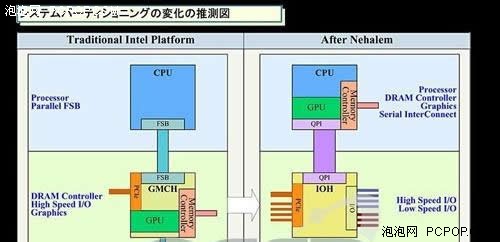
整合就意味着低端,只保证基本的功能、而不在乎性能,目前主板上的整合显卡、声卡、网卡、Raid控制器等无不是这种情况。目前AMD和Intel公布的CPU整合GPU计划,道理其实就跟内存控制器从北桥转移至CPU内部一个道理,原本北桥整合的GPU被纳入CPU之中,这样有助于提高整合显卡性能,并降低生产制造成本。

GPU核心远大于CPU,谁整合谁还很难说呢?
但是想要在CPU之中包含一颗高性能的GPU是不可能的,半导体制造工艺不允许,内存带宽更不允许!我们知道中高端GPU的晶体管与核心面积要比CPU大很多,目前GTX200核心已经达到了65/55nm制造工艺的极限,要是能放入更多的晶体管早就诞生更强大的GPU了,何需等待?此外GPU对需要海量内存带宽的支持,现有的双通道/三通道DDR3根本就是杯水车薪,连CPU都满足不了还想整合GPU进去?
所以,CPU整合GPU计划本来就是定位中低端,这种解决方案很有创新意义,也会给用户带来很多实惠,但并不能影响到未来主流中高端CPU与GPU的发展。

Tagra处理器架构图
当然,CPU也有可能被GPU整合,NVIDIA针对移动计算平台发布的Tagra处理器就是很好的例子,通过它的模块及架构设计来看,所有的处理模块和功能模块都被整合在了一起,按照比重来看应该说是GPU整合了CPU。未来类似于类似Atom一类的顺序架构小型处理器被Chipset或GPU整合起来也很难说。
● 保持现状,CPU+GPU异构计算引领发展
GPU的重要性与日俱增,但CPU的核心地位依然是无法撼动的,所以,在未来很长一段时间内还会保持CPU与GPU各自独立发展的现状不变,继续在各自擅长的领域发挥热量。

而计算机性能提升的方法,就来自于API和语言对GPU性能的释放,未来无论是OpenCL 1.1还是CUDA 3.0,都会同时支持CPU与GPU的资源管理,合理分配指令与任务,只有充分调动所有的硬件模块、消除瓶颈,才能释放出最强性能!<
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}