

宝剑锋自磨砺出!细谈RV770背后的故事
● 重新评估策略:2005年设计RV770
记住导致成功的因素比记住成功更重要。2005年ATI的处境和当初设计R300的时候相似。R300的成功是因为ATI重新评估了制造GPU的策略。在那个时候,ATI决定造一颗大芯片来赢得高端,并将其转化为每一个价格区间都有竞争力的产品。值得一提的是R300的持续成功还部分归因于NVIDIA在GeForce FX上的失败。这是ATI上演的完美风暴。ATI造了一颗最大的GPU,NVIDIA在其后的一段时间里无法回应。正如Intel在试图疯狂提高P4的频率时撞上了功耗墙。但是2005年时,ATI开始发现GPU(当时ATI还称核心为VPU)过于庞大了。设计周期越来越长,芯片面积不断增长。制造如此大的GPU已经不是那么合算了。
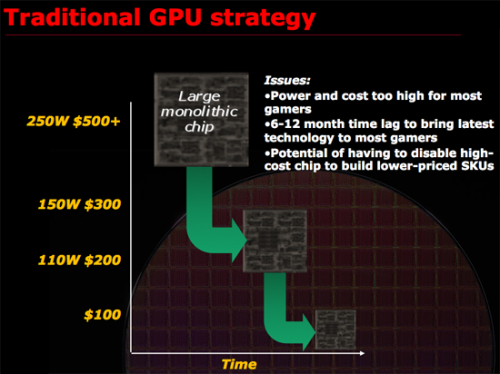
设计芯片技术不是唯一,设计策略才是大局转变的关键
AMD认为一颗非常大的GPU,如果没有使用Repair Structures和Harvesting(两种技术我稍后会讨论)的话,只有30%是可用的。也就是说,对一片晶圆而言,每100个GPU只有30%是功能完好,可以零售的。制造如此复杂的电路成本是非常昂贵的,那些Fab的设备造价很容易就达到数十亿美金。所以不能让如此多的晶圆被浪费。谢天谢地有技术可以让30%可用变成90%可用。第一种技术称之为可修复性(Repair Structures)。
其思想非常简单:设计冗余单元。如果芯片某个功能单元包含10个流处理器,实际上要设计11个流处理器。如果有瑕疵出现那么我们可以启用那个备用的流处理器。这种技术通常也用在片上内存(on-die memory)的设计上。这样当某一部分出现问题时,不会导致整个功能单元不能用。但是这个地方通常有个折中,如果你设计了太多的冗余单元,那么你就面临着芯片面积太大的风险,并且这些增大的面积对实际性能毫无贡献。但是如果你设计的冗余单元不够,那么你的良品率就不足。
第二种技术称之为Harversting,所有人肯定都很熟悉。其思想是:假设一片晶圆上功能完好的芯片只有很少一部分,但是我们并不丢掉那些有瑕疵的芯片,我们关闭某些功能单元,然后把他们当做低端芯片卖。例如,如果你设计某个功能单元包含了10个流处理器,预期只有30%的产品是10个流处理器都可用,50%的产品可用其中的8个。那么你可以把8个流处理器可用的芯片当做稍微低端的芯片卖。因此这种方法使得一片晶圆上80%的芯片都可用,如果可能的话,你还可以屏蔽更多的流处理器单元,使得接近100%的芯片都可用。良率会随着时间改善,如果你一直依赖于Harversting,那么这种方法最终会损害你的财务表现。在上面的例子中,随着良率的改善,越来越多的芯片10流处理器可用,但是你还是只能当成8流处理器卖。某种意义上说,值一块钱的东西你卖八毛钱。当然你也可以设计8流处理器的新版本,但是这会耗费额外的时间、金钱和工程师资源。
GT200系列就是采用Harvesting技术的典型。GeForce GTX260就是GTX280的Harvesting版本。随着良率的改善,NVIDIA推出了GeForce GTX 260+(216 SP)。但是要注意并没有为GT200系列设计任何的冗余单元。因此GT200系列的芯片上最多有240个流处理器,如果240个流处理器不能用的话,那么就当成GTX260或者GTX260+来卖。与之形成鲜明对比的是RV770系列,两个版本的RV770功能单元的规格都是一致的,所不同的只有频率和功耗的不同。从芯片的角度来看,AMD不必通过卖缩减版本的产品来保证良率(编者按:估计AnandTech站长当时还不知道Radeon HD4830)。注意,一家公司是否采用Harvesting技术并不会影响终端用户。
在这种情况下,GeForce GTX260/260+实际上对终端用户是有利的,因为它具有和Radeon HD4870同样的价值。但是它无助于改善NVIDIA的财务表现,如果一家公司长期依赖于Harvesting策略的话,最终是要付出代价的。但是我怀疑NVIDIA会在事情变坏之前用55nm的GT200版本使自己全身而退。AMD并不想设计一颗GPU过度依赖于靠Repair和Harvesting来提高良率。于是一个杀手级的论断出炉:制造大型的GPU并非最符合客户利益。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}