

GPU计算:复杂多相流动分子动力学模拟
[泡泡网显卡频道 2009年2月17日]分子动力学(molecular dynamics,MD)模拟是随着计算机技术的发展而兴起的一种科学计算方法,现已应用到广泛的领域中,如医药、材料、能源、机电等。随着纳米、微机电和微化工等技术的兴起,纳微流动的MD模拟近年来也成为热点。传统连续流体力学难以处理和解释这些尺度上的独特性质与现象,而流动归根结底是流体分子的集体行为,MD模拟能详细跟踪每个分子的运动,并通过分析速度、温度等统计性质阐释理论中的难点、发现新的机理,故日益受到重视。
● 挑战
但是,计算能力一直是制约此研究发展的瓶颈。现在这方面很多成熟算法都基于传统体系结构的中央处理器(CPU),但其发展已显颓势。图形处理器(GPU)的计算能力现已远高于CPU一到两个量级。如何在MD流动模拟中利用GPU的强大能力已成为一个重要的现实课题。
● 解决方案
中国科学院过程工程研究所多相复杂系统国家重点实验室进行了图形处理器(GPU)上的分子动力学(MD)模拟。即利用配备了一片NVIDIA Tesla? C870的服务系统来运行NVIDIA CUDA?架构, 通过方腔流及颗粒-气泡接触等实例初步展示了此方式从微观上模拟介观行为的能力。经证实,在NVIDIA公司技术助力下,该计算过程速度是以往运用单核CPU计算的20到60倍,最高可达150 Gflops。
传统GPU对非图形应用支持有限,只能通过图形API编程,内存带宽较低且访问限制多,从而制约了其性能发挥。NVIDIA CUDA的发布打破了传统GPU的性能瓶颈,提供了新的软硬件架构。本次模拟的多相体系中,CUDA把GPU直接视作数据并行计算设备而不再将计算映射到图形操作上,以扩展性较好的区域分解和常用的消息传递接口(Message Passing Interface, MPI)协议实现各节点间GPU的并行计算,以类C语言的方式给开发者更大自由来实现GPU算法。CUDA还能结合OpenMP,MPI和PVM等其他并行方式在节点内和节点间继续扩展计算能力,更好的发挥了GPU的强大性能,并将计算中的数据访问效率提高了一个量级以上。Tesla C870的有效计算性能(指计算分子对相互作用时的浮点操作数)是以往所采用的单核CPU的20~30倍。若考察极端情况,即只测试耗时最长的分子间作用力计算,GPU更占优势, 约能发挥150 Gflops,占其可利用计算峰值(346 Gflops)的40%多,而CPU能发挥2.4 Gflops,GPU的计算能力达到CPU的60倍之多!说明GPU很适合像多体问题。
● 影响
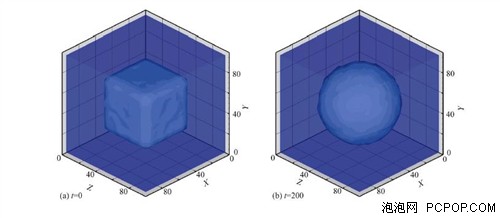
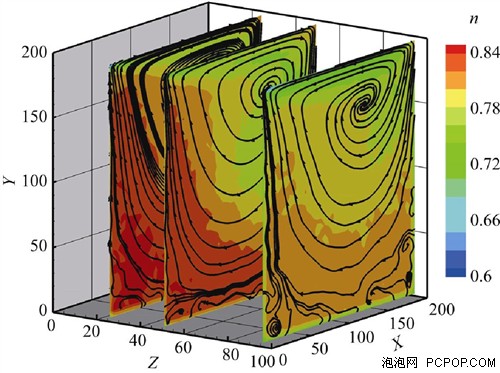
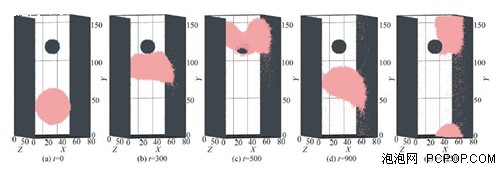
方腔流是流体动力学的一个经典问题,本次模拟将GPU应用于方腔流的MD模拟,使得模拟体系的规模有较大提高,在一定程度上达到了(亚)微米尺度,沟通了连续的流体力学和离散的分子动力学。而多相纳微流动研究对纳米、材料、生物、微机电与微化工系统等技术领域更有实用性,但也更有挑战性,目前还没有成熟的理论方法,其MD模拟需要更多的计算资源且实现更加复杂,因此GPU的应用显得更有价值。另一方面, 利用CUDA技术和MPI协议,MD模拟可以实现某些物理实验难以进行的极端情况,这是MD模拟非常值得关注的新方式。总体来说,GPU在MD模拟上的应用还有巨大的潜力。■
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}