

X86架构的GPU?解读Larrabee规格特性
去年,我们感受到了3D领域的新成果。硬件方面,一方是NVIDIA的全新架构——GT200,依旧是性能至上的设计模式,再通过阉割等手段推出不同定位显卡;另一方面是AMD的全新设计理念,设计初衷就是中端理念,协调性能与价格之间的关系,高端领域通过“双芯”设计这一捷径完成。软件方面,微软的DX11也即将伴随着windows 7而来,带来全新的图形体验。

虽然3D领域看似热闹非凡,但似乎少了什么,作为世界靠前芯片企业——Intel,虽然在全球显卡市场占有率上占据绝对优势,但实际上都归功于整合主板的的功劳(OEM厂商出量产品集成显卡占绝对优势),在3D领域的前沿,独立GPU并没有什么作为。

十年前的i740
对于一家以芯片技术见长的企业,这种现状是不能忍受的。造成这样的情况要从十年前说起,当时,Intel草草推出了一款独立显卡i740,当时的情况,可以说是显卡领域群雄争霸的黄金时代,除了两家较大的公司NVIDIA和ATI外,Matrox的幻日Parhelia、3DLabs的Realizm,XGI的Volari以及奄奄一息的3DFX的巫毒,当时可谓是群雄争霸的年代,而GPU这种产品,需要持之以恒的大量物质投资和人力资本,只有少数几个大公司才能负担,而当时的Intel,正和AMD争斗GHz的桂冠,无暇顾及显卡,所以只能饮恨转型至集成领域。
时至今日,Intel依旧对larrabee犹抱琵琶半遮面,这其中的原因是复杂的。首先,GPU和CPU是有差异的,虽然Intel的开发实力不容置疑,但要想短期内追赶上AMD和NVIDIA也是不现实的。其次,GPU研发需要大量资金做后盾,虽然Intel不差钱,但投资没有产出的话,何必做呢?

现在的市场和十年前不同了,当时市场,还没有统一的业界标准,各方对GPU的重要性认识不同,当时的3Dfx, Nvidia, and PowerVR认为GPU会成为未来PC的主旋律,而另一些GPU厂商Matrox, S3, and ATI则认为GPU仅是的3D加速器而已。这种混乱的状态也是促使Intel放弃独立GPU的一个原因。
到现在,这个问题已经十分明朗了,业界对GPU的看法较之前已经很大的改变。在NVIDIA的推动下,基于GPU类的通用计算已经有了一些眉目,GPU不再是3D游戏的附属品了。

GPU通用计算的应用——蛋白质分析
虽然我们仍旧在摩尔定律下生存,但不得不承认,现在PC换代升级后的性能提升感受已经大不如前,以core2升级core i7为例,用户实际性能感受并不明显。其中的原因是多方面的,系统、CPU架构改变难等。现在的PC系统,CPU性能即使提升再多,也不是很明显,从游戏来看,高端4核与中端双核的表现相似,而游戏性能更多取自于GPU,从应用来看,在多密集型运算中,GPU较CPU有得天独厚的优势,这些都是促使Intel重返GPU领域的原因。
首先要说明的是,larrabee并不是传统意义上的GPU,本质上讲,它就是CPU,由多颗X86架构的CPU通过环形总线并行组成,接替传统GPU的功能。
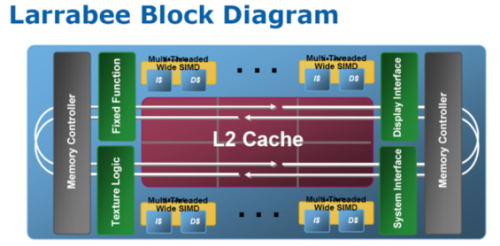
从上图我们可以看到,在Larrabee的内部,每一个处理核心都可以发出2条指令,这种架构是继承了最初的奔腾处理器的设计。在老奔腾的基础上,Intel的工程师们也作了许多修改和提升。首先让老Pentium核心可以支持64bit指令处理,提升了x86指令集的处理,为处理核心加装了更大容量的高速缓存。另外还支持4路SMT/Hyper Threading超线程和16路矢量ALU算数逻辑单元。
类似IBM的cell处理器,Intel吸取了一些经验来设计Larrabee。为了避免高频带来的困扰,发热量加大,功耗升高等,Larrabee的设计思路是多路并行,即通过多核心来提高性能。
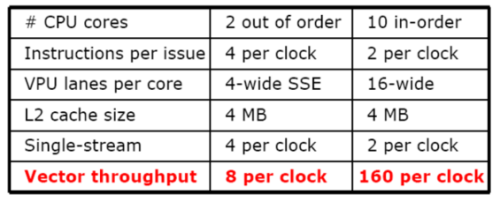
core2与Larrabee的对比
通过上表我们可以比较Core2与Larrabee的数据吞吐量,理论上说明每个时钟周期之内,多核心处理器可以处理更多的数据和指令。运行一个单一的指令流,例如单指令的应用程序,那么Core 2处理器每个时钟周期可以执行4次操作,每个时钟周期可以发出4条指令,但是执行单元无法在每个时钟周期内执行4条指令。在10核心的架构中,尽管它每个时钟周期仅仅可以发出2条指令。在一个单指令流的程序中,它的峰值是每个时钟周期2次操作。仅有Core 2处理器的一半。但Core 2处理器只有2个处理核心,每个核心在每个时钟周期内可以执行4个SSE指令,那么Core 2总计每个时钟周期可以进行8次操作。但是具备10核心的Larrabee就大不一样了。它每个时钟周期可以执行160次操作,这相当于20倍Core 2的数据吞吐量。
架构的东西设计的再好,没有优良的核心效率也是不行的。那么,larrabee的核心较“CPU”有什么变化呢?

以现在的GPU计算能力来看,使用类似奔腾架构为核心larrabee,即使数量再多也不能占据性能优势,因此Intel通过支持4路SMT/Hyper Threading超线程和16路矢量ALU算数逻辑单元,以及自己的拿手绝活——最大限度地添加L2缓存。加强了核心浮点运算的能力。

并发超线程技术,我们已经在i7身上看到了其效能,在多路测试中表现出了抢眼的效果,而将这项技术运用于基于并行运算理念设计的GPU身上,无疑是如虎添翼。相信只要编译器得到,larrabee的并行运算效率至少不会比现有的GPU差。
对GPU来说,检验其性能较好的测试莫过于实时演算了,这也是为什么各路厂商都乐于在3D mark上比拼得分了。在统一的测试环境下,得出相对公正的性能得分。
虽然我们暂时不能领略Larrabee的3D mark得分,但Intel官方还是放出Larrabee的实时演算视频:
看过以上介绍的larrabee规格,拥有强悍的通用性,以及丰富地市场定位,似乎Intel这辆蓝色坦克要将GPU这块失地重新夺取回自己手中。但即使这是Intel巨人说的,我们也要保持冷静的头脑。
任何产品,但凡仅是存在纸面上,那么对其就要打个问号!当年的安腾,曾被认为是未来处理器的发展方向,但结果呢?全新的架构给操作系统带来了难以逾越的考验,与应用存在一定距离,最后退出市场也不难理解了。
所以现在对larrabee进行评价是不客观的,盲目地接受或否定一项新技术,都是不正确的。但不可否认的是,larrabee对Intel来说,是迫切的产品,即使第一代产品的性能达不到理想程度,但赶上通用计算这趟列车,是最重要的。<
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}