

红色帝国的激进美学!ATI先进技术解读
天涯上有一篇访问量过百万的帖子,不知道大家看过没有,标题叫做“寻找男人的世界一:落日余晖——追忆红色帝国的暴力美学”,讲得是前苏联设计的一些令强大的美帝也闻风丧胆或自叹不如的恐怖玩意,有成功的也有失败的,但无一不是经典之作,比如:米格25超高音速战斗机、赫鲁晓夫超级氢弹、N1霸王登月火箭、台风级核潜艇等等。
军事是男人的世界,硬件同样是男人的世界,笔者每天都在与硬件打交道,看完此贴后突发奇想,感觉这个“红色帝国的暴力美学”用在ATI身上是最合适不过了,ATI虽然已被AMD收购,ATI显卡虽然在市场占有率方面处于弱势地位,但其显卡的设计风格以及对技术执着的追求却丝毫没有改变。ATI带给我们的经典和惊喜一样多,很多产品和技术都让强大的NVIDIA头痛不已,令以图形技术领袖自居的NVIDIA马不停蹄的追赶……

ATI显卡虽然谈不上暴力,但也足够激进了,因此本文就斗胆套用天涯精华贴的标题,列出十项近年来ATI显卡的经典设计和技术,每一项都足以让对手汗颜,最终不得不跟进,从而推动了GPU图形技术的发展,并带给用户更完美的显卡。

为让评测文章更具参考价值,同时也让广大网友能够看到自己最感兴趣的内容,泡泡网DIY评测室特意开设了“You Think.I do”板块,您可以将最感兴趣的内容、甚至任何想法发送到邮箱“Think@PCPOP.COM”,我们会有针对性地挑选网友关注的热点进行评测,一旦您的建议被采纳,在评测文章发布之日我们会为您送出精美礼物一份!
往日经典文章回顾:



一、ATI显卡先进技术回顾:GPU工艺的领头羊/新制程开路先锋
为了让GPU拥有更强的性能和更多的功能,就必须在核心中植入更多的晶体管,而大规模晶体管的代价就是无可避免的功耗和发热,为了解决功耗发热问题,使用更精密的工艺是最好的出路。
ATI一直以来都是新工艺的领头羊,相对于竞争对手而言,几乎就是全面的压倒性优势,始终令对手戴着保守与落后的帽子。远的就不提了,就从DX10芯片开始说起吧:
● DX10第一代:RV630/RV610率先使用65nm


R600(80nm)核心面积432mm2,G80(90nm)核心面积496mm2


RV630(65nm)核心面积148mm2,G84(80nm)核心面积160mm2
ATI首颗DX10图形核心R600就使用了80nm工艺,而保守的NVIDIA在G80上还是使用过时90nm工艺。先不论性能谁胜谁负,在工艺上就慢了半拍。就在NVIDIA主流型号G84/G86都提升到80nm的时候,ATI对应的RV630/RV610等一系列产品都已经走入了65nm的行列。
● DX10第二代:RV670/RV635率先使用55nm


RV670(55nm)核心面积比G92(65nm)小很多
当NVIDIA一再抨击工艺不重要,唯性能论时,自己也在暗度陈仓,悄悄的在G98核心上低调的试水65nm工艺,而后终于在中高端主力G92核心上大规模使用65nm工艺。NVIDIA本以为在工艺上终于可以与ATI齐头并进的时候,ATI最新的RV670已经开始投产,这次的高端芯片甚至跳过了65nm而直接步入了55nm的新高度,时至如今,ATI全新的RV790核心依旧走在55nm的前列。
● DX10第三代:RV740率先使用40nm,GPU工艺首次超越CPU
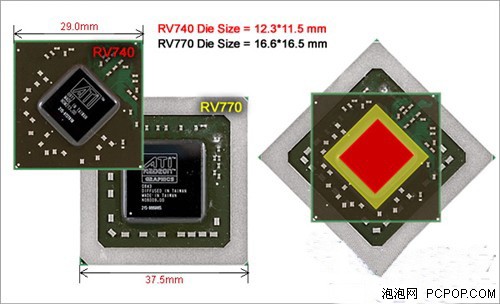
40nm的RV740新品为ATI将要推出的RV870芯片充当开路先锋
今年上半年,基本上两大图形芯片都在55nm工艺的道路上前行着,不过NVIDIA的55nm工艺来得较慢一些,最早是逐步通过原有的65nm G92核心升级到55nm G92b一路过来的,之后的高端产品GT200也是渐渐的升级到55nm,到如今NVIDIA才刚刚把全部阵营统一到55nm行列,整整慢了一年。不过,这时的ATI最新推出的RV740又震慑了我们一把,再次将现有新品工艺提升到40nm,意义不仅是在图形芯片上超越了对手,也是首度超越了CPU 45nm的工艺。
● NVIDIA和ATI将全线使用40nm工艺
当然,NVIDIA在工艺方面“追逐”的脚步也在不断加快,据最新的报道显示,NVIDIA刚刚正式发布的五款GeForce 200M系列笔记本显卡全部使用了台积电最新的40nm工艺,而且NVIDIA发言人自豪的声称:“我们使用了台积电40nm生产能力的80%左右”。看来,NVIDIA台式显卡全面普及40nm也指日可待了。
ATI一次又一次的在工艺方面上演传奇,不得不令对手紧跟其后,这也为GPU的发展起到了推波助澜的作用,不断的日新月异。新工艺带来的优点不言而喻,更高频的频率意味着更强的性能,更小的核心意味着更低的功耗发热与成本,也给广大用户带来更优秀的产品。
二、ATI显卡先进技术回顾:GPU显存的领头羊/GDDR4/5先驱者
除了工艺上的领先外,ATI显卡在其显存的规格上,也是高人一等的,一直以来,对手NVIDIA几年如一日般始终沿用着GDDR3显存,而1.0ns的主流规格也只有2000MHz的频率,即便最快的0.8ns GDDR3上限也就是2400MHz。
● 夭折GDDR4显存:X1950XTX、HD2600XT、HD3870
提到ATI的GDDR4显存,可以追溯到4年前的Radeon X1950XTX产品,那是首款采用0.9ns的GDDR4显存的显卡(当时最快的DDR3是1.2ns),之后HD2600XT、HD3870也使用了GDDR4显存,不过由于性能的关系和颗粒厂商的投放,GDDR4并没有发展起来,这也是NVIDIA为什么一直沿用GDDR3的一个重要原因,尽管ATI率先吃了第一个螃蟹,但是味道并不怎么样,不过其敢于尝试的精神还是值得推崇的。

2年前ATI首款GDDR4显存的显卡就是这个0.9ns的三星颗粒
GDDR4没落的原因:同为0.8ns的GDDR3和GDDR4,虽然GDDR4容易达到更高频率,但是由于延迟的增加,实际性能甚至比GDDR3还要差,因此GDDR4被冷落也在情理之中。最终由于内存芯片厂商没有投入精力研发改良GDDR4,其规格也就止步于0.8/0.7ns,甚至0.6ns都没有放在产品上,仅仅只有样品而已,相比GDDR3没有质的提升。
另有一说,JEDEC组织中GDDR4标准的制定者就是ATI的高层,NVIDIA自然全力抵制GDDR4,加之GDDR4相比GDDR3没有质的提升,而且成本又高,最终不了了之。
● GDDR5威力惊人:256Bit HD4870挑落448Bit GTX260

HD4870首次使用GDDR5显存,256bit将对手448bit挑落马下
虽然面对之前的GDDR4无疾而终,丝毫没有阻挡住ATI前进的步伐,新一轮的显存争夺上,又是ATI捷足先登,HD4870率先采用GDDR5显存颗粒,紧接着是4870X2,在保持256Bit显存位宽不变的情况下,大幅提升了显存频率,默认频率高达3600MHz,消除了困扰多年的带宽瓶颈,成为了目前规格不凡的显卡产品。
● GDDR5平易近人:128Bit HD4770完胜256bit 9600GT战平9800GT

定位中端的HD4770上面也使用了GDDR5显存,128bit对抗256Bit成为可能
也正是因为GDDR5显存的助阵,HD4870才能以较小的核心、较低的显存位宽(256Bit),来挑战NVIDIA恐怖的GTX200核心(512Bit),而且双核的HD4870X2也迫使NVIDIA不得不拿两颗怪兽GTX200来对抗。虽然最终在性能方面依然是N卡占优,但在产品设计及成本方面,NVIDIA已经意识到了不足并开始重新审视GDDR5的威力。
● NVIDIA终于全面搭上GDDR5快车
据传闻,NVIDIA将在下代GT300芯片上使用GDDR5显存,不过最新消息,其笔记本GPU芯片已经开始升级到GDDR5显存并搭配40nm工艺,看来NVIDIA也有些按耐不住了。不过这一切相对于ATI来讲,都是玩过的东西了,也许你会说ATI一直在这方面比较激进,但这就是科技发展的动力,保守固然可靠,但是失去敢于挑战的勇气,就不会有进步。
三、ATI显卡先进技术回顾:公版率先使用数字供电/做工出色
ATI显卡最为AFan津津乐道的莫过于其豪华的用料和出色的做工,奢侈的数字供电系统更是曾经ATI显卡的独有标志。追溯到过去的X1800时代,到现在的HD4000,每一次ATi近乎疯狂的在高端原厂卡上面“不惜工本”采用豪华数字供电,事实上这种供电是很冗余的,用不好的话说就是浪费,但ATI原厂卡设计师都是追求完美的,他们为广大AFan们献上了一件件艺术品:
● 从X1000开始全面进入数字时代:

从左到右依次为:X1900XTX、X1800XT、X1800XL
(豪华的7/6/5相数字供电)

功耗较低的X1950Pro也使用了3相数字供电
从之前的X1000系列开始,ATI就与豪华的数字供电结下了不解之缘,当时1950PRO采用特别订做的双路并联磁闭贴片式电杆,每个都能通过40A的大电流(比很多显卡整卡需要的电流还高),也就是说这个小家伙总共能通过80A的电流。不要小看这种并联电感,它最高可以在2MHz频率下工作,属于超高频电感了,而且体积小,全球能设计并制造这种电感的厂商没几家,再加上是定制产品,所以价格高昂,甚至比很多显卡整个电源部分的成本还高。
● HD2900XT空前豪华的阵容:

到ATI RV600身上,我们看到了更为惊人的数字供电体系,更猛的7相
到了HD2900XT这代,供电部分相比当年的X1900XTX更加豪华,电子元件排列非常整齐。右上角的VT1165MF搭配6颗VT1195SF(此芯片已包含MOS在内)以及两颗并联电感组成6相电源给R600核心供电。而左边的另一颗VT1165MF主控芯片仅控制1颗VT1195SF和电感单独给显存供电。相比对手传统的供电方式,先不论供电性能如何,光凭豪华的尺度,ATI在供电方面就有足够骄傲本钱。
● HD3870X2/HD4870X2/HD4870/HD4890,数字供电不断升华




HD3870X2=(2+1)x2 HD4870X2=(3+1)x2
● GTX280/260/295,昙花一现的N卡数字供电

GTX280是NVIDIA最豪华的数字供电方案,然而只是昙花一现
反观对手NVIDIA,在公版卡设计方面一直都本着够用就好的实用主义原则,换句不好听的话说就是节约成本。一代又一代的产品相比较,在做工用料方面,ATI绝对是技高一筹。尽管GTX280显卡告诉我们数字供电不是ATI的专利,N卡的用料做工也能做到极致奢华,但其供电设计始终缺乏美感,凌乱的布局根本无法同ATI原厂卡相提并论,这也就是双方在设计理念方面的差异。

很遗憾NVIDIA最新的单核旗舰卡GTX285又抛弃了豪华数字供电系统
可是GTX280毕竟是昙花一现,最新的GTX280升级版GTX285由于功耗下降不少,NVIDIA认为数字供电太浪费了,加之成本方面的考虑,GTX285的供电系统相对于GTX280来说开始大幅缩水,虽然仍可以用豪华来形容,但少了数字供电怎么也称不上奢华,这一点相比ATI来说,有些不厚道。


双PCB版的9800GX2和GTX295都使用了数字供电
除了GTX280外,NVIDIA有两款显卡被逼无奈使用了数字供电,那就是双核心双PCB的9800GX2和GTX295,因为镂空设计的PCB可用空间实在是太小,也只有集成度超高的数字供电才能在如此狭小的空间内满足庞大核心和显存的需求。
在GTX295改用单PCB设计之后,NVIDIA又放弃了数字供电,看来NV的理念还是够用就好,从不轻易使用成本高昂的数字供电系统,除非是逼不得已——GTX280功耗太大,而9800GX2和GTX295的PCB空间极其有限。
● 绿色阵营AIC也钟爱数字供电
由于数字供电成本很高的原因,只有ATI高端公版卡才会使用,而AIB合作伙伴一般都会放弃数字供电,使用传统供电重新设计高性价比的非公版显卡。但在NVIDIA阵营却正好相反,AIC合作伙伴近年来对数字供电产生了浓厚的兴趣,而且“出手阔绰”,这与“小器鬼”NVIDIA公版产生了鲜明对比:

华硕GTX295火星版,使用了迄今为止最强大数字供电(5+1)x2

影驰GTX275,核心供电部分使用了数字供电,但显存还是传统供电
虽然羊毛出在羊身上,数字供电和传统供电到底相差多大,也不容易测试,但单凭数字供电的昂贵价格,我们总该相信一分钱一分货的道理。与竞争对手NVIDIA不同,ATI追求的是板卡的完美,而不是低成本,这可能是两者设计风格不同造成的,但我们不可否认ATI在优异产品上的先进供电技术确实是值得推崇的。
四、ATI显卡先进技术回顾:单PCB双核显卡的设计方案
两大图形厂商,为了霸占性能王者的宝座,一直想方设法的提升产品的性能,在目前有限的工艺下,只有像CPU一样,朝着多核发展,才是提升性能的有利手段,因此双芯显卡就应运而生了。

NVIDIA的双核显卡一直采用双PCB设计:7900GX2和7950GX2


NVIDIA的双核显卡一直采用双PCB设计:9800GX2和GTX295
一直以来NVIDIA和AMD-ATI在双核心显卡上就走着截然不同的道路。NVIDIA主张双PCB双芯设计,认为双PCB结构布线宽松不少,PCB层数要求低,但是成本及散热是弊病,而且结构越复杂越容易出问题,基本无法使用第三方散热器(除非是专门定做的)。

ATI一直采用单PCB双芯设计:HD3870X2和HD4870X2
而ATI无论是自己的公版还是旗下AIB自行研发的双核心显卡全部是清一色的单PCB双芯结构。但单PCB双芯对于供电和布线的要求较为苛刻,布线紧密、PCB层多、集成度超高。
就此,到底双PCB双芯好,还是单PCB双芯好的问题,不仅是当时NVIDIA与ATI相竞争的手段,也成为发烧玩家之间一个争议不断的话题。究竟哪种设计技术更好更先进,自己说永远没有说服力,只有对手承认好才是真的好,看了NVIDIA最新的双芯产品,相信我们心里也会有答案的。

最新的升级版NVIDIA GTX295显卡抛弃双PCB采用类似ATI的单PCB设计
最终,一直主张双PCB双芯的NVIDIA终于低下了高贵的头,低调的推出了单PCB双核心的新版GTX295。不能说谁模仿了谁,但与ATI设计有着异曲同工之妙,可以认为变相肯定了对手的设计理念,因此说ATI具有先进的、完美的单PCB双核显卡的设计方案,相信不足为过。
五、ATI显卡先进技术回顾:率先引入笔记本PowerPlay节能技术
说道先进技术,ATI的PowerPlay节能就不得不提,自AMD收购ATI之后,对于显卡的功耗发热问题投入了足够多的重视,发布RV670核心时就把笔记本显卡专用的PowerPlay节能技术引入到台式机GPU身上,PowerPlay不但可以自动降低GPU频率,而且可以在显卡空闲时降低电压,让部分晶体管处于深度休眠状态,从而最大限度降低GPU的发热和功耗。

在一些老游戏或者网游中,强大的GPU无需全速运行,从而节省大量功耗
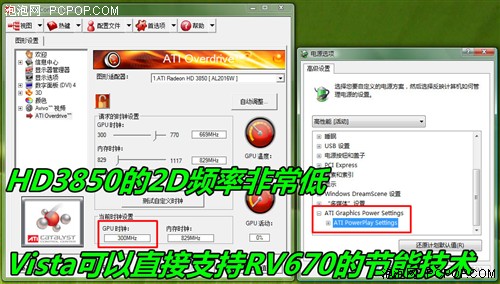
vista系统可以识别出RV670支持PowerPlay节能技术
现在GPU的晶体管、核心面积、功耗和发热量早已超过了CPU,可是一直以来显卡的功耗和发热问题都没能得到重视,即便您不玩游戏,显卡还是要白白的浪费很多电力、制造一些烦人的噪音、并且源源不断地发出废热!

通过实际测试来看,PowerPlay除了能够在GPU空闲和高清视频播放时降低功耗发热之外,还能够在运行一些负载不高的老游戏时,智能的降低显卡频率、并适当的降低GPU使用率,从而达到节能、降低发热、控制噪音(温控风扇自动降速)的目的。
● NVIDIA也有节能技术,但仅限高端卡
当年AMD率先在K8 CPU上实现笔记本才有的CnQ节能技术,之后Intel迅速跟进,也将SpeedStep节能技术引入桌面。而ATI率先在桌面GPU上引入PowerPlay技术后,NVIDIA的反应就有些冷淡了,直到GTX280发布时才加以支持,而且还没有一个正式名称,因为中低端显卡都不支持。
NVIDIA的风格是不肯轻易低头,虽然PowerPlay是项好技术,但不能盲目跟风,否则就有失领袖风范。与ATI全线显卡统统支持PowerPlay技术不同,NVIDIA只有GTX200系列高端卡才能支持节能技术,近期推出的一些绿色节能版9600GT和GTS250也能支持,那为什么这么低调呢?因为还有一大批型号不支持,如果过于强调节能的优势,谁还买老卡?
六、ATI显卡先进技术回顾:超越对手支持微软DX10.1/SM4.1
ATI RV670是首款支持DX10.1和SM4.1的GPU,根据微软的说法,DX10.1是对DX10的一系列完善、补充、拓展和延伸,并增加5个新的API、支持即将发布的最新硬件、强制要求FP32纹理过滤和4x MSAA多重采样反锯齿。ATI HD3000/HD4000全系列显卡都支持DX10.1。
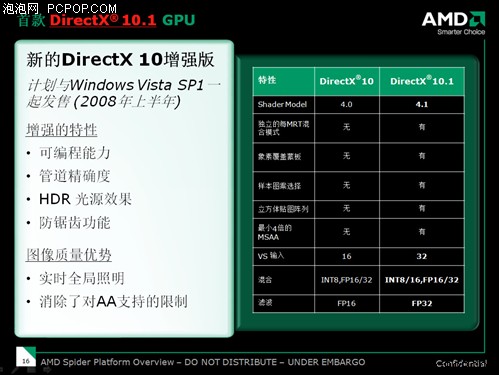
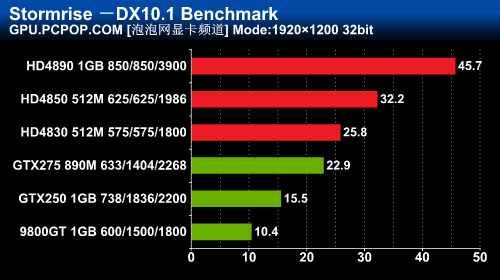
一些游戏对于不支持DX10.1的NVIDIA显卡来说,性能大幅下滑
之前通过对一系列DX10.1游戏的测试,以及针对DX10.1游戏所做得AMD显卡与nVIDIA显卡的对比测试我们可以很明显的看到DX10.1相对DX10来说不仅仅是在游戏画质上有一定程度的提高,同时它对游戏速度的提升也是显而易见的,特别是AA效能十分明显。
● 被“和谐”的DX10.1游戏——《刺客信条》
遗憾的是,支持DX10.1的游戏还是太少了,屈指可数,根本无法与NVIDIA的专利——PhysX游戏相提并论,这也使得ATI的DX10.1技术备受冷落。至于个中缘由只可意会不可言传,通过首款DX10.1游戏《刺客信条》被和谐事件可以略知一二。
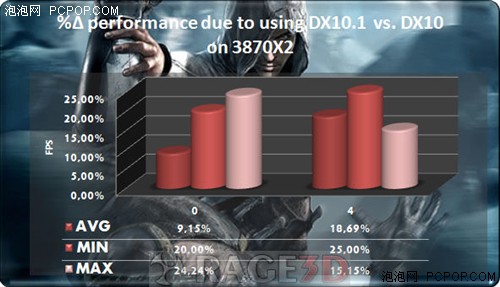
之前的测试,原版《刺客信条》DX10.1模式下,4xAA性能提升18.69%。
事件回顾:《刺客信条》发布时,原版默认支持DX10.1,但育碧很快就放出了一个升级补丁,偷偷的去掉了对DX10.1的支持,致使A卡性能下降不少。
● NVIDIA再次低头?40nm新核心全部支持DX10.1
NVIDIA始终认为DX10.1不是必须,因为DX10.1所带来的新特性实在是太少,NVIDIA拥有强大的驱动研发团队,通过改进驱动算法也能让DX10显卡“兼容”DX10.1的新技术和新特效。据之前的报道来看,NVIDIA声称DX10.1只是过渡规格,打算跳过DX10.1直接进入DX11时代。

DX10.1游戏屈指可数,只能说ATI的影响力远不如NVIDIA
就在前几天,NVIDIA正式发布了五款GeForce 200M系列笔记本显卡,不但在NVIDIA史上首次全部采用40nm新工艺,并开始配备GDDR5显存,还加入了对DX10.1的支持。此前虽再度有相关传闻,但就在DX11迫近之际,NVIDIA竟然真的接纳了长期“恨之入骨”的DX10.1这一技术,实在让人难以捉摸,NVIDIA也尚未对此做出正面解释。
终于没有人再提“DX10.1无用论”了,ATI微笑着坚持到了最后。但DX11也快来了,AMD已经在台北电脑展上拿出了DX11的GPU和Demo,并且信誓旦旦的称AMD将率先推出DX11显卡。现在,DX10.1不是没用了,而是过时了!
七、A卡先进技术之九:纳入DX11的Tessellation技术
DX10.1改动较少,未能带来惊喜,所以很多玩家慢慢接受了N卡不支持DX10.1也无所谓的事实(但谁也没有料到NV变化这么快,又支持DX10.1了),并把希望寄托在了微软下一代API DX11之上,而在DX11的五大主要特性当中,我们发现有一个非常眼熟的技术——Tessellation。

没错,ATI第一代DX10核心R600(HD2900XT)中就整合了一个叫做Tessellation的特殊模块,从HD2000系列开始、到HD3000再到如今的HD4000系列,ATI的每一款DX10显卡都支持这项技术,虽然还没有任何一款游戏能够支持该技术,但ATI依然孜孜不倦的对它提供支持,因为ATI坚信——是金子总会发光的!

等到DX11正式接纳Tessellation时,这已经是AMD的第六代技术了,真不容易
终于在DX11时代,微软将Tessellation作为一项重要标准纳入规范之中,这项被埋没多年的技术得以重见天日。那么Tessellation究竟是何方神圣,让ATI技术人员如此执着,微软到底是“禁不住软磨硬泡”、“勉为其难”的吸纳之,还是为其先进的特性所倾倒,欣然接纳之?故事还得从七年前的Radeon 8500系列谈起……
关于Tessellation技术,感兴趣的朋友请参阅“七年磨一剑!DX11之ATI独门绝技全解析”一文,本文不再赘叙。下面简要介绍Tessellation所能实现的效果:

Tessellation技术让模型变得更加细腻
Tessellation是一种能够在图形芯片内部自动创造顶点、使模型细化、从而获得更好画面效果的技术。Tessellation能自动创造出数百倍与原始模型的顶点,这些不是虚拟的顶点,而是实实在在的顶点,效果是等同于建模的时候直接设计出来的。
而且,Tessellation过程被安排在了顶点着色之前,这就意味着Tessellation所创造出来的顶点全都可以参与Vertex Shader的处理和运算。这些顶点所带来的所有细节,将具备所有特效。

基本的顶点模型,最终生成效果很幼稚

经过Tessellation智能拆嵌之后,模型精细了很多

拆嵌后再辅以各种阴影及着色效果,从而以很小的代价达到CG级别画面
在R600发布时,AMD拿出了一款CG级别实时渲染的Demo,其中被积雪所覆盖的山体就是由Tessellation生成的。以往的演示Demo都是片面注重对主角的修饰,而背景往往只使用简单的纹理贴图,而R600的这个Demo其背景和环境的精细程度甚至超越了主角Ruby。

《战地:叛逆连队2》宏伟的雪山场景
除了Demo之外,现在《战地:叛逆连队2》第一个跳出来声援,号称全球首款DX11游戏,该游戏使用了新版Frostbite Engine,当年ATI演示R600 Ruby Demo的时候使用正是该引擎。战地引擎的使用者不在少数,看来Tessellation技术以及DX11很快就将进入实际应用阶段,卧薪尝胆的Tessellation终于重见天日!
据DICE渲染架构师Johan Anderson称,从DX10到DX11的实际导入过程仅仅花费了三个小时,其中在代码里搜索和替换相关部分最耗时间。现在我们就不难理解战地引擎升级支持DX11为何如此神速了,两年前的战地引擎就能支持Tessellation技术,现在只不过是查找复制粘贴重新找回被闲置的代码而已,那还不是轻车熟路?
八、ATI显卡先进技术回顾:性能功能全面的革命性整合平台
我们不可否认目前整合平台的崛起和ATI的贡献是密不可分的。2007年,沉默了将近1年的ATI芯片组,在投入“新东家”AMD怀抱后,终于交出了令人满意的答卷。ATI 690G芯片组的发布,让整合平台焕发了第二春,而之后相继推出的780G更是将整合平台进行了革命性的演变,成就了全能主板的诞生,而陆续推出的790GX则是锦上添花,拉开与竞争对手的距离。
整合平台因690G而崛起:三大优势独霸业内
优势1:多媒体关键因素
当时大部分主流芯片组均已提供对DX9.0C、HD视频解码的支持,但是支持HDMI接口的唯独AMD 690G一款,是符合vista Premium徽标需求的产品中的少数者。

 业内首款提供HDMI接口支持的整合芯片组产品,AMD 690G
业内首款提供HDMI接口支持的整合芯片组产品,AMD 690G此外,AMD 690G芯片组支持HD视频解码,包括对H.264/MPEG2/MPEG4的解码,并且支持未来支持蓝光/HD-DVD电影播放,尤其在CPU没有足够的速度解码高分辨率的高清晰视频下,HD视频解码将为CPU减轻负担。此外,微软还要求Premiun系统应当支持多显示器模式,用户至少能够使用两台显示器,配备了DVI与D-Sub双接口的AMD 690G也同样符合这样的需求。
优势2:影片画质提升,CPU占用率下降
AMD在690G整合芯片中加入了AVIVO视频技术,用以改善画质与视频回放能力。
优势3:整合3D性能堪比独显且功耗低
当时690G最明显的优势就是整合3D性能的提升,主要来自两项重要的改变:80nm制程、整合X1250显示核心。

当时的690G游戏性能相比同期对手提高30%
由于80nm工艺的引入,使得690芯片组核心面积缩小10%。80nm制程带来了更低的功耗,当然也使得简单的散热片便足以完成芯片散热的任务,控制整机游戏功耗仅为110W以下。此外,与过去相比,690G芯片组提供了4组Pixel Shader(像素渲染)管线、2个Vertex Shader(顶点着色)引擎以及2个ROP(光栅化操作处理单元),在显示核心上,与上一代产品相比,规格翻倍,性能堪比当时1XXX级别的低端显卡,消费者怎么可能不心动?
780G带来整合革命:硬解高清/最全接口/板载显存
性能升级:集成了DX10的相当于2400Pro级别的显卡在780G的北桥中,集成了相当于AMD的DX10低端显卡2400Pro级别的整合显卡,此款显卡的代号为HD3200,初始为700MHz到800MHz。并将支持北桥缓冲内存(LFB)技术通道。部分780G主板会自带16-128MB的板载专用显存“SidePort”,从而不再完全依赖系统内存,因此有利于提高集成显卡的性能。
提供最强硬件解码UVD功能
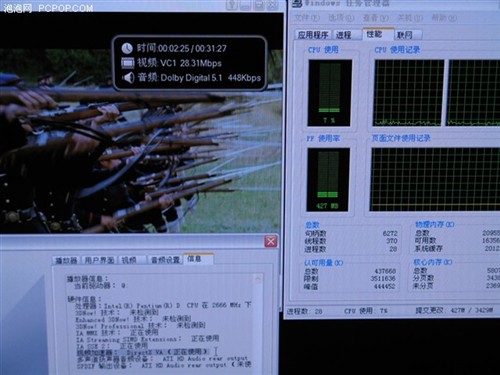
780G硬件加速打开,1080P最高占用率不过7%
UVD相对于上一代的AVIVO以及NVIDIA当时的解码技术的优势在于,通吃H.264、VC-1格式的HDTV,通过大量的测试来看,UVD的实力的确非常强悍,可以毫不费力的解压40Mbps的高码率视频,双核CPU的占用率可以下降至5%以下,即便是古老的赛扬1.7这种低能CPU占用率也能控制在20%左右!
提供最全接口:VGA+DVI+HDMI+DisplayPort

目前来看无论高中低端780G都配备了最全的接口
接口方面,780G也毫不马虎,提供了最全的接口配置,包括VGA、DVI、HDMI,甚至还将会提供DisplayPort接口。并且,780G为了通过HDMI同时输出音频和视频信号,RS780将集成音频控制器。
正因为780G的推出,令让两大芯片厂商如履薄冰,NVIDIA之后推出了MCP78芯片以抗衡780G,虽然在性能和功能上不相上下,但是过晚的推出,早已让780G占尽先机,自然无法轻易撼动!而Intel推出的全新整合芯片组由于性能和功能的不足,都无法与图形芯片出身的ATI与NVIDIA相抗衡,一时之间,在整合领域,ATI成为了NVIDIA与Intel不停追赶的目标。
九、ATI显卡先进技术回顾:高清应用出色/完美VC-1硬解码
看到了上面的整合主板技术,不禁让笔者想起了有关高清硬解码方面的一些技术及争议。进入DX10时代后,显卡的3D引擎、核心架构等都有了全新的变化。同样对于视频加速方面,NVIDIA与ATI也双双升级了自家的视频加速技术(PureVideo和AVIVO),目的是在高清解码过程中彻底解放CPU。
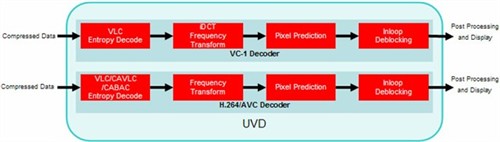
完全能够解码H.264和VC-1
NVIDIA最先在G84/G86核心中加入了对H.264完全硬解码的支持,但对于VC-1依然是半硬半软的解码方式,NVIDIA认为,VC-1的压缩率比H.264低,而且码率一般也不高(VC-1大概20Mbps左右,H.264是30-40Mbps),VC-1的前途未卜不会是主流,因此不支持VC-1的完全硬解码也无大碍,听起来确实很有道理。
ATI稍稍晚了一步,在G84/G86发布两个月后ATI推出了RV630/RV610,内部整合的UVD解码模块对于H.264和VC-1提供了无差别完全硬解支持,真正做到了彻底解放CPU的目的,UVD确实要更完美一些。
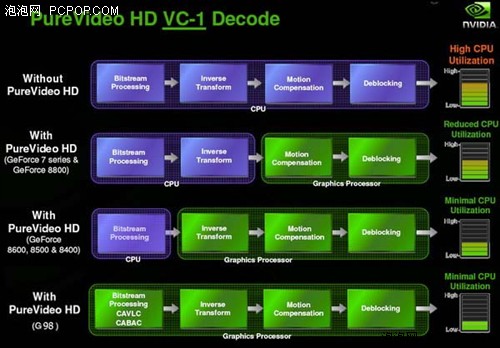
PureVideo HD技术直到第三代才解决了VC-1完全解码
也许NVIDIA忽视了微软的影响力(VC-1是微软的标准),虽然微软领导的HD-DVD光盘标准已经败北,但VC-1编码依然有很多蓝光影片在使用,而且码率越来越高,对CPU资源的消耗也水涨船高。更令人意想不到的是,入门级CPU的性能不升反降(为了追求低功耗,超低压单核处理器,以及Atom这种顺序处理器成为主流),这些处理器根本无法软解VC-1视频,NVIDIA半软半硬的方案也力不存心。
终于,NVIDIA再次妥协,顺应历史潮流推出了第三代视频解码方案(VP3),对于H.264、VC-1、MPEG2三大编码提供了无差别完美硬解支持,代表产品就是入门级的G98核心,以及整合芯片组MCP78、MCP7A、还有之后的离子平台。不过,完美的硬解仅限入门显卡及整合显卡,NVIDIA的中高端显卡依然不支持VC-1硬解,这一点不如ATI显卡彻底。
● 高清解码之争,未分胜负还是胜负已分?
以现在的眼光来看,NVIDIA的VP3引擎确实要比ATI的UVD2.0更加强大,NVIDIA除了H.264与VC-1外,还对MPEG2提供了完全硬解,而UVD忽视了MPEG2,并非完全硬解;另外NVIDIA领先ATI实现了双流解码(高清画中画或同时硬解两部HDTV)以及GPU倍线视频技术。
但是,NVIDIA的做法很令人费解,自己不支持的时候就避而不谈,或者旁敲侧击对方比自己先进的技术,等到自己能够支持、甚至变得更强的时候反而变得极其低调,堂堂八尺男儿缘何羞于见人?这不由得让笔者联想到了美苏争霸时期,第一颗人造卫星、第一艘载人飞船、第一次登月永远是最强的,在竞争激烈的尖端科技领域只有第一没有第二,你可以说你的卫星比对手更重、飞船飞行时间更长、各种各技术参数更优,但你已经输了。


Folding@home是一个研究蛋白质折叠、误折、聚合及由此引起的相关疾病的分布式计算工程,也是一个分布式计算的项目。世界各地来的人下载运行这个客户端程序,彼此组合在一起构成了世界上最大的超级计算机之一。每一台参与的计算机都使蛋白质折叠项目更接近成功一步。Folding@home把分布式运算和革新的计算方法有机的结合在一起,使人类能解决比以前碰到的困难无数倍的问题。最开始F@H仅支持CPU,后来加入了对PS3游戏机的支持,但同样是使用内置的CELL处理器做运算。F@H因ATI的加入为GPU计算翻开了新的一页,如今F@H第二代GPU客户端已经能够支持ATI和NVIDIA的全系列DX10 GPU。

根据官方排名来看,NVIDIA早已后来者居上,GPU所贡献的运算量也超越所有CPU总和,甚至超过了PS3,而参与运算的GPU数量却要比CPU少很多。ATI GPU的表现也不差,仅次于NVIDIA和PS3,从表中可以看出ATI GPU数量要比NVIDIA少,这可能是A卡市场占用率不够高、ATI推广不力、或AFan不够积极所致。
● GPU视频编码:ATI率先实现、NVIDIA全面超越
ATI同样是GPU视频编码的鼻祖,还是在X1000时代,ATI在催化剂驱动中集成了一款名为Avivo VIDEo Converter的小工具软件,该工具能够将常见视频转换为手持设备(iPod、PSP等)支持的格式,速度比单纯CPU编码快好几倍。
虽然当时Avivo的速度非常快,但据测试表明该软件似乎跟GPU的处理能力没关系,X1300/X1600/X1800/X1900的编码速度几乎相同,而且ATI的新显卡(HD2000/3000/4000)并不支持Avivo编码器。随后Avivo被破解,使得它能够应用在所有DX9/DX10显卡(包括N卡)上面,于是很多人怀疑Avivo只是一个打着GPU的幌子、通过牺牲画质换取速度的CPU编码工具!时过境迁,当Avivo编码器快被众人所遗忘,Badaboom大出风头之时,ATI在2008年最后一款催化剂驱动8.12当中重新启用尘封已久的Avivo编码器。
虽然名称没变,但ATI称这个小工具基于Stream流处理技术重新编写,仅支持HD4000系列显卡,速度更快,而且同样坚持完全免费的策略。这对于垂涎Badaboom已久的A卡用户来说,的确是个不小的惊喜。
根据国外媒体的测试结果,ATI在转码速度上拥有更强大的实力,然而却也使用了更多的CPU占用率作为代价,作为集CPU于GPU于一家的AMD来说,并不在意GPU应用时CPU占用率的高低,不需要去刻意的控制CPU占用率,这或许也是它速度更快的一大原因。ATI称:Avivo视频转换器仅使用GPU完成视频编码中的一部分工作,具体的说,GPU目前仅负责视频编码过程中对运算能力最敏感,最适于GPU应用的“运动估算”部分。由于在视频编码中交给GPU的负载是固定的,因此该过程中的GPU占用率可能因型号的不同而出现高低不等的现象。
NVIDIA虽然速度稍慢,却在输出的画质上明显高于ATI,CPU占用率也要低出不少。就两者看来,并没有一个明显的赢家,都体现出了GPU的并行计算能力,虽然Avivo速度更快,支持格式更多,但输出质量结果并不完美。Badaboom输出画质质量高,界面精美,但速度比Avivo慢,支持格式也相对有限。
● GPU通用计算,NVIDIA CUDA大出风头
虽然许多GPU通用计算的概念最早由ATI提出并率先应用,但NVIDIA的标量流处理器架构已经后来者居上,在很多方面都比ATI做得好,不过喝水不忘挖井人,NVIDIA虽然通用计算领域风头正劲,但是ATI所付出的努力也是不可磨灭的。看看AMD近年来所做出的努力也是显而易见的,对于GPU功能的开发也是紧追不舍,并没有落后NVIDIA太多。

NVIDIA和ATI从3D游戏战场打到了通用计算领域
回想过去,当ATI率先提出GPU通用计算时,很多人都以为这是天方夜谭,也不知道何年何月才能得偿所愿。如今,只花了两三年时间,GPU就已经在科学研究和超级计算领域取得突破性进展,在民用市场也开始遍地开花。
也许你会为NVIDIA通用计算推广力和实施力感到惊叹,也许你也会为ATI因AMD收购而浪费了两年崛起的时光,但是无论倡导者还是领导者同样值得我们去给于崇高的敬意。
全文总结:ATI在显卡领域贡献不可磨灭
写了那么多超前的技术,但无可避免的要回到原点,显卡最重要的还是性能和功能。而这两方面偏偏是ATI的弱点,性能方面ATI一直苦苦追赶缩小差距,功能方面Stream+DX10.1也完全被CUDA+PhysX所压制。
由于ATI被AMD收购耽误了不少时间,加之Intel浑水摸鱼挖走了不少人才,导致从DX10时代开始ATI就一直处于落后的地位。此后ATI痛定思痛、卧薪尝胆,不断改进和优化架构,终于在HD4800时代打了一场漂亮的翻身仗,令对手措手不及。但NVIDIA的GPU无论晶体管、流处理器还是显存位宽都有明显优势,因此主动权仍在NVIDIA手里,性能方面ATI始终占不到便宜。
不过ATI在HD4000时代的设计理念却是成功的,较小的核心和显存位宽在成本方面有明显优势,HD4000结束了N卡的暴利时代,将对手庞大的GTX200核心拉下马,被迫在主流市场进行价格肉搏战。如果您享受到了千元价位的GTX260+,那么也得感谢ATI的这些先进技术和设计。
总体来看,NVIDIA给人的感觉就是成熟、保守、踏实、务实,每款产品都很在意成本控制,处处透露着商业的气息,追求利润最大化,每年都会有非常可观的财报(经济危机特殊时期除外)。而ATI则是努力追求完美却很难达到,在做工、新工艺、新技术方面很激进,甚至甘愿冒险一试,当然代价就是经常有不成熟的产品或技术。

俗话说,胜败乃兵家常事,在全球性经济危机的恶劣环境下,被收购的ATI依然能够顶住压力坚持自己激进冒险派的风格,着实难能可贵。那么ATI接下来的全球首颗40nm+DX11 GPU能带给大家什么样的惊喜呢?我们一同拭目以待!■
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}

