

流处理器缘何差6倍!A/N GPU架构解析
G80和R600都是不计成本的作品,成本高、功耗发热大,随着新工艺逐渐走向成熟,双方不约而同的推出了改良版的核心,使得新高端产品的以大规模量产,这就诞生了G92和RV670核心,这两颗GPU虽然都拥有众多诱人的新特性,但实际上核心架构方面没有任何的变化。
● G92相对于G80的改进:
1. 制造工艺由90nm升级至65nm;
2. 新工艺集成度更高,G92的GPU核心部分与2D输出模块(NVIO)合二为一,是单芯片设计;
3. PCI-E控制器升级支持2.0版本,带宽倍增;
4. 高清视频解码引擎由VP1升级至VP2,支持MPEG2和H.264的完全硬解码,VC-1部分硬解码;
5. 加入HDCP支持和HDMI输出支持;
6. 显存控制器由384bit降至256bit,这是控制成本的需要。由于显存控制器绑定光栅单元(ROP),因此G92的光栅单元只有16个,而G80是24个;
7. 纹理寻址单元数量加倍,纹理采样效率提升。
在以上诸多改进之中,只有这一项才是设计到核心架构的,因此这里重点介绍:
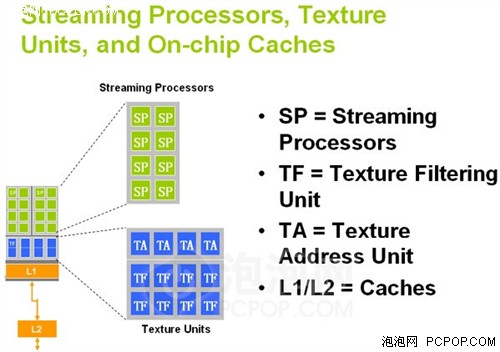
G80的流处理器结构
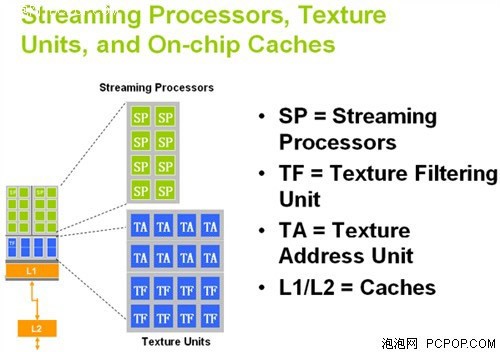
G92的流处理器结构
上面两幅架构图清楚的体现出了G80和G92的差异。NVIDIA GPU的流处理器簇和纹理单元还有一级缓存是绑定在一起的,G80的每簇内建了8个纹理过滤单元(Texture Filtering Unit)和4个纹理寻址单元(Texture Addressing Unit),总共数目就是64个TFU和32个TAU。而G92则提升至每组内建8个TFU和8个TAU,总共64个TFU和64个TAU,也就是纹理寻址单元数量加倍。
更多的TAU可令单一周期处理更多的纹理采样操作,部分情况下纹理处理器效率提升一倍!虽然DX9C时代反复强调高像素/纹理比例,但DX10时代引入了更多的纹理操作,并且SM4.0支持更复杂的纹理阵列,以便让物体表面拥有更丰富的细节,并且在超高分辨率下也不至于失真,但也对纹理操作提出了较高的要求,NVIDIA此举意在提升Call of Juarez、Crysis这种高精度游戏中的效率。
事实上,除了G80核心之外,G84、G86、G92、G96等所有衍生出来的小核心都改进了纹理单元设计,也就是说从8600GT开始起纹理寻址单元的数量就与纹理过滤单元相等了,只是中低端显卡的变化未能引起大家的重视。
● RV670相对于R600的改进:
1. 制造工艺由80nm升级至55nm;
2. PCI-E控制器升级支持2.0版本,带宽倍增;
3. 高清解码引擎由原来的Shader解码升级为UVD引擎,支持H.264和VC-1的完全硬解码;
4. 显存控制器由512bit降至256bit,这是控制成本的需要,而且以R600和RV670的运算能力其实不需要太高的显存位宽;
5. 支持PowerPlay节能技术,待机功耗很低;
6. API升级至DX10.1;
虽然API升级了,但实际上只不过是加入了新的Shader Model 4.1指令集而已,流处理器架构方面没有变化,甚至光栅单元和纹理单元都没有任何改动。
由于R600/RV670的架构是显存控制器并没有绑定光栅单元,虽然RV670的显存位宽减少了,但并没有造成太多的性能损失,反而由于频率的提升得以反超。因此G92相比G80是性能下降了,而RV670相比R600是有所提升,但最终的结果RV670和G92的差距依然很大。
可以看出,G92和RV670在技术方面的改进其实都是差不多,真正最关键的(流处理器)核心架构方面其实没有任何变化。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}