

流处理器缘何差6倍!A/N GPU架构解析
G92虽然有着众多G80所不具备的新特性,但本质上来讲它是G80削减成本的产物。而NVIDIA真正第二代DX10核心应该是GT200才对,下面我们就看看GT200相对于G80的改进。
● GT200架构的变化
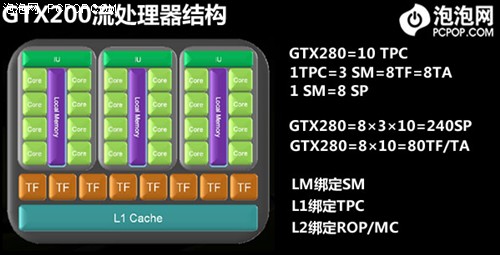
众所周知,GT200最大的变化就是拥有240个流处理器,而且显存位宽高达512bit,当然这只是表象,真正核心架构方面的改进如下:
G80/G92拥有128个流处理器,这些流处理器分为8组TPC(线程处理器簇),每组16个SP(流处理器),这16个SP又分为两组SM(多核流处理器),SM是不可拆分的最小单元,是8核心设计。
GTX200将TPC数量从8个扩充至10个,而且在每个TPC内部,SM从2个增加到3个,SM依然是8核心设计。如此一来,GTX200核心的流处理器数量就是,8×3×10=240个,几乎是G80的两倍,但却不是256个。
纹理单元部分,GTX200的每个TPC内部拥有8个TF,这样总共就是8×10=80个纹理单元。G80/G92的流处理器与纹理单元的比率是128:64=2:1,而GT200的流处理器与纹理单元的比率是240:80=3:1,正是GT200微架构方面的变化造成了这一结果。
● GTX200核心微架构改进
GTX200核心在流处理器、纹理单元数量上的扩充是很容易理解的,其实除了扩充规模之外,在架构的细微之处还有不少的改进,这些都有助于提高新核心在未来游戏或通用计算中的执行效能:
1. 每个SM可执行线程上限提升:G80/G92核心每个SM(即不可拆分的8核心流处理器)最多可执行768条线程,而GTX200核心的每个SM提升至1024条,而且GTX200拥有更多的SM,芯片实力达到原来的2.5倍!

2. 每个SM的指令寄存器翻倍:GTX200与G80核心在SM结构上基本相同的,但功能有所提升,在执行线程数增多的同时,NVIDIA还将每个SM中间的Local Memory容量翻倍(从16K到32K)。Local Memory用于存储SM即将执行的上千条指令,容量增大意味着可以存储更多的指令、超长的指令、或是各种复杂的混合式指令,这对于提高SM的执行效能大有裨益。

双倍寄存器的优势:代表DX10性能的3DMarkVantage得分直接提升15%
当前和未来的DX10游戏,越来越多的使用复杂的混合式Shader指令,一旦排队中的超长指令溢出或者在N个周期内都排不上队,那么就会造成效率下降的情况,此时双倍寄存器容量的优势就体现出来了。由于Local Memory并不会消耗太多晶体管,因此将其容量翻倍是很合算的。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}