

未雨绸缪!下代总线PCI-E3.0特性前瞻
泡泡网显卡频道4月15日 以目前显卡的性能来说,PCI-E 1.0的带宽都基本够用,PCI-E 2.0翻倍的带宽几乎没有用武之地(双核显卡例外),但Intel以及PCISIG组织已经在未雨绸缪的筹划下一代的PCI-E 3.0总线标准了。在昨天的IDF2010峰会上,Intel的专家向大家揭示了PCI-E 3.0的相关技术以及在Intel平台上的测试情况,我们一起来看看。
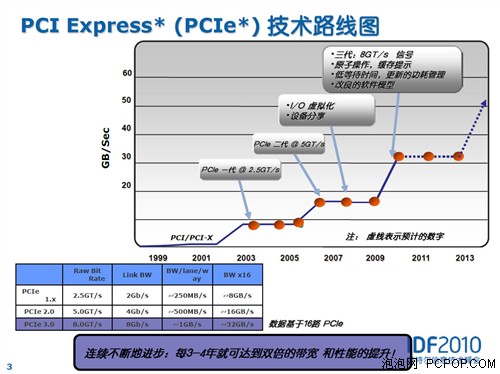
也许16链路的PCI-E总线对于显卡来说带宽是绰绰有余了,但对于大量的单链路设备来说,PCI-E 2.0/2.1的带宽还是略显不足,因此PCI-E 3.0的设计目标之一就是将带宽再次翻番,此时PCISIG组织遇到了很多困难,通过一些特殊的方法才达到了目的。

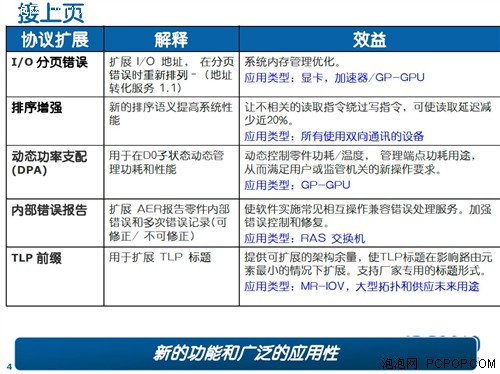
PCI-E 3.0是在上代PCI-E 2.1协议的基础上扩展而来的,其改进不仅仅是为了扩充带宽,最主要的目的是消除瓶颈,针对日渐普及的GPU并行计算、内存扩展、密集型数据交换、降低延迟等等。
我们知道,PCI-E 1.0的带宽是2.5GT/s(单链路250MB/s),PCI-E 2.0的带宽达到了5GT/s,但是PCI-E 3.0的带宽“只有”8GT/s,并没有达到了翻倍的既定目标,这是为什么呢?

因为从1.0到2.0再到3.0,PCI-E带宽提升的途径都是通过提高串行传输频率的方式,到了3.0时代频率再次翻番难度非常大,对设备电气性能的要求太苛刻,因此PCISIG组织只能退而求其次带宽只提高了60%,剩下的40%通过改进编码效率的方式来获得。

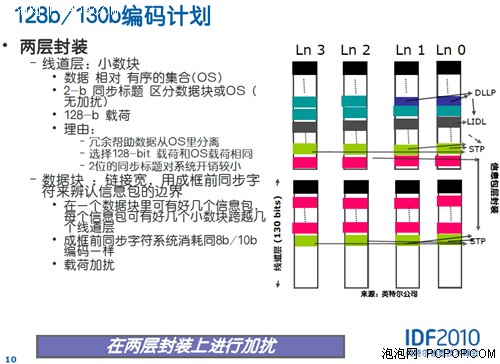
PCI-E 3.0在保留原有8b/10b K编码重要特性的同时,改进了算法开发了新的128b/130b编码机制,从而避免了25%的原始传输率浪费,因此与现在的PCI-E 2.1相比,PCI-E 3.0虽然数据传输频率没有翻倍,但综合结果是总带宽翻倍!
功耗控制已经成为当今业界和用户最为关心的话题之一,尤其是显卡的功耗已经达到了难以控制的地步,为了从接口底层最大限度的降低能耗,PCISIG组织尽其所能,加入了许多关于减低功耗的技术。
PCISIG组织认为,设备的工作模式影响功耗和其它系统配件,设备应考虑他们对整个系统功耗的影响,而不只是考虑自身的功耗,这就需要加强主机控制界面,于是基于PCI-E界面的能耗控制新鲜出炉了。
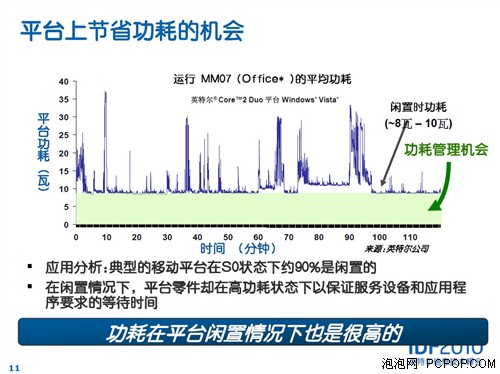
首先是设备空闲时功耗的控制,这部分如果不注意的话,完全是白白浪费能源。这方面显卡厂商已经做了很多努力,但收效甚微,而且已经接近极限。那么在PCI-E界面,如何进一步管理功耗呢?
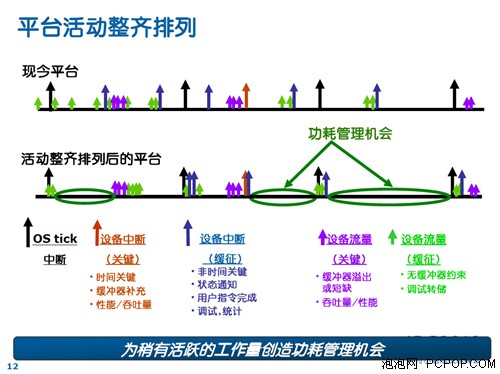
其实设备还有更多的机会来减轻负载,那就是通过重排任务序列的方式。系统和设备经常是闲置的,如果不是高强度任务的话(比如长时间用显卡玩游戏),一般偶尔会有零碎的任务会交给PCI-E设备处理,此时通过优化缓冲器的方式促使任务整齐排列,让设备在尽可能短的时间内处理完成多个任务,然后立即进入休眠模式,这样就会省下很多运算周期,让设备有更多的时间处在休息状态,从而达到节能的目的。
显卡依然是PCI-E的最大客户,不仅游戏玩家需要更强的显卡,科学计算也开始大量使用GPU作为协处理器进行并行计算,此时PCIE光提高带宽是远远不够的,为此PCISIG组织特意为显卡进行了多项优化:
1. 增强PCI-E设备对系统主内存的访问能力,显卡在显存不足的情况下性能大降的情况将不复存在;
2. 大幅降低CPU和GPU在相互通讯时的延迟,使得CPU+GPU异构计算的效率大大提高;
3. 多点通讯,让很多不相关读取指令绕过写指令,从而大大降低设备之间的延迟,并消除瓶颈。
4. 增强PCIE设备与其它硬件直接通讯的能力,从而绕过CPU的干预,降低CPU被访问的可能性,降低CPU占用率和延迟,提升性能。
5. 带宽的倍增意味着系统可以以更小的链路,支持更多的显卡设备,从而使得一套系统可以拥有更多的GPU,构建强大的个人超级计算机。
总题来看,PCI-E 3.0的诞生将会使得GPU的作用更像是一颗协处理器,为CPU分担更多的任务。当然,像网卡,声卡或者其他一些类似的配件要参与系统计算,前面的路还很远。因此PCI-E 3.0的现实意义还是在GPU身上,通过这一总线,GPU可以绕开处理器,而直接和外围设备进行通信,从这个角度来看,GPU也更像系统中真正的“第二个处理器”。PCI-E 3.0除了能使GPU的应用范围最大化,也能使效率达到最高。因此在这个系统中,处理器被一定程度上弱化了。■<
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}