

DirectX支配游戏!历代GPU架构全解析
★ 首款DX10显卡——GeForce 8800
无论从哪个方面来看,GeForce 8800与DX9时代的Radeon 9700都非常相似,微软的新一代API尚未正式发布,而新显卡居然开卖了大半年,虽然没有新游戏的支持,但在老游戏下的性能依然非常完美。因此每一代成功的显卡最关键的还不是API,还是核心架构。DX10是API的又一次革命,而G80则是GPU架构的一次伟大革命:
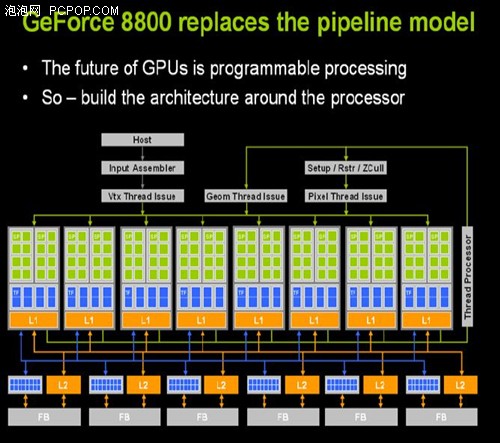
如果说R580像素与纹理3:1的比例让人很费解的话,那么G80的流处理器设计则让用户们一头雾水:从G71的24条像素管线一下变成了128个流处理器,哪来的这么多?
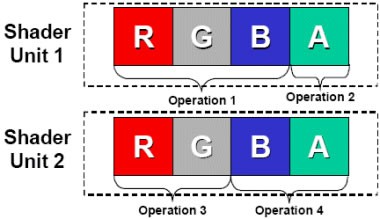
传统的GPU Shader架构
传统的Shader不管是像素还是顶点,其实都是SIMD(单指令多数据流)结构,就是个4D矢量处理器,可以一次性的改变像素的RGBA数据或者顶点的XYZW数据。而G80的流处理器则是1D标量处理器,它一次只能计算像素和顶点4个数据中的1个,如此说来效率岂不是很低?
当然不是,因为随着游戏的发展,GPU所要处理的指令已经不是4D这种常规数据流了,进入DX10时代后Z缓冲区(1D)或纹理存取(2D)等非4D指令所占比重越来越多,此时传统的Shader单元在执行此类指令时的效率会降至1/2甚至1/4,即便有Co-issue技术的支持效率改进也十分有限。
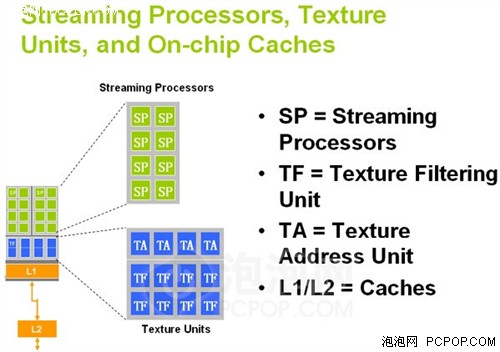
G80的SP
而G80 1D标量流处理器执行各种类型指令时的效率都能达到100%,这也就是NVIDIA对于GPU架构大换血的主要目的。G80的这种架构被称为MIMD(多指令多数据流),其特色就是执行效率非常高,但也不是没有缺点,理论运算能力偏低、晶体管消耗较大,当然由于对手产品实力不行,这些缺点在很长一段时间内都没有被发现。
而且NVIDIA的1D标量流处理器还可以异步工作在超高频率之下,一般是GPU核心频率的两倍,由此大幅提升了渲染能力。这一技术ATI至今都未能实现。
★ ATI的DX10图形架构——R600
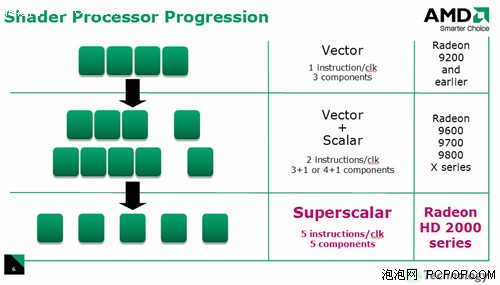
与革命性的G80架构不同,R600身上有很多传统GPU的影子,其Stream Processing Units很像上代的Shader Units,它依然是传统的SIMD架构。
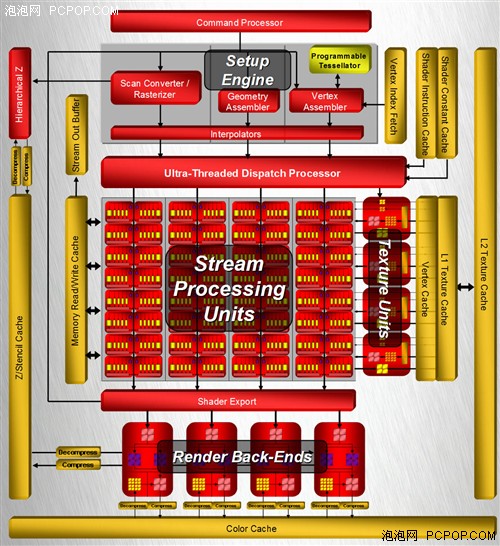
R600拥有4个SIMD阵列,每个SIMD阵列包括了16个Stream Processing Units,这样总共就是64个,但不能简单地认为它拥有64个流处理器,因为R600的每个Units内部包含了5个ALU:
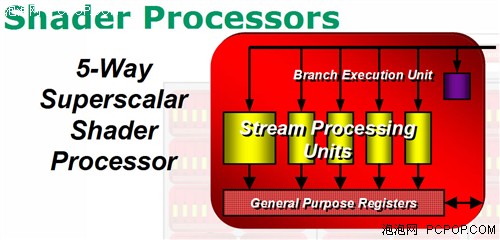
我们来仔细看看R600的流处理器架构:Branch Execution Unit(分歧执行单元)就是指令发射和控制器,它获得指令包后将会安排至它管辖下5个ALU,进行流控制和条件运算。General Purpose Registers(通用寄存器)存储输入数据、临时数值和输出数据,并不存放指令。
由于内部的5个1D ALU共享同一个指令发射端口,因此宏观上R600应该算是SIMD(单指令多数据流)的5D矢量架构。但是R600内部的这5个ALU与传统GPU的ALU有所不同,它们是各自独立能够处理任意组合的1D/2D/3D/4D/5D指令,完美支持Co-issue(矢量指令和标量指令并行执行),因此微观上可以将其称为5D Superscalar超标量架构。
通过上图就可以清楚的看到,单指令多数据流的超标量架构可以执行任意组合形式的混合指令,在一个Stream Processing Units内部的5个ALU可以在单时钟周期内进行5次MAD(Multiply-Add,乘加)运算,其中比较“胖”的ALU除了MAD之外还能执行一些函数(SIN、COS、LOG、EXP等)运算,在特殊条件下提高运算效率!
现在我们就知道R600确实拥有64x5=320个流处理器。R600的流处理器之所以能比G80多好几倍就是得益于SIMD架构,可以用较少的晶体管堆积出庞大规模的流处理器。但是在指令执行效率方面,SIMD架构非常依赖于将离散指令重新打包组合的算法和效率,正所谓有得必有失。
★ 总结:DX10架构G80笑到了最后
通过前面的分析我们可以初步得出这样的结论:G80的MIMD标量架构需要占用额外的晶体管数,在流处理器数量和理论运算能力方面比较吃亏,但却能保证超高的执行效率;而R600的SIMD超标量架构可以用较少的晶体管数获得很多的流处理器数量和理论运算能力,但执行效率方面却不如人意。
G80的架构显然要比R600改进更为彻底,所以打从一开始G80/G92就遥遥领先与R600/RV670,其后续产品GT200一如既往的保持领先优势,但幅度没有G80那么大了,因为R600的架构的特性就是通过数量弥补效率的不足。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}