

天河一号A称霸!超级计算未来属于GPU
记者:像这种CPU+GPU异构计算架构的超级计算机,使用了很多颗GPU,同时也使用了更多的多核心CPU,他们都拥有庞大的运算能力,那么在其最终实际运算量当中,大概有百分之多少是GPU贡献的,有多少是CPU贡献的?
Andy Keane:不同的超级计算机,其互联网络和结构有所不同,但大概来看的话,CPU运算量占20%,GPU占到80%。
记者:那就是说,GPU的运算量要比CPU大很多,以后的比例会继续提高吗?是不是意味着以后不需要太强的CPU,只需要能够管理的GPU就可以了?
Andy Keane:在系统的设计中,实际上是一个设计平衡的问题,一定要在各个环节里达到平衡,比如说你的GPU速度越快,就意味着你需要快速的CPU的速度,还有网络的速度以及内存的大小,是需要达到一个平衡的。也就是说更快的GPU还是需要更快的CPU支持。
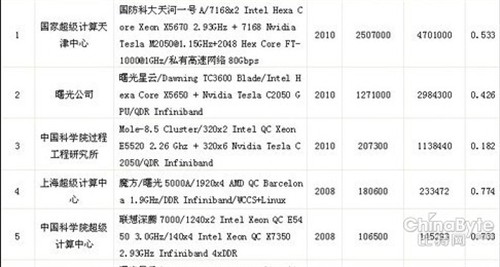
最新的中国超级计算机排行榜单
记者:我们今天看到中国的TOP100里面前三名都采用了Tesla的GPU,但是我们发现效率有很大的不同,第一名(天河一号A)最高,达到53%,第三名(中科院工程研究所)才达到18.5%,这个第三名也用到了GPU加速的互联技术。从GPU采用角度来说,NVIDIA公司对混合计算的效率有什么看法,或者说对于未来采用混合技术的开发人员有什么忠告,采用什么样的架构来保证混合计算体系架构的一个更高效率?
Andy Keane:系统的实际运行效率是由它所要运行的应用所决定的,你刚才提到的,效率比较低的第三套系统,它大多的工作就是处理分子动力学和离子仿真。它的应用就导致你需要对它的架构进行一些特殊的设计。新的天河一号A它主要面临的应用,是希望能够广泛的应用,我们也需要进行不同系统的设计。所有超性能计算机会用于不同的终端,只是现在比较普遍的衡量他们性能的标准都是Linpack值。
谢强:我补充一下,高性能计算机设计体制结构的两种方式:一种是有应用主导,然后设计计算机;第二种是我要设计一种通用的高性能计算机。所以大家设计计算体系结构的思想是不一样的。比如中科院的方式,他们是先有了应用,先有了离子仿真和分子动力学的应用,完全是按照他们的应用,他们的应用在上面跑的效率最好。但是非常不幸的是,今天世界排名只用Linpack的测试软件,中科院的系统设计不是为了跑Linpack设计的机器,他们是为了自己的分子动力学和离子仿真设计的机器,这样就导致用同一个测试程序测试的时候,结果会有比较大的差异。但是天河这台机器是为了不同的应用,它的设计更通用一些。
记者:看起来Tesla的效率是挺高的,但与纯CPU系统的超级计算机70%-80%的效率相比还是有一定的差距。
谢强:他们自己(中科院工程研究所)的应用效率是非常高的,可能能达到70%、80%,甚至80%、90%,非常高的效率。为什么会有这样的原因呢?分子动力学和他们那种计算模式,在不同的节点之间做计算的时候没有节点之间的通讯,而Linpack的程序节点之间是有通讯的。应用不一样,是造成这个问题最主要的原因。但是目前大家没有更好的衡量高性能计算的方式,Linpack已经是不错的了,大家默认Linpack测试了,不断你是什么结构设计的机器,都用这个来测试,这样大家都有一个排名了。

记者:我们知道“天河一号”去年发布的时候,它是中国TOP100的第一名,那时候他用的是AMD的HD4870X2,可能很多人会有疑问,到今年怎么都换成Tesla,我们也知道一些原因,想请NVIDIA具体给我们阐述一下,“天河一号A”基于什么样的考虑让他们最后把AMD的4870X2换成了Tesla?
Andy Keane:最主要的原因就是软件,NVIDIA公司提供了一个范围非常广的编程环境,使开发人员的能力得到很大的加强,所以说,主要还是提供了非常良好的编程环境。人们一般情况下会更多的关注语言,就系统而言真正关注的有两类人:一个是应用开发人员;另一类是对IT系统进行维护的人员。我们支持的ECC,首先它可以进行很好的SMI的管理,另外它也有一些软件工具,帮我们更好的管理集群。一方面可以进行很好的应用开发,另一方面还可以管理集群,所以这两者加在一起才使得系统表现的如此出色。一方面你要考虑这个系统是谁建造的,另外一方面还要考虑,是谁让建好的系统能够得以应用,这两个因素缺一不可。
像“天河一号A”里面用了7000多个GPU,放到一个系统中,除了开发应用技术之外,还有管理、维护的大量工作,而我们正好有这样管理、维护的技术,可以帮他们更好的管理。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}