

天河一号A称霸!超级计算未来属于GPU
泡泡网显卡频道11月3日 随着中国国防科技大学研制的“天河一号A”正式对外公布之后,采用GPU加速的超级计算机如愿以偿的登顶TOP500首席宝座,成为目前世界上最快的电脑,这对于GPU并行计算可以说是一座里程碑。详情参阅“"天河一号A"荣登世界超级计算机榜首”一文。

“天河一号A”强大的运算能力,主要来原因NVIDIA公司最新的Tesla GPU产品,NVIDIA在2006年发布了CUDA运行架构之后,经过将近4年的时间,Tesla GPU计算已经真真正正帮助到了中国超级计算机产业的发展,“天河一号A”、“星云”正是在NVIDIA的大力支持下,才获得了举世瞩目的成就。

NVIDIA GPU计算事业部总经理Andy Keane

NVIDIA中国区PSG高级销售经理谢强先生
为了进一步了解GPU加速在超级计算中所扮演的角色,笔者有幸对NVIDIA GPU计算事业部总经理Andy Keane先生做了一个简短的专访,下面就将此次专访的主要内容整理出来,供有兴趣的朋友们参考。
记者:像这种CPU+GPU异构计算架构的超级计算机,使用了很多颗GPU,同时也使用了更多的多核心CPU,他们都拥有庞大的运算能力,那么在其最终实际运算量当中,大概有百分之多少是GPU贡献的,有多少是CPU贡献的?
Andy Keane:不同的超级计算机,其互联网络和结构有所不同,但大概来看的话,CPU运算量占20%,GPU占到80%。
记者:那就是说,GPU的运算量要比CPU大很多,以后的比例会继续提高吗?是不是意味着以后不需要太强的CPU,只需要能够管理的GPU就可以了?
Andy Keane:在系统的设计中,实际上是一个设计平衡的问题,一定要在各个环节里达到平衡,比如说你的GPU速度越快,就意味着你需要快速的CPU的速度,还有网络的速度以及内存的大小,是需要达到一个平衡的。也就是说更快的GPU还是需要更快的CPU支持。
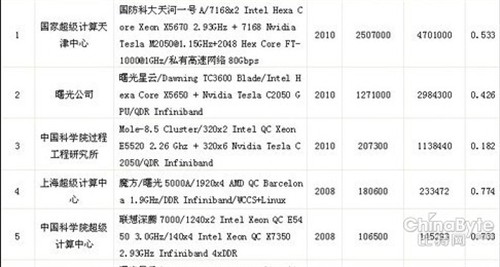
最新的中国超级计算机排行榜单
记者:我们今天看到中国的TOP100里面前三名都采用了Tesla的GPU,但是我们发现效率有很大的不同,第一名(天河一号A)最高,达到53%,第三名(中科院工程研究所)才达到18.5%,这个第三名也用到了GPU加速的互联技术。从GPU采用角度来说,NVIDIA公司对混合计算的效率有什么看法,或者说对于未来采用混合技术的开发人员有什么忠告,采用什么样的架构来保证混合计算体系架构的一个更高效率?
Andy Keane:系统的实际运行效率是由它所要运行的应用所决定的,你刚才提到的,效率比较低的第三套系统,它大多的工作就是处理分子动力学和离子仿真。它的应用就导致你需要对它的架构进行一些特殊的设计。新的天河一号A它主要面临的应用,是希望能够广泛的应用,我们也需要进行不同系统的设计。所有超性能计算机会用于不同的终端,只是现在比较普遍的衡量他们性能的标准都是Linpack值。
谢强:我补充一下,高性能计算机设计体制结构的两种方式:一种是有应用主导,然后设计计算机;第二种是我要设计一种通用的高性能计算机。所以大家设计计算体系结构的思想是不一样的。比如中科院的方式,他们是先有了应用,先有了离子仿真和分子动力学的应用,完全是按照他们的应用,他们的应用在上面跑的效率最好。但是非常不幸的是,今天世界排名只用Linpack的测试软件,中科院的系统设计不是为了跑Linpack设计的机器,他们是为了自己的分子动力学和离子仿真设计的机器,这样就导致用同一个测试程序测试的时候,结果会有比较大的差异。但是天河这台机器是为了不同的应用,它的设计更通用一些。
记者:看起来Tesla的效率是挺高的,但与纯CPU系统的超级计算机70%-80%的效率相比还是有一定的差距。
谢强:他们自己(中科院工程研究所)的应用效率是非常高的,可能能达到70%、80%,甚至80%、90%,非常高的效率。为什么会有这样的原因呢?分子动力学和他们那种计算模式,在不同的节点之间做计算的时候没有节点之间的通讯,而Linpack的程序节点之间是有通讯的。应用不一样,是造成这个问题最主要的原因。但是目前大家没有更好的衡量高性能计算的方式,Linpack已经是不错的了,大家默认Linpack测试了,不断你是什么结构设计的机器,都用这个来测试,这样大家都有一个排名了。

记者:我们知道“天河一号”去年发布的时候,它是中国TOP100的第一名,那时候他用的是AMD的HD4870X2,可能很多人会有疑问,到今年怎么都换成Tesla,我们也知道一些原因,想请NVIDIA具体给我们阐述一下,“天河一号A”基于什么样的考虑让他们最后把AMD的4870X2换成了Tesla?
Andy Keane:最主要的原因就是软件,NVIDIA公司提供了一个范围非常广的编程环境,使开发人员的能力得到很大的加强,所以说,主要还是提供了非常良好的编程环境。人们一般情况下会更多的关注语言,就系统而言真正关注的有两类人:一个是应用开发人员;另一类是对IT系统进行维护的人员。我们支持的ECC,首先它可以进行很好的SMI的管理,另外它也有一些软件工具,帮我们更好的管理集群。一方面可以进行很好的应用开发,另一方面还可以管理集群,所以这两者加在一起才使得系统表现的如此出色。一方面你要考虑这个系统是谁建造的,另外一方面还要考虑,是谁让建好的系统能够得以应用,这两个因素缺一不可。
像“天河一号A”里面用了7000多个GPU,放到一个系统中,除了开发应用技术之外,还有管理、维护的大量工作,而我们正好有这样管理、维护的技术,可以帮他们更好的管理。
记者:今天我们看到基于Tesla为主的计算系统,业内知名和第三的都是来自于中国的GPU异构计算的系统,但是从全球超级计算机TOP500强来看的话,采用GPU混合计算系统却很少见,好像中国现在比较热衷于GPU异构计算系统的开发,而且越做越大。NVIDIA公司怎么看待中国在GPU异构计算系统上的表现,跟国际上的其他企业有什么不同?
Andy Keane:如果你看全球500强这些企业,目前可能只有4台计算机用的是加GPU的异构计算方式,现在第三台超性能计算机是中科院IPE,在北京建的一台计算机。中国确实是最早先使用GPU的国家,另外,中国应用GPU的确历史最悠久,中科院也有一系列的规划,更广泛的使用在GPU系统中。但是在其他的企业,他们首先是进行小规模的GPU安装,之后再迁移到自己基于CPU的大的系统平台上,这是在国外的做法。(国外也有很多小型GPU超级计算机,但都未能进入TOP500强)
我相信在11月份发布的500强的企业中,你会看到更多的企业在使用CPU+GPU异构处理方式,当然在中国的企业的名字已经发布了,但是其他很多的使用混合处理器的企业将会在11月发布,基本上都是国外的企业。为什么呢?因为CPU+GPU有独特的优势,包括高性能以及高能效比两方面。

中国超级计算机除了“天河一号A”外,“星云”目前排行世界第二
记者:是否可以认为中国在基于GPU的应用开发也走在世界的前面?比如基于使用CUDA的这种编程环境,中国混合编程的团队或者技术实力,你怎么看待它在全世界的水平?
Andy Keane:没错,可以这么说,就像刚才提到的中科院的IPE高性能计算的应用,这是一个例子,还有很多其他的例子,中科院还有很多其他的引用。
其实,高性能计算是两个问题:一是,高性能计算让计算技术加速,本身是加速的问题;二是在应用上了,我们希望所有的科学家也好,工程师也好,都能够应用这样高性能计算的工具,来解决生活当中所面临的问题。一个是本身加速的问题,另外一个就是应用的问题。
记者:现阶段,中国在高性能计算上排名比较靠前,是不是说现在中国在高性能计算方面处在领先的地位,你对未来中国的高性能计算怎么看呢?
Andy Keane:毫无疑问中国占据了领先地位。新的500强将会在1个月之后发布,我相信对于应用来说,不仅仅是因为应用了GPU,在系统设计以及架构的安排上也是发挥了一定的作用,只有这两点综合起来,才能够让你的应用处于领先的地位。对于任何行业来说,如果你想成为行业领先的企业的话,其中一个方式就是采用最新的技术。
所以我相信,你看到Intel和NVIDIA公司两家企业,两个观点是具有非常鲜明对比的,比如说Intel的观点就是对过去的一种延续,一步一步的延续到未来。但是对于NVIDIA公司来说,尤其是中国的高性能计算,因为采用的是最新的技术,也获得了最新技术带来的优势。所以,在中国三大大型计算机的应用,就是因为采用了新的技术,使他们能够把这个优势应用到最好。
记者:现在异构计算越来越流行了,GPU的带宽能比CPU的带宽高好几倍,这么高,可能对每一个节点之间的互联也造成了很大的压力。在NVIDIA公司看来,目前的这种MPI的架构是不是已经达到一种瓶颈了,或者说在某些方向已经影响了互联的操作,未来有没有可能出现新的语言架构替代MPI?不知道NVIDIA怎么看来这个问题?
Andy Keane:计算本身是了解整个过程中存在什么样的局限和限制,之后让软件工程师或者计算机工程师寻找一些方法来跨越这些局限。所以,你刚才所提出的那个因素,应该是一个非常关键的因素,使得超级计算机可以大规模的进行灵活的扩展,主要是它跨越了互联项目的一些局限。如果这个系统是用Linpack来测量的话,因为要传递很多的数据,所以整个网络上会面临很大的数据压力。
根据我过去26年在计算领域的一些经验和体会,你们还会继续看到,这个行业在不断的发展,将会有更多的创意,一个接一个而来,你们接下来还会看到更多的创意和创新。比如说我们的处理器速度越来越快,这就意味着我们需要的总线数量也就越来越多,他们之间的互联性应该也是越来越好。不管怎么样,总会存在一定的局限和瓶颈,但是我们的工程师会想各种的办法跨越这些局限。
所以说,现在和过去的差异在哪里?你在新的系统中,我们用的是中国基本的技术,把它应用在高性能计算机中,使它的速度更快,而且扩展性更高。
记者:以前NVIDIA公司自己也设计编程,从显卡到后来的CUDA编程,NVIDIA公司越来越多的进入标准领域,以后高性能计算里面也会涉及到标准,比如MPI也是一种标准。你们作为主导GPU混合计算的领头企业,是否会提出一些更好的互联标准或者互联语言架构,比如像CUDA这样的GPU技术混合架构?
Andy Keane:从CUDA向系统级别这样的转换,在这个过程中,我们将和大量的合作伙伴一起来做,比如说HP、IBM,我们都会和他们一起做。就MPI来说,用这个例子你就可以理解了,比如说我们会和MPI整个开发者社区一起努力,同时也会把他们扩展到CUDA或者其他的软件,和他们进行结合。这个过程,一方面我们会在MPI一起和开发社区努力,同时我们也会考虑如何融合其他的软件。这是一个合作的过程,我们会做贡献,也会做出我们这一部分的努力。
记者:在你的履历里面,有在英特尔里面工作过,我们也知道,英特尔也在开发类似于显卡的内核架构的这种产品,可能它组装的是一种统一的编程架构,因为它都是X86。从英伟达来看的话,怎么看未来分支的状况?一种是传统的CPU的多核的架构,你怎么看待未来的这种竞争?
Andy Keane:即便是英特尔这边的发言人,他们在描述未来存在的问题时候,已经描述很好了,对于大型的超性能计算机来说,最主要的不是和X86兼容不兼容的问题,而是它的能源的问题。所以我们看一下计算系统的未来,在过去以及在未来都会经历多种过渡,比如说从低一级向高一级性能的过渡,成本也有一定的变化。你看一下超级计算系统的历史,我们之前从主机逐渐发展到Deck Alpha,之后到A1860,一直到现在的X86,最后这一步主要是出于低成本的考虑,同时也希望能够降低电耗,但是它的耗电量还是比较高的。所以说,我们接下来要面临的新的问题是什么呢?低成本是一个考虑,另外能耗怎么能够降低,是目前的一个挑战。
刚才我们看到的是过去的一些变化,看未来得话,我们要分析一下,未来面临什么样的挑战呢?两个挑战:一是编程的挑战,用什么语言呢?也许是基于CUDA语言的架构,当然我们也会考虑其他的语言,不仅仅局限于CUDA,这是一个挑战;另外,也是英特尔和NVIDIA公司不太一样的地方。如果把 X86核拿出来之后,如果要进行大型扩展的话,应用起来冷却是一个很重要的问题。我们的首席科学家Bill Dally也提出了很多的证据和数据,如果想进行进一步的发展和改变的话,首先我们要考虑平衡好能耗,还有高性能计算之间的关系。你要基于什么样的架构,而且这个架构一定是非常节能的架构,才能继续发展高性能计算。X86是不可以实现的,也许是未来的GPU或者其他的技术。
所以说,超性能计算跟手机也一样,我们也看到手机在不断的发展,有的手机用PC的操作系统,比如X86的核,有的是用内建的操作系统,但是它能够提供浏览网页和收发E-mail的功能。一些旧的系统我们可以摒弃,不是说要完全沿用下来,我们一定要进行创新,这样才能够解决功能上的问题,我想这也是高性能计算未来的发展趋势吧。
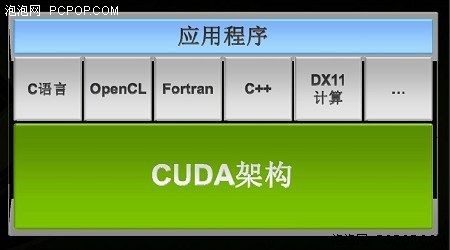
CUDA并不是编程语言,而是一种体系架构
记者:NVIDIA公司的产品现在对于OPENCL标准兼容性如何?在未来的话,你们怎么看待OPENCL标准在未来编程方面的前景?
Andy Keane:我们的主营业务就是卖GPU,至于软件,我们的独立供应商用什么的软件,用什么样的语言,对我们有什么要求,我们就按照他们的语言来进行运用,包括OpenCL、CUDA、Fortune,Pascal以及JAVA,我们都是根据他们的语言来应用GPU。所以我们的竞争对手,他们一般在做宣传的时候会说什么什么是你的选择,比如说OPENCL,他会说OPENCL是你们的选择,但是我们也看到了,我们是可以支持多种语言的OPENCL、CUDA、Pascal以及JAVA。不管软件供应商有什么样的要求,我们根据他们的要求就提供什么样的GPU,包括一些产品的驱动也好,双精度也好,其他扩展的功能也好,我们都可以去网站上免费下载。不管是开发商有什么样的需求,我们都会提供,都是可以兼容的。
金洋:再补充一点,有些人认为OPENCL是开放的,我们CUDA是不开放的,其实实际并不是这样的,我们这边非常支持OPENCL的标准,他们可能只有一个OPENCL,我们是唯一一家可以使用的、支持OPENCL计算的厂家。除了OPENCL之外,如果我们的消费者要用到其他的语言,C++、CUDA、JAVA的语言,我们都可以提供支持,我们GPU支持所有可以实现的语言。所以我们并不是决策者,决定哪种语言我们支持,决策者是用户,他们需要什么样的语言,我们提供什么样的语言。而且OPENCL组织的主席是NVIDIA公司现在的副总裁,可以说OPENCL在NVIDIA公司不断的推广,不断的支持下,OPENCL才可以得以壮大。所以我们对于OPENCL和对于其他语言的支持,我们都会全力的支持,任何一种用户会用到的语言,可以实现GPU高性能计算的规模性的发展,我们NVIDIA公司GPU都是支持的。 <
记者:Tesla作为NVIDIA公司比较新的产品线,一推出就很受欢迎,尤其是Fermi架构的Tesla一经发布,就有很多超级计算机使用。Fermi架构拥有GeForce、Quadro和Tesla三条产品线,那么那么能不能方便透露一下,在Fermi架构的GPU当中,Tesla出货的比例大概是多少?
Andy Keane:这个不太方便透露,也没有一个具体的数字,因为这是三条完全不同的产品线,面向的用户群也是截然不同,用户基数更是差很多,根本无法相提并论。

记者:或者从销售额来说。
谢强:如果从消费类市场,从量上来讲,消费类市场是专业工程图片卡市场的10倍,这是说10:1的市场,而不是说我们的销量。专业图卡的市场又会是高性能计算的10倍,这是在量上这样的一个区分,希望能够给你们一个帮助。可能没有一手的数据,因为Fermi这个产品刚刚出来,其实发货才一个季度,差不多从6月份开发发货,这段时间应该没有准确的基于Fermi的产品数据,从我们公司上一代产品来讲,差不多是这样的比例。这是最好的回答,希望能够帮到你们。
金洋:数字可能没有办法透露,但至少在中国,以及全球Quadro产品以及Tesla高性能计算市场份额来讲,我们都有绝对的优势。

目前的Tesla产品都采用了最高端GPU
记者:现在开拓的产品主要针对每一代优异的GDP来做的,未来会不会像Quadro一样做一些多条产品线,比如中高低端都有Tesla的产品?
Andy Keane:是这样的,我们将会在未来逐渐推出不同级别的应用,实际上我们现在的产品开发基本上根据客户的需求,比如说他们有什么样的性能需求,针对他们的需求,我们开发一些产品。比如说,现在客户要求的是性能一定要卓越,而且能够做更高的计算以及应用,这也是我们为什么开发目前的应用。
在未来计算机会有不同的发展趋势,比如之前说到的高性能计算机,这是一个应用。另外也有个人高性能计算的应用。在第二种类别中,我们可能用的GPU相对来说性能稍微低一些,但是它更好的能够和工作站结合,不用说和服务器结合,像这种大型的超级应用一样。
记者:现在国内更多的开始应用Tesla的产品,现在基于Fermi架构的Tesla产品在国内的销售和订单情况是怎么样的?客户在使用产品之后,他们集中反馈的情况是什么样的?
Andy Keane:我没有一些具体的数字,但是毫无疑问,美国是我们的第一大市场,中国是我们的第二大市场,而且这个市场在不断的发展壮大,成长的速度也是非常快的。为什么有这么大的发展呢?主要是因为一些引导性的或者说一些比较大型的试点超级计算机的应用系统的推出,使人们看到了,利用这个新的技术能够给他们带来什么样的潜力,所以它的发展才会非常快,目前也是非常快。
用户的反馈意见是非常积极的,我们把之前应用的一些弊端或者说一些性能得以进一步的加强,比如说它的双精度,以及ECC、缓存、IO接口都进行了性能上的提高。总的来说,我们从Tesla 10系列产品中进行性能的加强,对Tesla 10系列产品系列的应用中的一些经验和教训,我们进行了改进之后,用到Fermi架构之中。之后,我们会把在Fermi架构应用中出现的一些经验和教训,经过改进之后,再应用到Tesla中。我们的目标是,希望随着一代一代产品的推出,它的应用和性能能力得到很大的加强。
记者:NVIDIA公司现在开始特别注重架构,每隔两年更新一次,我看你上午演讲,07年、09年、10年、13年都有推出这样新的架构,我们知道Intel有一个tick-tock的战略,NVIDIA公司是不是也会朝这样的方向去运作?
Andy Keane:Intel的tick-tock只是在业界战略当中起的一个名字,制程的改进是一步一步的来,很多供应商都是这样的做,包括TSMC、EMC、intel、摩托罗拉,刚开始的时候,逐渐改进到40纳米,之后再进行微调,再往下一步发展就是32纳米。所以说tick-tock的描述,就是对半导体晶片的一个描述,其实每一家都是这样做的,只是Intel给了它一个战略性的营销概念,广告的语言吧。■<
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}