

决战性能之巅!NV双芯旗舰GTX590评测
GF100的每个SM都拥有4个纹理单元,这样整颗核心总共就是4x16=64个纹理单元,数量居然仅与G92处在同一水平。要知道GTX480被屏蔽了一组SM之后纹理单元只剩下60个,而自家上代GTX285和对手HD5870都拥有80个纹理单元。难道说NVIDIA认为DX11时代纹理贴图并不重要,因此在扩充流处理器规模的同时忽略了纹理?
9.5 精兵简政的纹理单元
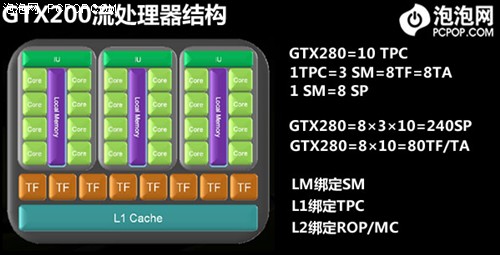
GT200的流处理器与纹理
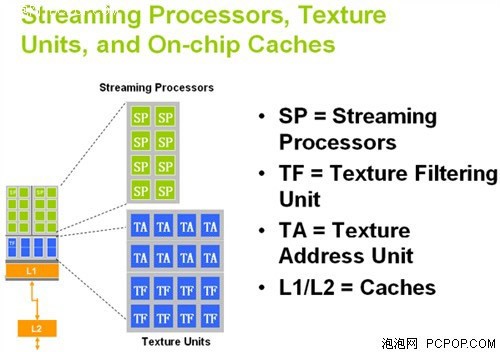
G92的流处理器与纹理
在以往的GT200架构中,是三个SM共享一个纹理引擎,该引擎含有八个纹理定址单元和过滤单元。更早的G92则是两个SM共享一个纹理引擎。
GF100的纹理单元确实是少了,但NVIDIA重新设计了纹理单元,通过改进效率来提升纹理性能,而不是以暴力扩充规模的方式实现,因为NVIDIA发现庞大规模的纹理单元也存在瓶颈,而且会浪费很多晶体管。
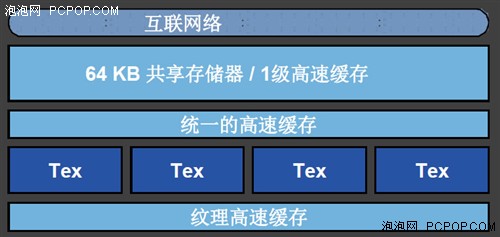
GF100的每组SM内部包含4个纹理单元
NVIDIA的方法听起来很简单,但做起来很复杂——就是将纹理单元从外围模块搬入到了SM之中,从而提升了纹理高速缓存的利用率、并达到了更高的时钟频率。道理就类似于AMD和Intel把内存控制器整合在了CPU内部,从而大幅提升了内存带宽和延迟。
我们知道,N卡的流处理器工作频率非常高,达到了核心频率的两倍甚至更高,而其包括纹理单元、光栅单元及周边控制模块在内的其它部分工作频率比较低。现在NVIDIA将纹理单元转移到了SM内部之后,大幅提高了工作频率,全新的一级缓存将以1200-1400MHz的全速运行,纹理单元虽然还是以半速工作但也受益匪浅。
在GF100架构中,每个SM都拥有自己专用的纹理单元并共享一级纹理高速缓存,GF100专用的1级纹理高速缓存经过重新设计,可实现更高的效率。而且,通过配备统一的2级高速缓存,纹理可用的最大高速缓存容量达到了GT200的三倍,为纹理密集的着色器提升了命中率。
每个纹理单元在一个时钟周期内能够计算一个纹理地址并获取四个纹理采样。返回的结果可以是经过过滤的也可以是未过滤的。支持的模式包括双线性、三线性以及各向异性过滤模式。
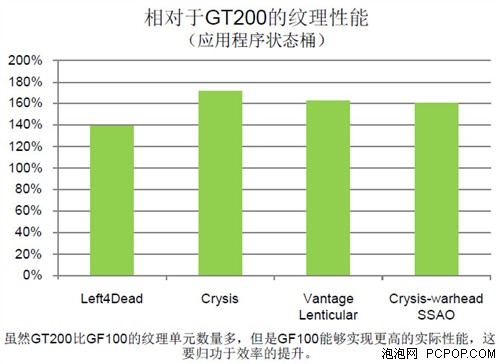
而且,纹理单元的内部架构还得到了大幅增强。在阴影贴图、屏幕空间环境光遮蔽等实际使用情况中,净效应就是所实现的纹理性能得到了大幅提升。
GF100的纹理单元还新增了对DirectX 11中BC6H与BC7纹理压缩格式的支持,从而减少了HDR纹理与渲染器目标的存储器占用。
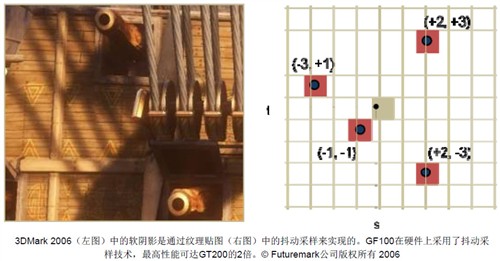
纹理单元通过DirectX 11的Gather4特性,还支持抖动采样。这样一来,单一纹理指令就能够从一个128×128的像素网格中获取四个纹理像素。GF100在硬件上采用了DirectX 11四偏置点Gather4,大大加快了阴影贴图、环境光遮蔽以及后期处理算法的速度。凭借抖动采样,游戏就能够高效地执行更加平滑的软阴影或定制纹理过滤器。
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}

