

决战性能之巅!NV双芯旗舰GTX590评测
从HD4000时代开始,AMD改进ROP单元设计之后抗锯齿效能大增,在标准的4xMSAA模式下已经与N卡不相上下,而在最高的8xMSAA模式下大幅领先于N卡。NVIDIA虽然提供了比较巧妙的高精度CSAA模式,但画质方面还是比不上正统的MSAA,基于8xMSAA的更高级别8xQ AA与16xQ AA也毫无用武之地,因为N卡的8xMSAA效能偏低。
为了一雪前耻,NVIDIA在GF100当中重新设计了ROP单元(后端渲染单元,俗称光栅单元)。主要是大幅提升了数据吞吐量与效率,上页介绍过GF100的L2已经不再与ROP及显存控制器绑定在一起,而且是全局共享的,因此存取效能与带宽大幅提升。
9.7 光栅单元与32倍抗锯齿
GF100的每个ROPs包括8个ROP单元,比GT200翻了一倍。这8个ROP单元可在一个时钟周期类输出8个32bit整数像素、4个16bit浮点像素或2个32bit浮点像素。原子指令性能也得到了大幅提升,相同地址的原子操作执行速度最高可达GT200的20倍,邻近存储区的操作执行速度最高可达7.5倍。
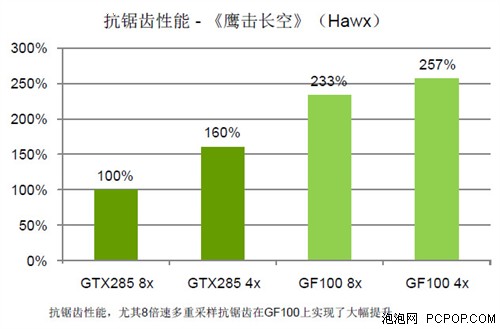
在GF100上,由于压缩效率的提升以及更多ROP单元能够更有效地渲染这些无法被压缩的较小基元,因此8倍速多重采样抗锯齿(8xMSAA)的性能得到了大幅提升。
在上代架构中,由于ROP资源有限,在进行高倍抗锯齿采样的同时还执行渲染后端处理任务时(如SSAO、运动模糊、景深等),效率会非常低下。典型的比如《鹰击长空》、《晴空》等等。
GF100不仅ROP资源非常丰富,而且可以在DirectCompute 11的帮助下减轻ROP部分的负载,提高执行效率,此时开启高倍抗锯齿就没什么压力了。
● 将CSAA精度提升至32倍,并优化算法实现更高画质
解决了8xMSAA效率抵消的问题之后,NVIDIA在此基础上更上一层楼,开放了更高级别的32x CSAA抗锯齿模式,上代精品只能提供16xQ CSAA而且实用性并不高。同时新的抗锯齿模式还优化了“透明覆盖”(Alpha-to-Coverage)采样的算法,实现更高的画质:


受到API与GPU计算能力的限制,当今的游戏能够渲染的几何图形数量还很有限。树叶的渲染是一个尤其突出的难题。针对叶子的一种常用技术就是创建一个包含许多树叶的透明纹理模版,利用“透明覆盖”来除去树叶之间的缝隙。覆盖采样的数量决定了边缘的画质。如果只有四个覆盖或八个采样,那么将会出现非常糟糕的锯齿以及镶边现象,尤其是在纹理靠近屏幕的时候。采用32倍速覆盖采样抗锯齿(CSAA),GPU共有32个覆盖采样,从而最大限度减少了镶边效果。
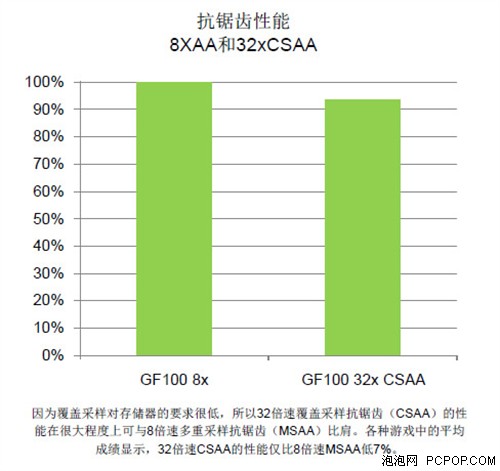
32x CSAA相比8x MSAA性能损失并不大,非常值得一试
透明多重采样(TMAA)也能够从CSAA中获益匪浅。由于“透明覆盖”不在DirectX 9 API当中,所以DirectX 9游戏无法直接使用“透明至覆盖”。而TMAA恰恰对这样的游戏有所帮助。取而代之的是,它们采用了一种叫做“透明测试”的技术,该技术能够为透明纹理产生硬边缘。TMAA能够转换DirectX 9应用程序中旧的着色器代码,使其能够使用“透明覆盖”。而“透明覆盖”与CSAA相结合,能够生成大幅提升的图像质量。
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}

