

决战性能之巅!NV双芯旗舰GTX590评测
自从NVIDIA于1999年发布第一颗GPU(GeForce 256)开始,GPU就已经与并行计算结下了不解之缘,GPU被扩展成为可进行浮点运算的可编程处理器,而不仅仅是图形处理器。GPU无论计算能力还是内存带宽都要远胜于CPU,其性能不应该被限制在游戏和3D渲染之中。这也是Fermi架构和竞争对手GPU架构最大的本质区别。想通过目前为止最优秀的GPU技术一窥未来图形芯片的发展方向吗?本章将从浅显到深刻,为大家打开通用计算GPU的大门!
10.1 异构计算的威力和不足

GPU的性能远远超出了CPU的想象
针对非图形应用程序的GPU编程的探索始于2003年。通过使用高级绘制语言如DirectX、OpenGL和Cg,将多种数据平行算法导入GPU。诸如蛋白质折叠、股票期权定价、SQL查询及MRI重建等问题都能通过GPU获得非凡的加速表现。早期将图形API用于通用计算的努力被称之为GPGPU(GPU通用计算)。
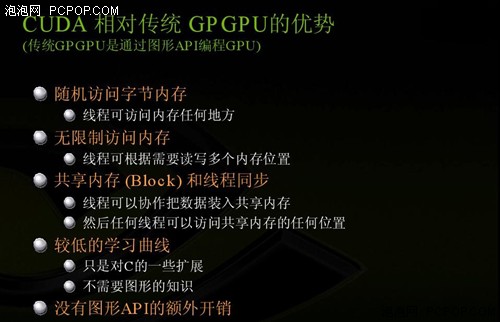
虽然GPGPU模型展现了不俗的加速性能,但仍然有不少缺陷:
首先,它要求程序员全面掌握与图形API以及GPU架构相关的知识;
其次,问题必须以顶点坐标、纹理及着色器程序的形式表达出来,这就大大增加了程序的复杂程度;第三,不支持基础的编程特性如面向内存的随机读写,极大地限制了编程模型;最后,缺乏双精度支持(直到最近才具备这一特性)意味着有些科学应用程序将不能在GPU上运行。
为了解决这些问题,NVIDIA采用了两种关键技术——G80统一图形及计算架构和CUDA。CUDA是一种软硬件架构,可以使用多种高级编程语言来针对GPU进行编程。这两种技术代表着一种新的应用GPU的方式。跟以前通过编程将专门的图形单元同图形API结合到一起不同,程序员可以利用CUDA的扩展来编写C语言程序,并面向一个通用的平行处理器。NVIDIA将这种新的GPU编程方式称为“GPU计算”,它意味着更广泛的应用程序支持、更多编程语言的支持以及同早期GPGPU编程模型的彻底分离。
G80标量流处理器架构的诞生使得全新的GPU计算成为可能,并创造了无数项第一:
第一款支持C语言的GPU,它让程序员可以利用GPU的运算能力而无需掌握一门新的编程语言;
第一款以单一的非统一的处理器取代分离式顶点及像素管线的GPU,这种处理器可以执行顶点、几何、像素及计算程序;
第一款利用标量线程处理器的GPU,从而使得程序员无需手工操控向量寄存器。
G80还采用了单指令、多线程(SIMT)的执行模型,多个独立线程同时执行单个指令,并针对线程间通信采用了共用存储器和障栅同步。
之后NVIDIA又对G80架构进行了重大改进,第二代统一架构GT200将流处理器的数量从128增加到了240个。每一个处理器的寄存器数量增倍,使得任何时候都可以在芯片上处理更多的线程。采用了硬件存储器存取合并技术以提高存储器存取的效率。此外,还采用了双精度浮点运算支持以满足那些科学及高性能计算(HPC)应用程序的需求。
在设计每款新一代GPU时,都必须遵循这样的原则——提高当前应用程序的性能及GPU的可编程性。应用程序的速度提高会立竿见影地带来诸多好处。正是GPU在可编程性方面的不断进步才使得它演变成为当前最通用的并行处理器。也正是基于这样的理念,GT200架构的继任者又被赋予了更多新的功能。
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}

