

决战性能之巅!NV双芯旗舰GTX590评测
NVIDIA在与程序员的沟通与反馈中发现,虽然共享内存能够惠及许多问题,但它并不能够用于解决所有问题。一些算法会自然而言地关联到共享内存,另一些则要求高速缓存,还有一些要求二者的组合。非常好的的内存层级结构应能够同时为共享内存和高速缓存带来优势,同时让编程人员可以选择在二者之上进行设计。Fermi内存层级结构支持两种类型的程序行为。
10.5 首次支持显存ECC
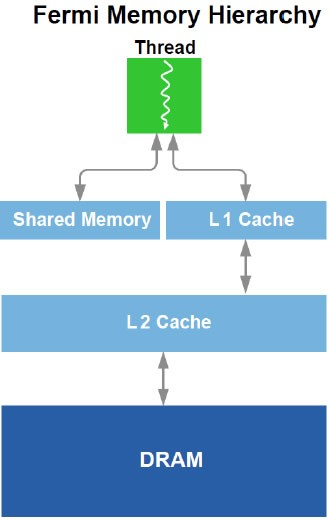
Fermi的缓存层级:其中对于并行计算无用的纹理缓存已被剔除
为加载/存储操作添加一个真正的高速缓存层级结构会带来严峻挑战。传统的GPU架构为纹理操作提供了只读“加载”路径,同时为像素数据输出提供了只写“输出”路径。然而,这一方法在执行要求同时进行读写的通用C或C++线程程序时表现非常不佳。例如,向内存发起一个寄存瀑然后再读回会形成写后读威胁。如果读和写路径不同,可能会直接覆盖掉整个写/“导出”路径,而无法正确发起读操作,从而使得读路径上的任意高速缓存不能与写数据保持一致。
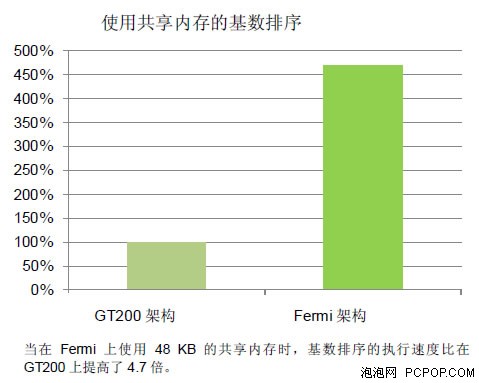
Fermi通过为加载和存储提供单个统一的内存请求路径解决了这一挑战,这一方法为每一个SM多处理器提供一个一级高速缓存,同时设置统一的二级高速缓存,以支持所有操作(加载、存储和纹理)。每个SM多处理器上的一级高速缓存可以进行配置,以支持共享内存和缓存本地与全局内存操作。64KB的内存可分出48 KB用作共享内存,16KB用作一级高速缓存;或者16KB用作共享内存,48KB用作一级高速缓存。当提供48KB的共享内存时,需要广泛使用共享内存的程序(如电子动态模拟)的性能将可以提高三倍。对于预先无法确定内存访问情况的程序,设置48KB的一级高速缓存将能够比直接访问DRAM带来显著改进的性能。
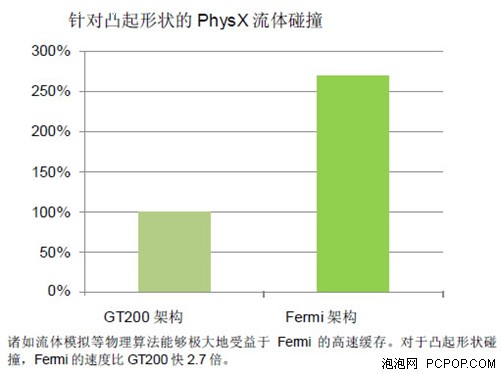
在任意一种配置中,一级高速缓存都可以通过缓存复杂程序的临时寄存器溢出对性能有所帮助。前一代GPU将寄存器直接交给DRAM,从而增加了访问延迟。通过使用一级高速缓存,性能能够随着临时寄存器容量的增加逐步提升。
Fermi采用了一个768KB统一二级高速缓存,用于支持所有加载、存储和纹理请求。二级高速缓存在GPU之间提供了有效、高速的数据共享。针对以前未知的数据地址的算法,如Physics Solver、光线追踪以及稀疏矩阵相乘等,将能够从这一高速缓存结构中受益最大。此外,要求多个SM来读取同一数据的过滤器和卷积内核也能够从中受益。
● 第一款支持ECC显存的GPU
Fermi是第一个在显存中提供了基于纠错码(ECC)的数据保护功能的GPU。CPU计算用户使用ECC来在高性能计算环境中增强数据完整性。ECC是诸如医疗成像以及大型集群计算等领域中一个迫切需要的特性。
自然发生的辐射可能导致内存中的数据被更改,导致软错误。ECC技术能够在单位软错误影响系统之前就予以发现并进行纠正。由于此类辐射所致错误的可能性随已安装系统的数量直线增长,ECC是大型集群部署中的一个必备要求。
Fermi支持单错纠正双错检测(SECDED)ECC代码,能够在数据被访问期间纠正硬件中的任意单位错误。此外,SECDED ECC还确保了所有双位错误和众多多位错误能够被发现和报告,以便能够重新运行程序,而不是继续执行不良数据。
Fermi的寄存器文件、共享内存、一级高速缓存、二级高速缓存和显存均提供有ECC保护功能,从而不仅是适用于HPC应用的最强大GPU,同时也是最可靠的GPU。此外,Fermi还支持行业标准,能够当在芯片间传输数据时对其进行检查。所有NVIDIA GPU均支持用于CRC检查的PCI-E标准,能够在数据链路层进行重试。Fermi还支持用于CRC检查的同类GDDR5标准,能够当数据在内存总线上传输时进行重试(也称作“EDC”)。
是否支持ECC,成为GeForce与Tesla的最大区别,当然Tesla还配备了更大容量的显存,为密集型数据处理提供更高的性能。
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}

