

三张新显卡齐发布!一文总结英伟达RTX 40系列显卡亮点何在
9月20日的晚上11点,英伟达召开了主题为“AI 和元宇宙时代的加速计算大会”的GTC活动。在此次的GTC活动上,英伟达在时隔两年后,正式发布了新一代的显卡产品——RTX 40系列显卡。

此次英伟达发布的RTX40系列显卡共有三款产品,分别是RTX 4090、RTX 4080 16GB、RTX 4080 12GB三款显卡,这三款显卡都换用了全新的核心架构,其架构命名延续了英伟达从历史知名科学人物上取材的命名传统,定名为Ada Lovelace (艾达·洛夫莱斯)架构。

关于Ada Lovelace (艾达·洛夫莱斯):这一位女性是著名英国诗人拜伦之女,数学家。计算机程序创始人,建立了循环和子程序概念,被认为是计算机程序的创始人。
关于此次发布的RTX 40系列显卡:
英伟达在这一次发布的RTX 40系列显卡采用的是全新的Ada Lovelace (艾达·洛夫莱斯)架构核心,这核心采用的是来自台积电的4nm工艺制造,拥有760亿个晶体管和超过18000个CUDA核心,相比较于上一代Ampere架构核心多了70%。

作为此次发布的RTX 40系列显卡核心,Ada Lovelace 核心将其中的SM多单元处理器、RT Core(光追核心)以及Tensor Core(可理解为AI核心)都进行了换代升级,其中的RT Core(光追核心)拥有两倍的光线与三角形求交性能,并且通过全新的引擎来减少了开销,Tensor Core则是提升了性能。

Ada Lovelace 核心性能提升的一大关键是来自于SM多单元处理器方面的升级,英伟达全新引入了Shader Execution Reordering这一项着色器执行重排序技术,通俗的话说起来就是让GPU的处理过程也有了类似于CPU处理过程中的乱序处理能力,可以有效的提升性能,可获得2-3倍的光线追踪性能提升。
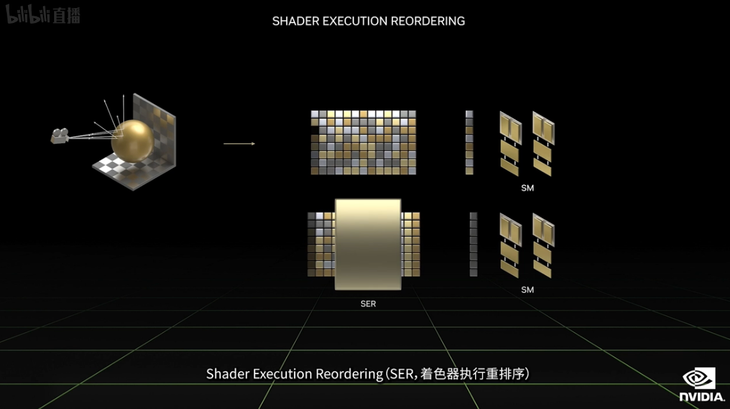
而RTX 40系列显卡除了换用全新的Ada Lovelace 核心获得性能提升以外,还加入了DLSS 3.0技术,DLSS 3.0技术包含四项组件,而在其中最为关键的是新加入的AI帧生成器。而这一个技术相比较于DLSS 2.0此前采用AI在高帧率帧和低帧率帧中进行读取重渲染的过程而生成中间帧的过程有所区别,DLSS 3.0是利用深度学习的AI在像素级帧到帧方向的运动、速度信息基础上进行预测并通过一系列的处理在不影响原有游戏处理管线的情况下进行中间帧的生成,大幅度提高了游戏的帧数表现。这一个DLSS 3.0技术在英伟达的演示中,表现非常出色,也是此次发布的三张RTX 40系列显卡原有极大性能提升的一个关键。
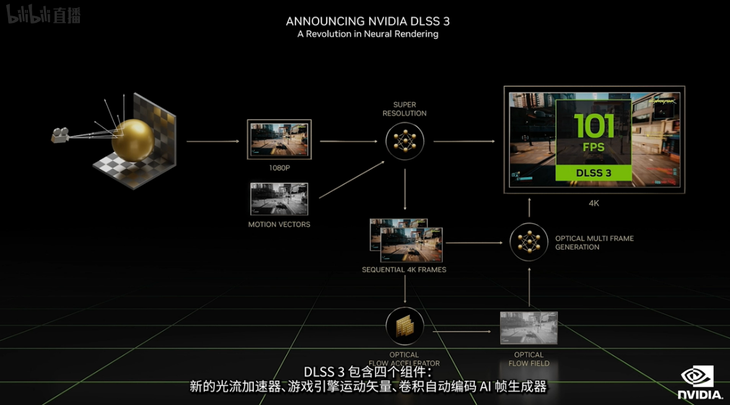

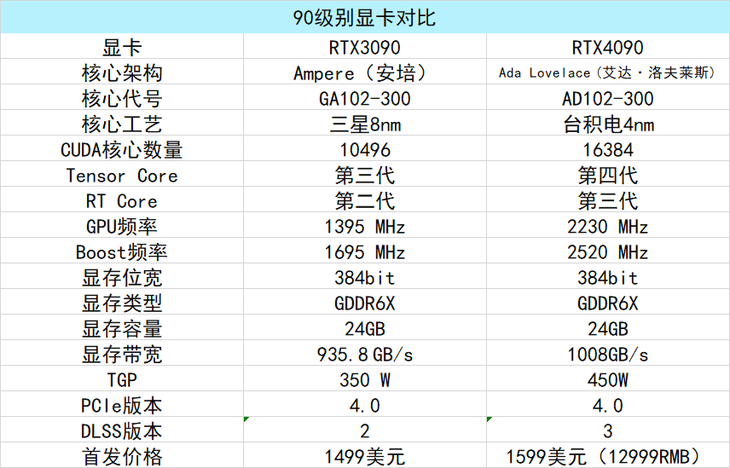
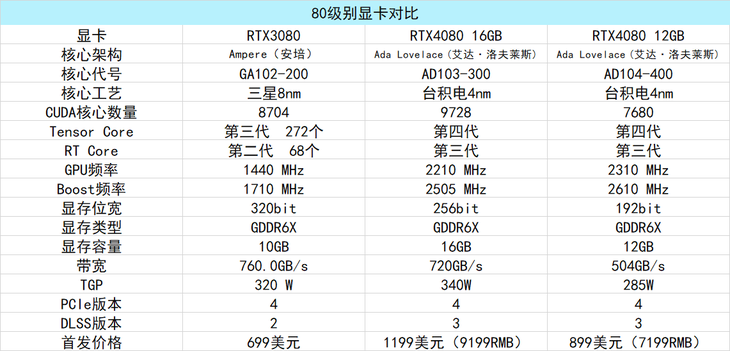
在具体的参数规格上,由于目前尚未更多的信息流出,例如RT核心数量、Tensor Core数量等信息,所以笔者汇总的这一个表格是RTX 40系列显卡的部分关键参数,大致可以作为参考。
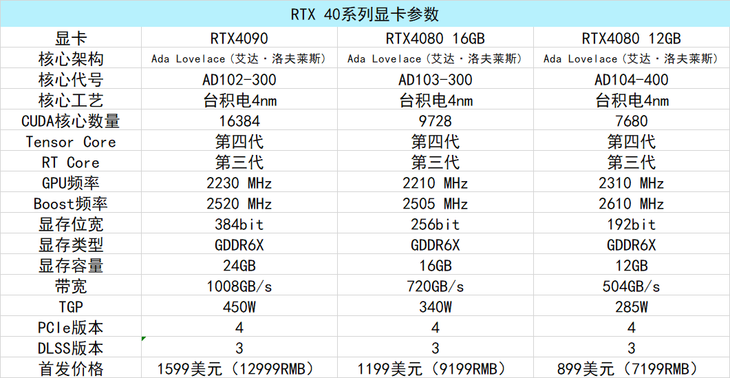
从英伟达公布的参数以及笔者收集到的参数信息可知,RTX 4090使用AD102-300核心 台积电4nm制程,配备24GB的美光GDDR6X显存拥有384bit显存位宽,显存带宽为1008GB/s。其核心配备的CUDA数量为16384,核心频率基准频率为2230MHz,BOOST频率为2520MHz,设计TGP为450W,定价为1599美刀,国内建议12999元起步。

RTX 3080 16GB使用AD103-300核心,台积电4nm制程,配备16GB的美光GDDR6X显存拥有256bit显存位宽,显存带宽为720GB/s。其核心配备的CUDA数量为9728,核心频率基准频率为2210MHz,BOOST频率为2505MHz,设计TGP为350W,定价为1199美刀,国内建议9199元起步。
RTX 3080 12GB使用AD103-400核心,台积电4nm制程,配备16GB的美光GDDR6X显存拥有192bit显存位宽,显存带宽为504GB/s。其核心配备的CUDA数量为7680,核心频率基准频率为2310MHz,BOOST频率为2610MHz,设计TGP为285W,定价为899美刀,国内建议7199元起步。

(个人认为这一个RTX 4080 12GB的规格更像是RTX 4070 Ti级别或者70级别的规格,但是老黄这波拉到80级别了,价格也是非常感人)。
以上是老黄发布的三款全新显卡参数以及价格,那么相比较于RTX 30系列同级别的显卡,这三种显卡提升在哪?
相比较RTX 30系列同级别显卡:
此次发布的RTX 40系列显卡从参数上一眼可知的就是其CUDA数量的大幅度升级,以及频率上的极大提升。这部分提升应该是得益于英伟达的设计改进以及台积电4nm工艺的组合,因此在性能方面,RTX 40系列的升级相比较于RTX 30系列的升级肯定是有,但具体的多少还需要实际测试才知道。
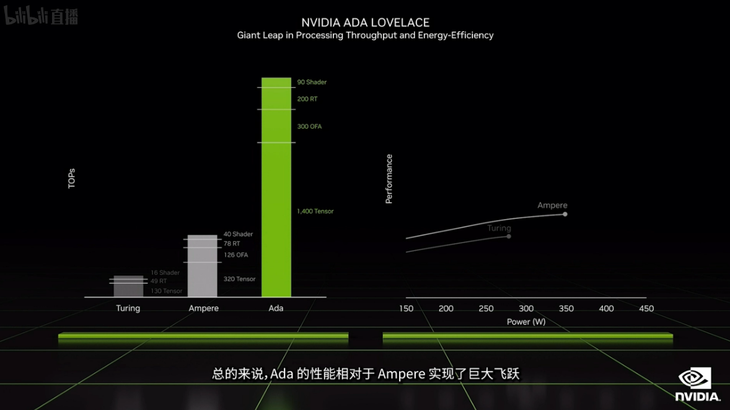
个人认为RTX 40系列相比较于RTX 30系列最大的升级来自于全新的SM多单元处理器、RT Core、Tensor Core加上DLSS 3.0技术带来的提升。个人的想法是,RTX 40系列显卡核心所配备的SM多单元处理器加入的Shader Execution Reordering带来了处理能力上的提升,RT Core则在光追性能上带来了升级。最为关键的提升应该是Tensor Core带来的AI算力、深度学习能力提升,以及建构在AI性能上DLSS 3.0带来的渲染中间帧性能升级,从而带来了游戏性能的提升(具体等待实测)。

相比较于RTX 30系列显卡,RTX 40系列可谓是在Shader+RT Core+Tensor Core+DLSS 3.0都拥有了全方位的提升,特别是其中Tensor Core+DLSS 3.0的升级,也符合了英伟达在后续提出的生产力以及自动驾驶等方面技术的一大基点(AI性能的需求升级)。除此之外,RTX 40系列的能耗比根据英伟达的说法,也是升级了不少,从RTX 4090系列相比较于RTX 3090仅提升100W的TGP而理论性能提升近翻倍的情况下,确实控制得还算可以。
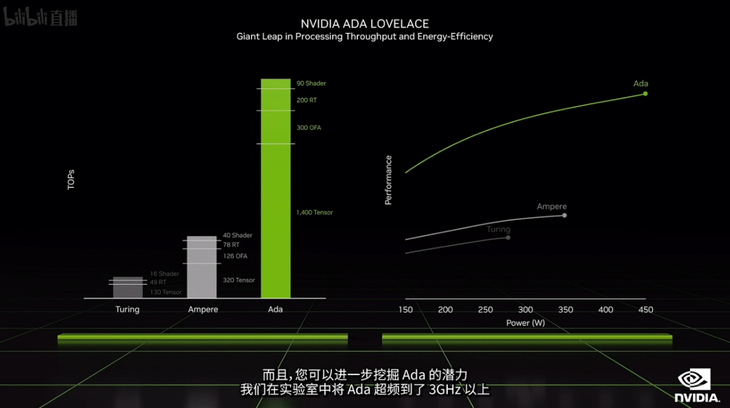
RTX 40系列显卡相比较于RTX 30系列显卡的升级,个人认为提升应该是较为明显的,但需要实测进一步来体现,对于游戏玩家来说,还需要等待一系列游戏适配支持,来充分发挥显卡的性能优势。而对于面向渲染、AI之类的学习来说,RTX 40系列的也是相比较于RTX 30好上不少。
当然RTX 40系列的价格也是相比较于RTX 30系列高上挺多,RTX 4080 12GB的价格居然要拉到899美刀起售,国内建议零售价为7199元起,这个价格,摆明了老黄想继续清RTX 30系列显卡的心态了。
总结一下想法:
其实看完发布会全程,可以发现,老黄对于显卡的介绍匆匆带过,后续讲的很多的内容都是围绕本次大会的主题:“AI 和元宇宙时代的加速计算大会”,重点讲述了英伟达Omniverse在元宇宙这一方面的强力作用。AI在自动驾驶领域等方面的应用等,整一场大会的核心内容是To B端的,RTX 40系列更像是在To B过程中拿出一部分的技术进行下放带给To C用户的内容,RTX 40系列显卡上升级非常明显的Tensor Core加上DLSS 3.0或许就是来源于To B的技术。


重点转向To B,加上此前传闻RTX 30系列显卡拥有过多的挤压库存,或许就是此次RTX 40系列显卡定价高昂的一大原因,单价的提升有利于英伟达在市场整体需求下降的情况下,可以用更高的利润率来获得相近的收入,而我们也可以看到,相比较于往年的80/70级别显卡,此次的RTX 4080显卡定价可谓非常高。在今晚发布的三张RTX 4090系列显卡中,RTX 4090显卡或将拥有最高的性价比,对于极致发烧的游戏玩家、渲染工作的用户、需要AI能力来“炼丹”的用户来说,RTX 4090相比较于RTX 3090提价并不多,性价比应该是最高的。(但是这一代显卡的价格是真贵啊,不知道有多少计划购买80/70级别显卡的游戏玩家这波要被劝退,DIY市场太难了)
英伟达在这一次GTC大会提出的部分观点个人也是比较认可的,随着显卡性能的提升,未来的游戏可以无预先的烘焙,而是来自实时的烘焙渲染技术而来的,未来的游戏世界将是仿真的世界。因此希望无论是游戏也好、元宇宙也罢,随着技术的发展,可以为我们带来另一种平行世界的时空体验吧。


关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}