

冷静的怪兽!索泰3GB显存 GTX580评测
如果你是个老鸟,那对GTX480高发热高功耗的事儿应该还记忆犹新。其实GTX480屏蔽流处理器的还有一个原因,就是40nm工艺良品率的问题。关于40nm的良率问题自从AMD迈入40nm工艺制程之后业界就经常有报道,AMD和NVIDIA也都表过态说受到了这方面的影响,甚至之前有消息说GTX400的合格产品只有20%,最后NVIDIA出于无奈只好屏蔽一组流处理器。
而且,发布之前NVIDIA虽然口口声声说GTX480是史上最完美的芯片,但实际上他们心里很清楚如果再对工艺进行改进的话,GPU的运算效率还是有提升空间的。一来可以解决良品率的问题,二来还可以提升效率,所以在GTX480发布之后,NVIDIA和台积电就开始研究如何改进40nm的生产工艺。
● GTX580发布,不只提升流处理器数量
在GTX480在质疑声中度过了卡皇岁月之后,NVIDIA发布了GF100核心的改进版本——GF110,直接对应的零售产品就是GTX580:

● 流处理器数量提升
大家已经知道,GTX580从某种角度上来说是GTX480的改进版本,首先是弥补了GTX480在流处理器数量上的遗憾,从GTX480的480个流处理器提升到了512个流处理器,这样在显卡的3D性能上就有进一步的提升。

● 16/48KB动态分配缓存
GF100/GF110核心的缓存设计非常有意思,采用的是L1和共享缓存动态分配总容量为64KB缓存的设计,这部分缓存可配置为16KB的一级缓存+48KB共享缓存,或者是48KB一级缓存+16KB共享缓存。这种划分方式完全是动态执行的,一个时钟周期之后可自动根据任务需要即时切换而不需要程序主动干预。
一级缓存与共享缓存是互补的,共享缓存能够为明确界定存取数据的算法提升存取速度,而一级缓存则能够为一些不规则的算法提升存储器存取速度。在这些不规则算法中,事先并不知道数据地址。
● 4个纹理单元
顾名思义,纹理单元就是专门用于渲染3D物体表面纹理的模块,在图形纹理越来越复杂的今天,纹理单元的重要性不言而喻。GTX580因为相对于GTX480增加了一组SM,所以纹理单元数量也得到了相应的增加。
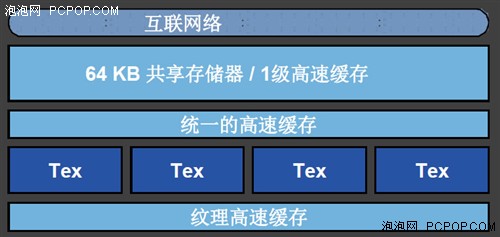
在GF100/110架构中,每一组SM中包含4个纹理单元,完整版的核心中一共有16个SM,所以GTX580一共拥有64个纹理单元,而GTX480由于屏蔽了一组SM,所以只有60个纹理单元。
值得一提的是,GF100/110架构中的纹理单元直接集成到了SM内部,且每组SM中拥有独立的纹理缓存(4个纹理单元共享这部分独立的纹理缓存),这样的设计打破了之前纹理单元一直被设计在SM外围的传统,有效的提升了纹理效率。虽然从纹理单元的数量方面来说看起来比GT200架构还少,但实际效率却高很多。
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}

