

HD7970脱胎换骨全测试!5年架构大革命
第二章/第九节 GPU的一大步:NVIDIA G80图形架构解析
AMD的GPU架构介绍了这么多,对于其优缺点也心知肚明了,之前笔者反复提到了“效率”二字,其参照物当然就是NVIDIA的GPU,现在我们就来看看NVIDIA的GPU架构有什么特点,效率为什么会比较高?为什么更适合并行计算?
SIMD效率不高的根本原因
无论AMD怎么调整架构,5D还是4D的结构都还是SIMD,也就是这4-5个ALU要共用一个指令发射端口,这样就对GPU指令派发器提出了很高的要求:如果没有把4-5个指令打包好发送到过来,那么运算单元就不会全速运行;如果发送过来的4-5个指令当中包含条件指令,但运行效率就会降至连50%都不到,造成灾难性的资源浪费。
解决方法也不是没有,但都治标不治本,需要对游戏/程序本身进行优化,尽量避免使用标量指令、条件指令和混合指令,驱动为程序专门做优化,难度可想而知。
而治本的方法就是抛弃SIMD架构,从源头上解决指令组合预分配的问题。
G80革命性的MIMD架构
NVIDIA的科学家对图形指令结构进行了深入研究,它们发现标量数据流所占比例正在逐年提升,如果渲染单元还是坚持SIMD设计会让效率下降。为此NVIDIA在G80中做出大胆变革:流处理器不再针对矢量设计,而是统统改成了标量ALU单元,这种架构叫做MIMD(Multiple Instruction Multiple Data,多指令多数据流)
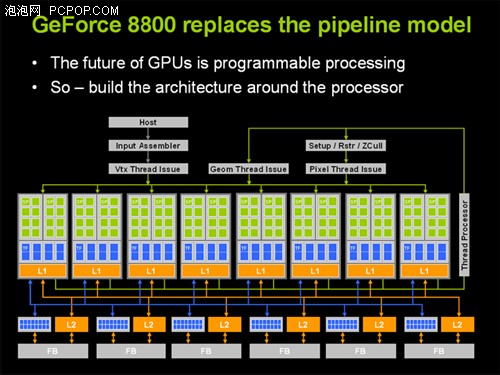
G80核心架构,每个流处理器就是一个标量ALU
如此一来,对于依然占据主流的4D矢量操作来说,G80需要让1个流处理器在4个周期内才能完成,或者是调动4个流处理器在1个周期内完成,那么G80的执行效率岂不是很低?没错,所以NVIDIA大幅提升了流处理器工作频率(两倍于核心频率),扩充了流处理器的规模(128个),这样G80的128个标量流处理器的运算能力就基本相当于传统的64个(128×2?)4D矢量ALU。大家应该知道R600拥有64个5D矢量ALU,最终的性能G80要远胜R600。
当然这只是在处理4D指令时的情形,随着图形画面越来越复杂,1D、2D、3D指令所占比例正在逐年增多,而G80在遇到这种指令时可说是如鱼得水,与4D一样不会有任何效能损失,指令转换效率高并且对指令的适应性非常好,这样G80就将GPU Shader执行效率提升到了新的境界!
MIMD架构的劣势
G80的架构听起来很完美,但也存在不可忽视的缺点:根据前面的分析可以得知,4个1D标量ALU和1个4D矢量ALU的运算能力是相当的,但是前者需要4个指令发射端和4个控制单元,而后者只需要1个,如此一来MIMD架构所占用的晶体管数将远大于SIMD架构!
所以AMD的SIMD架构可以用较少的晶体管造出庞大数量的流处理器、拥有恐怖的理论浮点运算能力;而NVIDIA的MIMD架构必须使用更多的晶体管制造出看似比较少的流处理器,理论浮点运算能力相差很远。双方走的都是极端路线,AMD以数量弥补效率的不足,而NVIDIA以效率弥补数量的劣势。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}