

HD7970脱胎换骨全测试!5年架构大革命
第二章/第四节 HD2900XT走向不归路:超长指令集的弊端
R520->R580的成功,多达48个着色单元功不可没,这让ATI对庞大的ALU运算单元深信不疑。ATI认为只要继续扩充着色单元,就能满足新一代DX10及Shader Model 3.0的要求。
着色单元的结构:
在图形处理中,最常见的像素都是由RGB(红黄蓝)三种颜色构成的,加上它们共有的信息说明(Alpha),总共是4个通道。而顶点数据一般是由XYZW四个坐标构成,这样也是4个通道。在3D图形进行渲染时,其实就是改变RGBA四个通道或者XYZW四个坐标的数值。为了一次性处理1个完整的像素渲染或几何转换,GPU的像素着色单元和顶点着色单元从一开始就被设计成为同时具备4次运算能力的运算器(ALU)。
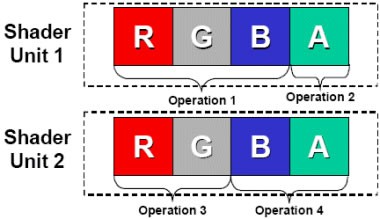
数据的基本单元是Scalar(标量),就是指一个单独的值,GPU的ALU进行一次这种变量操作,被称做1D标量。由于传统GPU的ALU在一个时钟周期可以同时执行4次这样的并行运算,所以ALU的操作被称做4D Vector(矢量)操作。一个矢量就是N个标量,一般来说绝大多数图形指令中N=4。所以,GPU的ALU指令发射端只有一个,但却可以同时运算4个通道的数据,这就是SIMD(Single Instruction Multiple Data,单指令多数据流)架构。
R580的Shader单元结构
显然,SIMD架构能够有效提升GPU的矢量处理性能,由于VS和PS的绝大部分运算都是4D Vector,它只需要一个指令端口就能在单周期内完成4倍运算量,效率达到100%。但是4D SIMD架构一旦遇到1D标量指令时,效率就会下降到原来的1/4,3/4的模块被完全浪费。为了缓解这个问题,ATI和NVIDIA在进入DX9时代后相继采用混合型设计,比如R300就采用了3D+1D的架构,允许Co-issue操作(矢量指令和标量指令可以并行执行),NV40以后的GPU支持2D+2D和3D+1D两种模式,虽然很大程度上缓解了标量指令执行效率低下的问题,但依然无法最大限度的发挥ALU运算能力,尤其是一旦遇上分支预测的情况,SIMD在矢量处理方面高效能的优势将会被损失殆尽。
DX10时代,混合型指令以及分支预测的情况更加频繁,传统的Shader结构必须做相应的改进以适应需求。NVIDIA的做法是将4D ALU全部打散,使用了MIMD(Multi Instruction Multiple Data,多指令多数据流),而AMD则继续沿用SIMD架构,但对Shader微架构进行了调整,称为超标量架构。
R600的5D超标量流处理器架构:
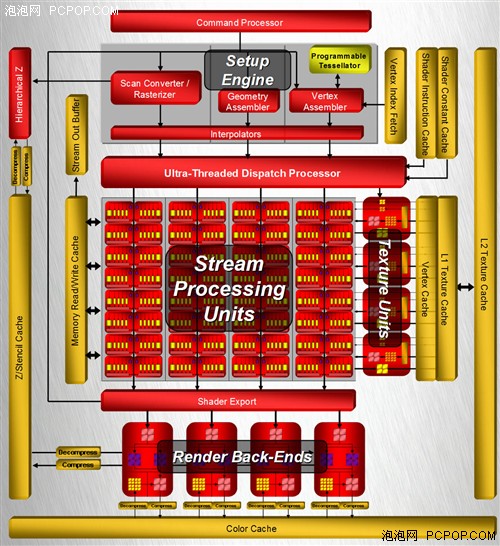
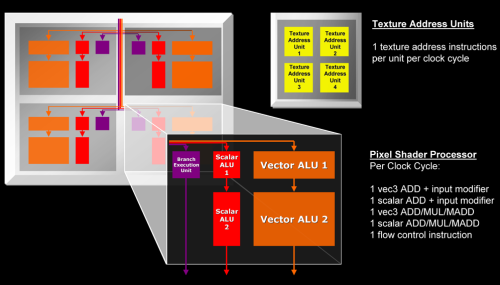
作为ATI的首款DX10 GPU,架构上还是有不少改进的,DX10统一渲染架构的引入,让传统的像素渲染单元和顶点渲染单元合二为一,统称为流处理器。R600总共拥有64个Shader单元,每个Shader内部有5个ALU,这样总计就是320个流处理器。

R600的Shader单元结构
R600的Shader有了很大幅度的改进,总共拥有5个ALU和1个分支执行单元,这个5个ALU都可以执行加法和乘加指令,其中1个"胖"的ALU除了乘加外之外还能够进行一些函数(SIN、COS、LOG、EXP等)运算,在特殊条件下提高运算效率!
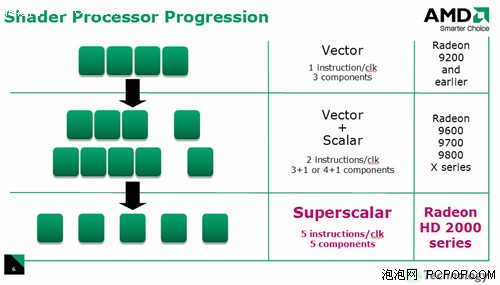
与R580不同的是,R600的ALU可以在动态流控制的支配下自由的处理任何组合形式的指令,诸如1+1+1+1+1、2+2+1、2+3、4+1等组合形式。所以AMD将R600的Shader架构称作Superscalar(超标量),完美支持Co-issue(矢量指令和标量指令并行执行)。
R600超长指令集的弊端:
从Shader内部结构来看,R600的确是超标量体系,但如果从整个GPU宏观角度来看,R600依然是SIMD(单指令多数据流)的VLIW(超长指令集)体系:5个ALU被捆绑在一个SIMD Shader单元内部,所有的ALU共用一个指令发射端口,这就意味着Shader必须获得完整的5D指令包,才能让内部5个ALU同时运行,一旦获得的数据包少于5条指令,或者存在条件指令,那么R600的执行效率就会大打折扣。
例如:指令一:a=b+c;指令二:d=a*e。这两条指令中,第二条指令中的a必须等待第一条指令的运算结果,出现这样的情况时候,两条指令大多数情况下就不能实现超标量执行了。
显然,想要完整发挥R600的性能必须满足苛刻的条件,这个条件不仅对驱动和编译器提出了额外的要求,而且要求程序必须让条件指令不存在任何关联性,难度可想而知。最终结果就是绝大多数情况下R600都无法发挥出的理论性能,而且其执行效率会因为复杂指令的增多而不断下降。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}