

开普勒秒杀GCN 新卡皇GTX680首发评测
最后再来看看开普勒架构在其它方面的改进:
● 多形体引擎2.0:
从GTX480开始,NVIDIA就宣称只有自己“做对了DX11”,因为GF100核心拥有多达16个多形体引擎,每个多形体引擎内部都有独立的曲面细分单元,而HD5870整颗Cypress核心只有1个曲面细分单元。通过专项测试来看,GTX480的曲面细分和几何性能都遥遥领先于HD5870。

AMD方面当然也意识到了孽弱的曲面细分性能是个瓶颈,一方面强调“曲面没必要分太细”,另一方面也在新一代产品中不断的加强曲面细分性能。根据AMD官方的说法,HD6870通过双超线程分配处理器将中等程度的曲面细分性能提高了2倍;HD6970通过双图形引擎又提升了2倍;而HD7970则重新设计了曲面细分单元,在所有等级下都可以达到HD6970的4倍!最终HD7970的曲面细分能力相比HD5870提升了10倍左右!
在AMD不断更新架构的同时,NVIDIA的DX11 GPU没有变化(GF110和GF100是一样的),显然HD7970的曲面细分性能已经超越了GTX580。这次该NVIDIA着急了。

在开普勒架构中,我们看到了多形体引擎2.0版,结构上没有什么变化,但处理能力翻倍了。NVIDIA称,Kepler的多形体引擎在同频率下的性能是Fermi的两倍,而且新引擎在重度曲面细分情况下的效率更高,性能损失更小。
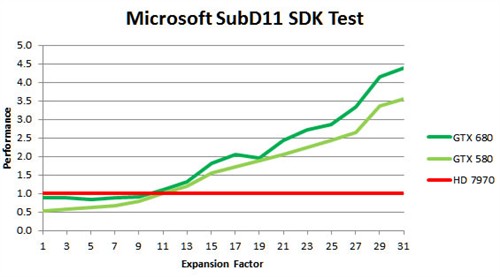
DX11理论曲面性能性能测试,横轴为细分级别
值得注意的是,GK104只有8个多形体引擎,而GF110有16个多形体引擎,但最终GTX680的曲面细分性能比GTX580还要强,看来单个引擎的效能确实翻倍了,超出那部分的性能应该是高达1GHz频率的贡献。
可以看出,NVIDIA的曲面细分单元在重度细分模式下的效率更好一些,低级别模式下HD7970并不差还略占优势,但级别越高差距就越大。根据目前DX11游戏的发展趋势来看,“曲面没必要分太细”的说法已经过时,不然AMD也就成倍的增加曲面细分性能了,未来的DX11游戏会加入高精度曲面细分引擎,届时N卡的优势会得到体现。
● 更快的高速缓存:
GK104的缓存设计与GF100没有区别,都是一级缓存、一级纹理缓存、二级缓存这样的层级设计,而且缓存容量的配比也没有变化,但因为模块化设计的关系,总容量有所减少。

缓存架构让各流水线之间可以高效地通信,减少了显存读写操作
GK104的每个SMX当中配有64KB的Shared Memory/L1,GK104总共拥有8个SMX,所以一级缓存的总容量是512KB。
GK104的每个光栅单元/64bit显存控制器配有128KB的L2,GK104总共有4个64bit显存控制器,所以二级缓存的总容量也是512KB。
与GF100的1MB一级缓存、768KB的二级缓存相比,GK104的缓存容量确实小了很多,这个可以通过芯片透视图明显的看出。
虽然缓存容量变小了,但速度快了很多,NVIDIA强调GK104的L2带宽比GF110增加了73%,其中改进的算法提高了30%的缓存命中率,另外的43%则是得益于高达1GHz的核心频率。此外,原子操作的吞吐量也大增3.5倍,尤其是单一共享地址的原子操作可提升11.7倍之多!
● 更多的纹理单元:
GK104的每个SMX内部拥有16个纹理单元,8个SMX总计128个纹理单元;GF110的每个SM内部拥有4个纹理单元,16个SM总计64个纹理单元;可以看出GK104这次大幅增加CUDA核心数量的同时,也没有忘记纹理单元。

除了数量翻倍之外,纹理存取的限制也放开了,以前因为DX11 API的限制,GPU最多只能对128个纹理进行操作,而现在GK104可以使用超过100万像素的纹理贴图,而且可以并行的对多个纹理同时操作,在使用超大纹理时的CPU占用率大幅下降。但由于微软DirectX API的限制,目前GK104的这些特性还只能在OpenGL API中体现,未来版本的DirectX可能会加入支持。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}