

开普勒秒杀GCN 新卡皇GTX680首发评测
尽管AMD的架构在向NVIDIA靠拢,但双方还是有明显区别,而且NVIDIA也在不断的改变。至于NVIDIA和AMD历代产品架构上的变化,之前多篇文章中都已经交代过了,这里就不再重复,我们通过这个简单的数字变化,来了解一下:
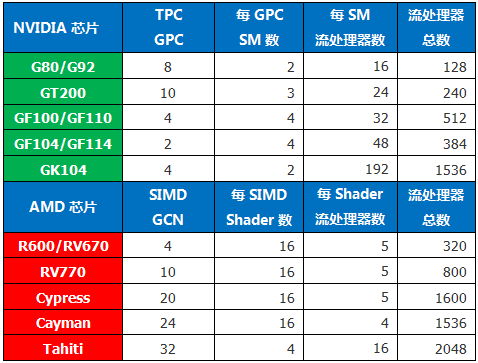
先看看AMD方面,从R600一直到Cypress,可以说一直在堆SIMD,动辄翻倍,架构没有任何变化;从Cypress到Cayman变化也不大,只是把矢量单元从5D改为4D;从Cayman到Tahiti可以说是质变,SIMD被GCN取代,4D矢量运算单元改为1D标量运算单元。
而NVIDIA方面,则是不停的对GPU的GPC、SM、CUDA核心等配比进行微调,在微调的过程中经历了两次突变:第一次是GT200到GF100,首次引出了GPC(图形处理器集群)的概念,GPC数量减少但SM数以及流处理器数量增加不少;第二次就是现在了,从GF100到GK104,SM数量减少,但流处理器数量暴增!
改变是为了适应形式的变化,解决此前出现的一些问题,那NVIDIA的架构有什么问题呢?此前我们多次提到过,虽然NVIDIA的GPU在效能方面占尽优势,但也不是完美无缺的——NVIDIA最大的劣势就是流处理器数量较少,导致理论浮点运算能力较低。当然这只是表面现象,其背后的本质则是MIMD(多指令多数据流)的架构,相当一部分比例的晶体管消耗在了指令发射端和控制逻辑单元上面,所以流处理器数量始终低于对手。
GF110和GK104芯片对比图
为了保证GPU性能持续增长,NVIDIA必须耗费更多的晶体管、制造出更大的GPU核心,而这些都需要先进的、成熟的半导体制造工艺的支持。NVIDIA之所以在GF100(GTX480)时代落败,并非架构或者研发端出了什么问题(GF110/GTX580的成功可以证明),而是核心太大导致40nm工艺无法支撑,良率低下漏电流难以控制,最终导致核心不完整且功耗巨大。如此一来,NVIDIA原有的架构严重受制于制造工艺,并非可持续发展之路。
为此,NVIDIA将芯片架构逐步转向了SIMT的模式,即Single Instruction Multiple Threads(单指令多线程),SIMT有别与AMD的SIMD,SIMT的好处就是无需开发者费力把数据凑成合适的矢量长度,并且SIMT允许每个线程有不同的分支。 纯粹使用SIMD不能并行的执行有条件跳转的函数,很显然条件跳转会根据输入数据不同在不同的线程中有不同表现,这个只有利用SIMT才能做到。
SIMT在硬件部分的结构还是要比SIMD复杂一些,NVIDIA还是更注重效率一些,所以NVIDIA的流处理器数量还是要比AMD少,但差距已经没以前那么夸张了。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}