

开普勒秒杀GCN 新卡皇GTX680首发评测
基于效能和计算能力方面的考虑,NVIDIA与AMD不约而同的改变了架构,NVIDIA虽然还是采用SIMT架构,但也借鉴了AMD“较老”的SIMD架构之作法,降低控制逻辑单元和指令发射器的比例,用较少的逻辑单元去控制更多的CUDA核心。于是一组SM当中容纳了192个核心的壮举就变成了现实!

通过上面这个示意图就看的很清楚了,CUDA核心的缩小主要归功于28nm工艺的使用,而如此之多的CUDA核心,与之搭配的控制逻辑单元面积反而缩小了,NVIDIA强化运算单元削减控制单元的意图就很明显了。
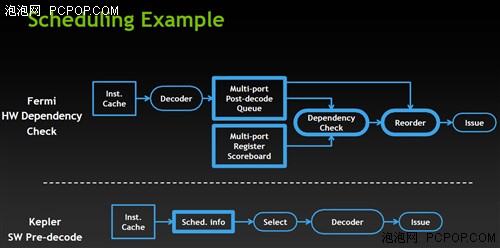
Fermi的硬件相关性检查变为Kepler的软件预解码
此时相信有人会问,降低控制单元的比例那是不是意味着NVIDIA赖以成名的高效率架构将会一去不复返了?理论上来说效率肯定会有损失,但实际上并没有想象中的那么严重。NVIDIA发现线程的调度有一定的规律性,编译器所发出的条件指令可以被预测到,此前这部分工作是由专门的硬件单元来完成的,而现在可以用简单的程序来取代,这样就能节约不少的晶体管。
随意在开普勒中NVIDIA将一大部分指令派发和控制的操作交给了软件(驱动)来处理。而且GPU的架构并没有本质上的改变,只是结构和规模以及控制方式发生了变化,只要驱动支持到位,与游戏开发商保持紧密的合作,效率损失必然会降到最低——事实上NVIDIA著名的The Way策略就是干这一行的!

The Way(游戏之道)计划可以保证NVIDA的GPU架构与游戏完美兼容
这方面NVIDIA与AMD的思路和目的是相同的,但最终体现在架构上还是有所区别。NVIDIA的架构被称为SIMT(Single Instruction Multiple Threads,单指令多线程),NVIDIA并不像AMD那样把多少个运算单元捆绑为一组,而是以线程为单位自由分配,控制逻辑单元会根据线程的任务量和SM内部CUDA运算单元的负载来决定调动多少个CUDA核心进行计算,这一过程完全是动态的。
但不可忽视的是,软件预解码虽然大大节约了GPU的晶体管开销,让流处理器数量和运算能力大增,但对驱动和游戏优化提出了更高的要求,这种情况伴随着AMD度过了好多年,现在NVIDIA也要面对相同的问题了,希望他能做得更好一些。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}