

轻松读懂移动处理器 CPU微架构全解析
ISA 的“实现”需要借助各种微架构,现在的处理器微架构基本上涉及以下部分:
流水线化
多核、多线程
SIMD 向量
存储系统分层结构
流水线
早期一些采用非常简单的指令集(注意,我们说的不是 RISC)的电脑是采用单周期设计的,取指、解码、执行、写回都是放在同一个拍(周期)内顺序完成,此时的 CPI(每指令周期数)基本上是 1,但是这样设计的效率很低:当取指的时候,其余工位都只能瞎瞪眼等开饭,这样的设计也被称作非流水线化执行。
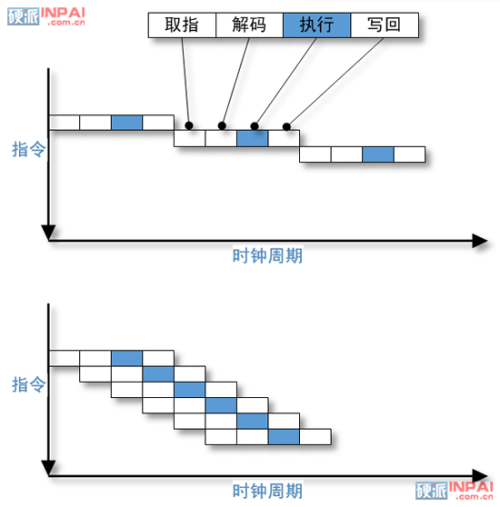
上:非流水线化(顺序化)执行
下:流水线化执行
流水线化则是实现各个工位不间断执行各自的任务,例如同样的四工位设计,指令拾取无需等待下一工位完成就进行下一条指令的拾取,其余工位亦然。
世界上第一台采用流水线化指令执行的电脑为 1961 年的 IBM Stretch 或者说 IBM 7030,具备四级流水线工位,它同时也是 IBM 第一台晶体管化电脑。
这样原本四工位非流水线的一个周期是 800 个皮秒的话,在流水线设计的处理器上,虽然同样的指令完成时间依然是 800 皮秒,但是第二条指令则可能只需要在第一条指令完成时间加 200 皮秒即第 1000 皮秒就能完成,而非流水线设计则需要第 1600 皮秒才能完成。
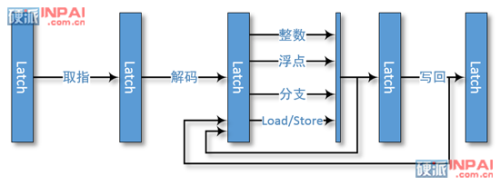
常见的五周期(FDEMW)流水线形式,对同步处理器来说 Latch 之间为一拍(周期)
对 Pentium 4 这类异步处理器来说,个别工位(simple ALU)频率为双倍即 1/2 拍
RISC 指令集具备指令编码格式统一、等长的特点,在流水线设计设计上有得天独厚的优势,这样可以使得流水线工位设计相对于指令编码格式不统一、非等长的 CISC(例如 x86 的指令长度为 1 个字节到 17 个字节不等)来说显得更容易。
x86 可能需要将一些工位拆开(这意味着流水线工位更多或者流水线长度更深),例如英特尔的第一款流水线化处理器——486 的指令解码就是拆成两个工位。
流水线设计可以让指令完成时间更短(理论上受限于流水线执行时间最长的工位),因此将一些工位再拆开的话,虽然依然是每个周期完成一条指令,但是“周期”更短意味着指令吞吐时间进一步缩短,每秒能跑出来的指令数更多,这就是超级流水线的初衷。
| 微架构 (Microarchitecture) |
流水线工位数 (Pipeline stages) |
|---|---|
| Sony Cell PPU | 23 |
| IBM PowerPC 7 | 17 |
| IBM Xenon | 19 |
| AMD Athlon | 10 |
| AMD Athlon XP | 11 |
| AMD Athlon64 | 12 |
| AMD Phenom | 12 |
| AMD Opteron | 15 |
| ARM7TDMI(-S) | 3 |
| ARM7EJ-S | 5 |
| ARM810 | 5 |
| ARM9TDMI | 5 |
| ARM1020E | 6 |
| XScale PXA210/PXA250 | 7 |
| ARM1136J(F)-S | 8 |
| ARM1156T2(F)-S | 9 |
| ARM Cortex-A5 | 8 |
| ARM Cortex-A8 | 13 |
| AVR32 AP7 | 7 |
| AVR32 UC3 | 3 |
| DLX | 5 |
| Intel P5 (Pentium) | 5 |
| Intel P6 (Pentium Pro) | 14 |
| Intel P6 (Pentium III) | 10 |
| Intel NetBurst (Willamette) | 20 |
| Intel NetBurst (Northwood) | 20 |
| Intel NetBurst (Prescott) | 31 |
| Intel NetBurst (Cedar Mill) | 31 |
| Intel Core | 14 |
| Intel Atom | 16 |
| LatticeMico32 | 6 |
| R4000 | 8 |
| StrongARM SA-110 | 5 |
| SuperH SH2 | 5 |
| SuperH SH2A | 5 |
| SuperH SH4 | 5 |
| SuperH SH4A | 7 |
| UltraSPARC | 9 |
| UltraSPARC T1 | 6 |
| UltraSPARC T2 | 8 |
| WinChip | 4 |
| LC2200 32 bit | 5 |
例如 Cortex-A15、Sandy Bridge 都分别具备 15 级、14 级流水线,而 Intel NetBurst(Pentium 4)、AMD Bulldozer 都是 20 级流水线,它们的工位数都远超出基本的四(或者五)工位流水线设计。更长的流水线虽然能提高频率,但是代价是耗电更高而且可能会有各种性能惩罚。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}