

轻松读懂移动处理器 CPU微架构全解析
无论是冯·诺依曼还是哈佛结构的处理器,最理想的情况下当然是有无限大的存储空间和 0 时延的存储系统了,不过这显然是无法做到的,因此人们就提出了分层式的存储系统结构,从寄存器开始每往下一层容量就更大,但是速度也更慢:
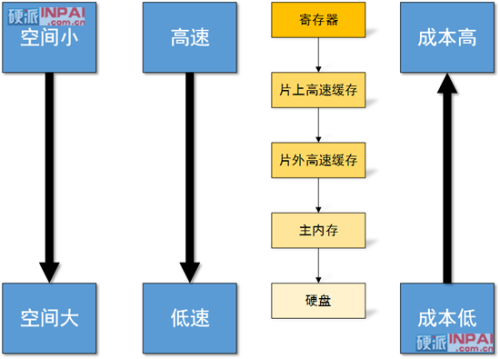
例如对于 ARM Cortex-A9(四核 Tegra 3 的批发报价一般为 15~21 美元)来说:
物理寄存器堆大小是 56*32-bit = 224 字节
L1 cache 是 32-KiB(时延 4 周期)
L2 Cache 是 1-MiB,不同大小区段的时延是:
- 64 KiB - 128KiB = L1C + L2C = 4 + 19 = 23 周期
- 256 KiB - 512 KiB = L1_C + L2_C + TLB_L1 = 4 + 19 + 7 = 30 周期
- 1 MiB = L1_C + L2_C + TLB_L1 + TLB_L2 = 4 + 19 + 7 +7 = 37 周期
不同型号的产品,搭配的内存容量不尽相同,以 华为 Ascend P1 XL 为例,搭配的内存大小为 1GiB,时延大概是 L2 + 110ns,带宽一般都有 1000MiB/s 以上。
基本上所有的手机都是采用 NAND 型闪存或者闪存卡作为 DASD(直接存取存储设备)来存放程序和数据,大小一般在 4 GiB 以上,如果搭配 Class 4 的 8 GiB microSD 卡的话读写带宽一般只有 1.x MiB/ss~3.x MiB/s(传输数据块大小为 4KiB 时)和 0.005 MiB/s~1.x MiB/s,价格一般为 20 元人民币左右 。
这里说的时延是从数据载入指令发出到数据抵达处理单元所需的时间,这通常并不难理解。
那么这里的 TLB 时延(TLB_L1/TLB_L2)又是怎么回事呢?这是因为虚拟内存的存在。
虚拟内存(virtual memory)的作用一般有两个:确保多个程序之间可以有效、安全地实现内存共享;让程序以为有大一块连续的内存空间(例如虚拟内存空间地址有 64-bit,但是我们的物理内存实际上只有 16GiB 或者说系统中的物理地址空间只有 34-bit,又或者是虚拟内存空间是 32-bit,而物理定址空间是 40-bit)。
对于用户程序在虚拟内存空间里操作的处理器,是需要把虚拟内存空间地址转换为物理内存空间地址,这就需要进行地址转换了。负责这个功能的单元一般被称作内存管理单元(MMU),有时候它又被称作分页内存管理单元,当然 MMU 的功能不仅仅是地址转换(否则就不会被盖这么大的名头了)。
内存的基本管理单位被称作 page(页面,或者说页块),不同处理器支持的页面大小不一样,一般都是 4KiB(在 ARMv7a 里还有 64 KiB、1MiB、16 MiB 等),性能导向型的处理器页面正变得越来越大,而嵌入式处理器似乎有 1KiB 大小的。
记录物理内存和虚拟内存关系里的数据列表被称作分页表,这些分页表也都是放在主内存(物理内存)中的,但是如果每次读写内存都要访问两次主内存的话效率太低了,所以人们引入了名为 TLB(Translate Look-aside Buffer,转换后缓存)的 cache 来改善这个问题。
不同的处理器 TLB 大小都不一样,以我们这里举例的 Cortex-A9 为例,本身就存在多种 TLB 配置形式,它的 L1 D-TLB 是 32 个条目(或者说分页地址映射),而 L1 I-TLB 可以配置为 32 或者 64 条目。
总之,早期的单周期式架构效率很差,因此人们引入了流水线设计,可以充分使用各级工位,各工位执行时间越短自然 CPU 的频率可以更快;然后人们又引入了超标量设计,让 CPU 上可以同时跑几条指令,随之而来的相依性等问题让架构师们想出了分支预测、乱序执行、寄存器重命名等等技术来保证处理器的指令执行效率。
除了提高指令并行度来改善处理器性能外,还有数据并行、线程化并行等方法,但是后两者都需要程序员和编译器协助,并非免费。
影响处理器性能还有内存的带宽和时延问题,因为取指和数据读写都必须透过内存访问来完成,层阶式设计是目前成本最为合理的方式。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}