

挑战卡皇TITAN!GTX 780 SLI巅峰测试
泡泡网显卡频道6月6日 从2001年开始到现在,NVIDIA和AMD两大图形巨头烽火已逾十年,卡皇之争最为惨烈,所以每一代旗舰的GPU核心,两家都不约而同的将晶体管集成数量推至物理散热极限的边缘,因此投入的边缘成本便成倍增加,旗舰显卡价格也居高不下。

就拿发布不久的GTX TITAN来说吧,它固然代表了单芯旗舰的最高水准,但价格高昂不说,稀有的产量也让各大卖场一卡难求。作为GTX TITAN的孪生兄弟,GTX 780只是在核心流处理器数量上有所删减,却保留了TITAN无可挑剔设计做工,组建双卡GTX780SLI更是在性能上傲视群雄!
SLI技术究竟完善与否?双卡平台又有哪些优缺点?今天泡泡评测室就为大家提供另一种神机配置方案,奉上NV显卡的旗舰对决——GTX 780 SLI大战GTX TITAN!

随着科学、医学、工程和金融各领域对高性能并行计算需求的增加,NVIDIA以无比强大的GPU计算架构来不断创新和满足这种需求。NVIDIA现有的 Fermi GPU已经重新定义和加速了以下领域的高性能计算(HPC)的功能,如地震处理、生化模拟、天气和气候建模、信号处理、计算金融、计算机辅助工程、计算流体力学和数据分析。NVIDIA的新Kepler GK110 GPU大大提高了并行计算标准,并将会帮助解决世界上面临的最困难的计算问题。

▲ NVIDIA GeForce GTX 780

▲ GTX 780采用的GK110核心
通过提供比上一代GPU更强大的处理功能以及优化和提高GPU上并行执行工作负载的新方法,Kepler GK110简化了并行程序的创建,将对会对高性能计算引起进一步改革。
Kepler GK110由71亿个晶体管组成,是有史以来架构最复杂的微处理器。GK110新加了许多注重计算性能创新功能,目的是要成为NVIDIA Tesla和HPC市场上的并行处理动力站。

Kepler GK110和GK104
Kepler GK110会提供超过每秒1万亿次双精度浮点计算的吞吐量,DGEMM效率大于80%,而之前的Fermi架构的效率是60‐65%。
除了性能之外,Kepler架构在电源效率方面也有巨大的飞跃,相对于Fermi 的性能/功率比提高了3倍之多!
之前有人说Kepler GK110更适合超级计算和通用计算,其实这是一种误解。Kepler GK110的以下新功能不仅提高GPU的利用率,简化了并行程序设计,而且有助于GPU在各种计算环境中部署,无论是从个人电脑还是超级计算机,GK110都适用:
Dynamic Parallelism – 能够让 GPU 在无需 CPU 介入的情况下,通过专用加速硬件路径为自己创造新的工作,对结果同步,并控制这项工作的调度。这种灵活性是为了适应程序执行过程中并行的数量和形式,编程人员可以处理更多的各种并行工作,更有效的将 GPU 用为计算用途。
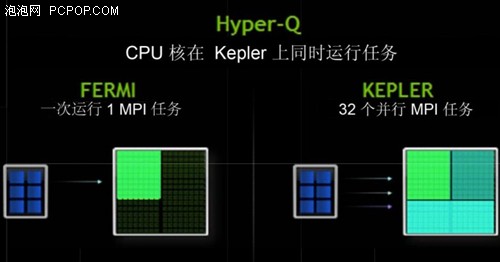
Hyper-Q – 允许多个CPU核同时在单一GPU上启动工作,从而大大提高了GPU 的利用率并削减了CPU空闲时间。Hyper‐Q 增加了主机和 Kepler GK110 GPU 之间的连接总数(工作队列),允许 32 个并发、硬件管理的连接(与 Fermi相比,Fermi 只允许单个连接)。
Grid Management Unit –使 Dynamic Parallelism 能够使用先进、灵活的 GRID 管理和调度控制系统。新 GK110 Grid Management Unit (GMU) 管理并按优先顺序在 GPU上执行的 Grid。GMU 可以暂停新 GRID 和等待队列的调度,并能中止 GRID,直到其能够执行时为止,这为 Dynamic Parallelism 这样的强大运行提供了灵活性。
NVIDIA GPUDirect–NVIDIA GPUDirect 能够使单个计算机内的 GPU 或位于网络内不同服务器内的 GPU 直接交换数据,无需进入CPU系统内存。GPUDirect 中的 RDMA 功能允许第三方设备,例如 SSD、NIC、和 IB 适配器,直接访问相同系统内多个 GPU 上的内存,大大降低 MPI从GPU内存发送/接收信息的延迟。还降低了系统内存带宽的要求并释放其他 CUDA 任务使用的 GPU DMA 引擎。
这里先做简单介绍,后面本文有详细的内容扩展。除此之外Kepler GK110 还支持其他的GPUDirect功能,包括Peer‐to‐Peer 和 GPUDirect for Video这里就不再赘述了。
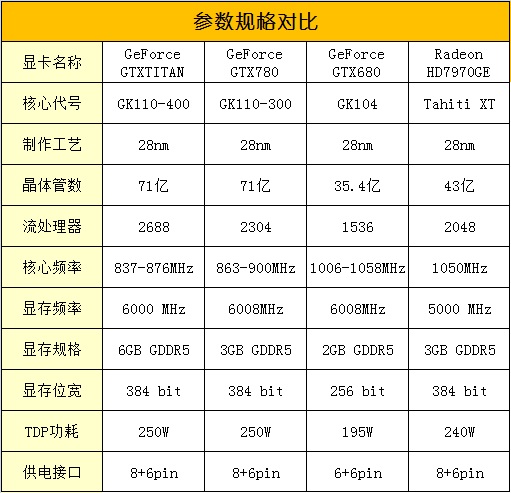
Kepler GK110为NVIDIA Tesla打造,其目标是成为世界上并行计算性能最高的微处理器。GK110 不仅大大超过由 Fermi 提供的原始计算能力,而且非常节能,显著减少电力消耗,同时产生的热量更少。完整 Kepler GK110 实施包括 15 SMX 单元和六个 64 位内存控制器。不同的产品将使用GK110 不同的配置。例如,某些产品可能部署 13 或 14 个 SMX。在下面进一步讨论的该架构的主要功能,包括:
1、新 SMX 处理器架构
2、增强的内存子系统,在每个层次提供额外的缓存能力,更多的带宽,且完全进行了重新设计,DRAM I/O 实施的速度大大加快。
3、贯穿整个设计的硬件支持使其具有新的编程模型功能

GK104框架规格
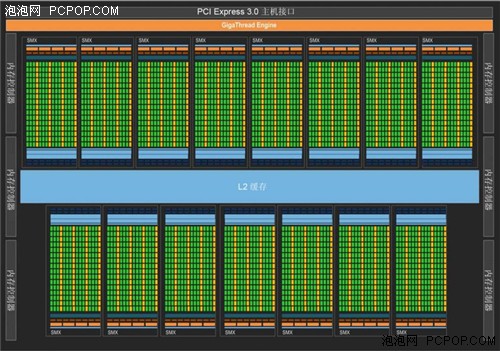
Kepler GK110芯片框图(GTX 780屏蔽了其中的两组SMX)
Kepler GK110 支持新 CUDA Compute Capability 3.5。(有关 CUDA 的简介请参考附录 A ‐CUDA 快速回顾)。下表对比了 Fermi 和 Kepler GPU 架构的不同计算能力的参数:
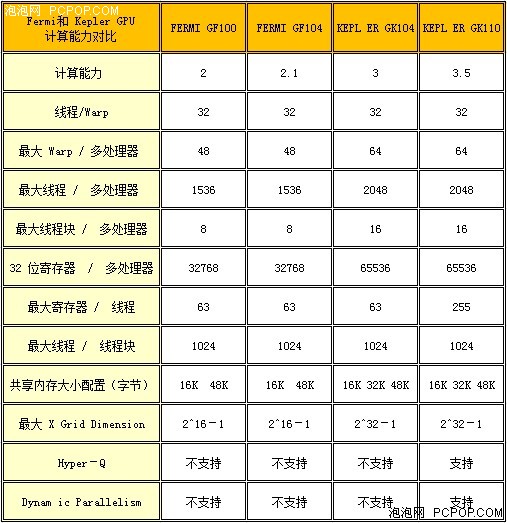
Fermi和Kepler GPU的计算能力
性能/功率比
Kepler架构的一个主要设计目标是提高电源效率。设计Kepler时,NVIDIA工程师应用从Fermi中积累的经验,以更好地优化Kepler、实现高效运行。台积电的 28nm 制造工艺在降低功耗方面起着重要的作用,但许多 GPU 架构需要修改,以进一步降低功耗,同时保持出色的性能。
Kepler每一个硬件设备都经过设计和擦洗,以提供卓越的性能/ 功率比。出色性能/功率比的非常好的案例是Kepler GK110新流式多处理器 (SMX) 中的设计,与最近Kepler GK104引入的 SMX 单元的许多方面类似,但计算算法包括更多双精度单位。
Kepler GK110的新SMX引入几个架构创新,使其不仅成为有史以来最强大的多处理器,而且更具编程性,更节能。
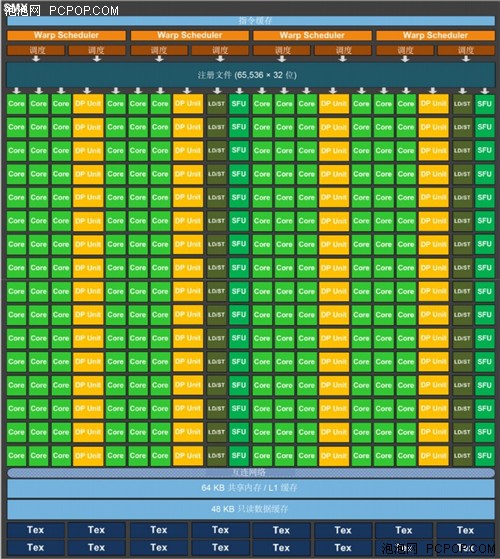
SMX: 192个单精度CUDA核、64个双精度单元、32个特殊功能单元(SFU)和32 个加载/存储单元(LD/ST)。
SMX 处理核架构
每个Kepler GK110 SMX单元具有192单精度CUDA核,每个核完全由浮点和整数算术逻辑单元组成。Kepler完全保留Fermi引入的IEEE 754-2008 标准的单精度和双精度算术,包括积和熔加(FMA)运算。
Kepler GK110 SMX 的设计目标之一是大大提高GPU的双精度性能,因为双精度算术是许多HPC应用的核心。Kepler GK110 的SMX还保留了特殊功能单元 (SFU)以达到和上一代GPU类似的快速超越运算,所提供的SFU数量是Fermi GF110 SM的8倍。
与GK104 SMX单元类似,GK110 SMX单元内的核使用主GPU频率而不是2倍的着色频率。2x着色频率在 G80 Tesla 架构的 GPU 中引入,并用于之后所有的 Tesla 和 Fermi‐架构的GPU。在更高时钟频率上运行执行单元使芯片使用较少量的执行单元达到特定目标的吞吐量,这实质上是一个面积优化,但速度更快的内核的时钟逻辑更耗电。对于Kepler,我们的首要任务是的性能/功率比。虽然我们做了很多面积和功耗方面的优化,但是我们更倾向优化功耗,甚至以增
加面积成本为代价使大量处理核在能耗少、低GPU频率情况下运行。
Quad Warp Scheduler
SMX以32个并行线程为一组的形式调度进程,这32个并行线程叫做Warp。而每个SMX中拥有四组 Warp Scheduler 和八组 Instruction Dispatch 单元,允许四个Warp同时发出执行。Kepler 的 Quad Warp Scheduler 选择四个 Warp,在每个循环中可以指派每 Warp 2 个独立的指令。与 Fermi 不同,Fermi 不允许双精度指令和部分其他指令配对,而 Kepler GK110 允许双精度指令和其他特定没有注册文件读取的指令配对 例如加载/存储指令、纹理指令以及一些整数型指令。
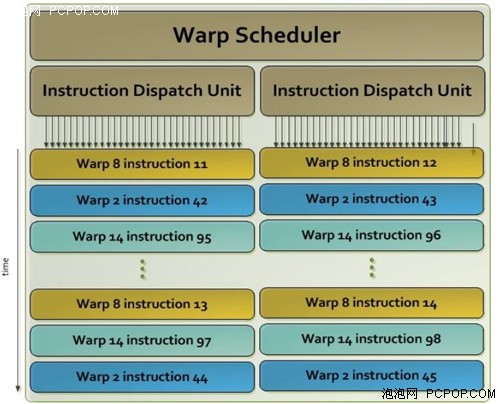
每个Kepler SMX 包含4组Warp Scheduler,每组Warp Scheduler包含两组 Instruction Dispatch单元。单个Warp Scheduler单元如上所示。
我们努力优化SMX Warp Scheduler逻辑中的能源。例如,Kepler和Fermi Scheduler 包含类似的硬件单元来处理调度功能。其中包括:
a) 记录长延迟操作(纹理和加载的寄存器
b) Warp 内调度决定(例如在合格的候选 Warp 中挑选出非常好的 Warp 运行)
c) 线程块级调度(例如,GigaThread 引擎)
然而,Fermi的scheduler还包含复杂的硬件以防止数据在其本身数学数据路径中的弊端。多端口寄存器记录板会纪录任何没有有效数据的寄存器,依赖检查块针对记录板分析多个完全解码的 Warp指令中寄存器的使用情况过,确定哪个有资格发出。
对于 Kepler ,我们认识到这一信息是确定性的(数学管道延迟是不变量),因此,编译器可以提前确定指令何时准备发出,并在指令中提供此信息。这样一来,我们就可以用硬件块替换几个复杂、耗电的块,其中硬件块提取出之前确定的延迟信息并将其用于在 Warp 间调度阶段屏蔽Warp,使其失去资格。
新ISA编码:每个线程255个寄存器
可由线程访问的寄存器的数量在 GK110 中已经翻了两番,允许线程最多访问 255 个寄存器。由于增加了每个线程可用的寄存器数量,Fermi 中承受很大寄存器压力或泄露行为的代码的速度能大大的提高。典型的例子是在 QUDA 库中使用 CUDA 执行格点 QCD(量子色动力学)计算。基于 QUDA fp64 的算法由于能够让每个线程使用更多寄存器并减少的本地内存泄漏,所以其性能提高了 5.3 倍。
Shuffle 指令
为了进一步提高性能,Kepler 采用 Shuffle 指令,它允许线程在 Warp 中共享数据。此前,Warp 内线程之间的数据共享需要存储和加载操作以通过共享内存传递数据。使用 Shuffle 指令,Warp 可以读取来自Warp 内其他线程中任意排列的值。Shuffle 支持任意索引引用(即任何线程读取任何其他线程)。有用的 Shuffle 子集包括下一线程(由固定量弥补抵消)和 Warp 中线程间 XOR “蝴蝶”式排列,也称为 CUDA 性。
Shuffle 性能优于共享内存,因此存储和加载操作能够一步完成。Shuffle 也可以减少每个线程块所需共享内存的数量,因为数据在 Warp 级交换也不需要放置在共享内存中。在 FFT 的情况下,需要共享一个 Warp 内的数据,通过使用 Shuffle 获得 6%的性能增益。
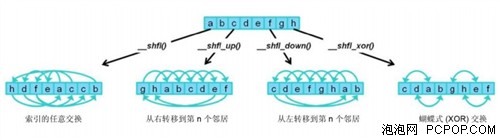
此示例表明某些变量可以在 Kepler 中使用 Shuffle 指令。
原子运算
原子内存运算对并行编程十分重要,允许并发线程对共享数据结构执行正确的读‐修改‐写运算。原子运算如 add、min、max 和 compare,swap 在某种意义上也是也是原子运算,如果在没有其他线程干扰的情况下执行读、修改和写运算。原子内存运算被广泛用于并行排序、归约运算、建制数据结构而同时不需要锁定线程顺序执行。
Kepler GK110 全局内存原子运算的吞吐量较 Fermi 时代有大幅的提高。普通全局内存地址的原子运算吞吐量相对于每频率一个运算来说提高了 9 倍。独立的全局地址的原子运算的吞吐量也明显加快,而且处理地址冲突的逻辑已经变得更有效。原子运算通常可以按照类似全局负载运算的速度进行处理。此速度的提高使得原子运算足够快得在内核内部循环中使用,消除之前一些算法整合结
果所需要的单独的归约传递。Kepler GK110 还扩展了对全局内存中 64‐位原子运算的本机支持。除了 atomicAdd、atomicCAS 和 atomicExch(也受 Fermi 和 Kepler GK104 支持)之外,GK110 还支持以下功能:
atomicMin、atomicMax、atomicAnd、atomicOr、atomicXor
其他不受本机支持的原子运算(例如 64 位浮点原子运算)可以使用 compare‐and‐swap (CAS) 指令模拟。
纹理改进
GPU 的专用硬件纹理单元对于需要取样或过滤图像数据的计算机程序来说是宝贵的资源。Kepler中的纹理吞吐量与 Fermi 相比有明显提高,每个SMX单元包含16纹理过滤单元,对比Fermi GF110 SM 提高了4倍。
此外,Kepler改变了管理纹理状态的方法。在Fermi时代,为让GPU引用纹理,必须在固定大小绑定表中分配“槽”才能启动 Grid。表中槽数量最终限制程序一次可以读取多少个独特的纹理。最终,在 Fermi 中限制程序仅可以同时访问128纹理。
Kepler中有无绑定纹理,不需要额外步骤:纹理状态已保存为内存中的对象,硬件按需获取这些状态对象,绑定表过时。这有效地消除了计算程序引用独特纹理数量的任何限制。相反,程序可以在任何时间映射纹理和通纹理处理周围。
Kepler的内存层次结构与Fermi类似。Kepler架构支持统一内存加载和存储的请求路径,每个SMX 多处理器有一个L1缓存。Kepler GK110 还使编译器指示为只读数据增设一个新的缓存,如下所述。
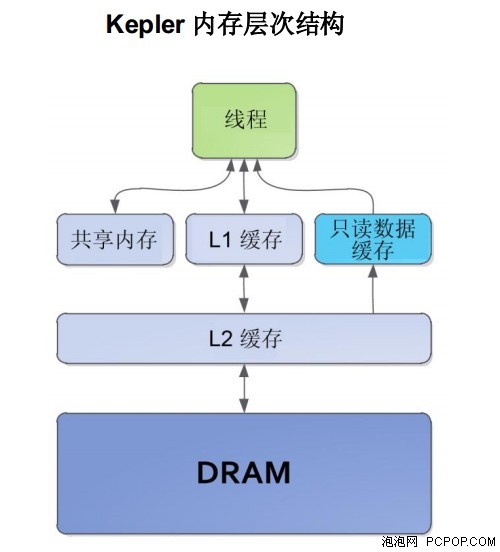
64KB可配置共享内存和L1缓存
在 Kepler GK110 架构(如在上一代 Fermi 架构)中,每个 SMX 有 64 KB 的片上存储器,可配置为 48 KB 的 共享存储器和 16 KB 的 L1 缓存,或配置为 16 KB 的共享存储器和 48 KB 的 L1 缓存。Kepler 目前在配置共享存储器的分配和 L1 缓存方面的灵活性更大,允许共享存储器和 L1 缓存之间以 32KB/32KB 划分。为了支持 SMX 单元增加的吞吐量,用于 64 位或更大负载运算的共享存储器带宽相对 Fermi SM 也增加一倍,到每主频 256B。
48KB只读‐数据缓存
除 L1 缓存之外,Kepler 为只读数据引入 48 KB 缓存为了函数的持续时间。在 Fermi 时代,该缓存只能由纹理单元访问。专家程序员通常发现它的优势是通过将数据映射为纹理来加载数据,但这种方法有很多局限性。
在 Kepler 中,除了大大提高了该缓存的容量之外,还伴随着纹理功力的提高,我们决定让缓存为一般负载运算直接访问 SM 。使用只读的路径好处极大,因为它使负载和工作组的影响远离共享/L1缓存路径。此外,其他情况下,只读数据缓存更高的标签带宽支持全速非对齐内存访问模式。
该路径的使用是由编译器自动管理(通过参数 C99 访问任何变量或称为常量的数据结构)。标准关键字 “const_restrict” 将被编译器标记以通过只读数据缓存加载。
改进的L2缓存
Kepler GK110 GPU 具有 1536KB 的专用 L2 缓存内存,是 Fermi 架构中 L2 的 2 倍。L2 缓存是SMX 单元之间主要数据统一点,处理所有加载、存储和纹理请求并提供跨 GPU 之间有效、高速的数据共享。Kepler 上的 L2 缓存提供的每时钟带宽是 Fermi 中的 2 倍。之前不知道数据地址的算法,如物理求解器、光线追踪以及稀疏矩阵乘法,从高速缓存层次结构中获益匪浅。需要多个SM读取相同数据过滤和卷积内核也从中受益。
内存保护支持
与 Fermi 相同,Kepler的注册文件、共享内存、L1 缓存、L2 缓存和 DRAM 内存受单错纠正双错检测 (SECDED) ECC 代码保护。此外,只读的数据缓存‐通过奇偶校验支持单错纠正,在奇偶校验错误的情况下,缓存单元自动使失效,迫使从 L2 读取正确的数据。
ECC 校验位从 DRAM 获取必定消耗一定量的带宽,这会导致启用 ECC和停用 ECC的运算之间的差异,尤其对于内存带宽敏感的应用程序。基于 Fermi 的经验,Kepler GK110 对 ECC 校验位获取处理进行了几项优化。结果,经内部的计算应用测试套件测量,开启和关闭 ECC 的性能三角洲已经平均降低 66%。
在混合 CPU‐GPU 系统中,由于 GPU 的性能/ 功率比提高,使应用程序中大量并行代码完全在GPU 高效运行,提高了可扩展性和性能。为了加快应用程序的额外并行部分的处理,GPU必须支持更加多样化的并行工作负载类型。
Dynamic Parallelism 是 Kepler GK110 引入的新功能,能够让 GPU 在无需 CPU 介入的情况下,通过专用加速硬件路径为自己创造新的工作,对结果同步,并控制这项工作的调度。
在内核启动时,如果问题的规模和参数已知,那么 Fermi 在处理大型并行数据结构时效果非常好。所有的工作是从主机 CPU 启动,会运行到完成,并返回结果返回到 CPU。结果将被用来作为最终的解决方案的一部分,或通过 CPU 进行分析,然后向 GPU 发送额外的处理请求以进行额外处理。
在 Kepler GK110中,任何一个内核都可以启动另一个内核,并创建处理额外的工作所需的必要流程、事件以及管理依赖,而无需主机 CPU 的介入。T 该架构能让开发人员更容易创建和优化递归和数据依赖的执行模式,并允许更多的程序直接运行在 GPU 上。可以为其他任务释放系统CPU,或可以用功能少的 CPU 配置系统以运行相同的工作负载。
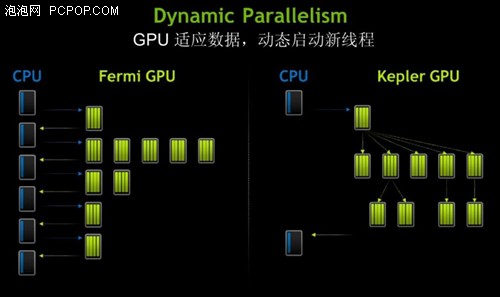
Dynamic Parallelism 允许应用程序中更多的并行代码直接由 GPU 本身启动(右侧图像),而不需要 CPU 的干预(左侧图像)。
Dynamic Parallelism 允许更多种并行算法在 GPU 上执行,包括不同数量的并行嵌套循环、串行控制任务线程的并行队或或卸载到 GPU 的简单的串行控制代码,以便促进应用程序的并行部分的数据局部化。
因为内核能够根据GPU 中间结果启动额外工作负载,程序员现在可以智能处理负载平衡的工作,以集中其大量资源在需要处理能力最大或与解决方案最有关的问题上。
一个例子是动态设置数值模拟的 Grid。 通常 Grid 主要集中在变化最大的地区,需要通过数据进行昂贵的前处理。另外,均匀粗 Grid 可以用来防止浪费的 GPU 资源,或均匀细 Grid 可以用来确保捕获所有功能,但这些选项的风险是在不太被注意的地区缺少模拟功能或“过度消费”的计算资源。
有了 Dynamic Parallelism,可以在运行时以数据依赖形式动态确定‐Grid解决方案。以粗 Grid开始,模拟“放大”注意的区域,同时避免在变化不大区域中不必要的计算。虽然这可以通过使用一系列的 CPU 启动的内核来完成,但是通过分析数据、作为单个模拟内核部分启动额外工作让 GPU 细化 Grid 本身要简单的多,消除了 CPU 的中断以及CPU和GPU之间的数据传输。
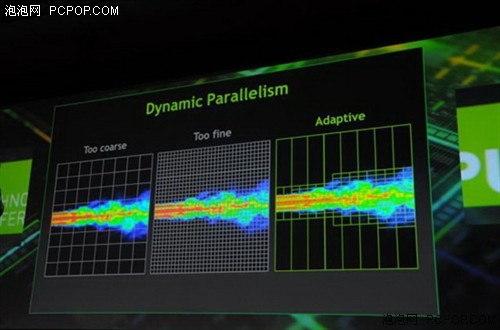
上面的例子说明了在数值模拟,采用动态调整 Grid 的好处。为了满足峰值的精度要求,固定的分辨率仿真必须运行在整个模拟域过于精细的分辨率上,而多分辨率 Grid 根据当地的变化为每个区域应用正确的模拟分辨率。
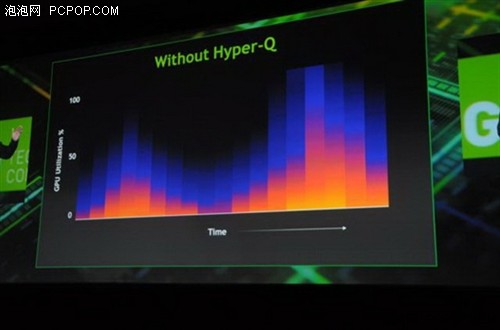
原来的一个困难是,GPU始终要优化调度来自多个数据流的工作负载。Fermi 结构支持从单独数据流的16路并发内核启动,但最终数据流都复用相同的硬件工作队列。这允许虚假的数据流内依赖,要求在单独数据流内的其他内核可以执行之前就完成一个数据流内依靠的内核。虽然在某种程度上这可以通过使用广度优先启动顺序缓解,但是随着程序的复杂性的增加,这可以成为越来越难以有效地管理。
Kepler GK110 使用新 Hyper‐Q 特征改进了这一功能。Hyper‐Q 允许 32 个并发,硬件管理的连接( 对比 Fermi 的单一连接),增加了主机和 GPU 中 CUDA Work Distributor (CWD)逻辑之间的连接总数(工作队列)。Hyper‐Q 是一种灵活的解决方案,允许来自多个 CUDA 流、多个消息传递接口(MPI)进程,甚至是进程内多个线程的单独连接。以前遇到跨任务虚假串行化任务的应用程序,限制了 GPU 的利用率,而现在无需改变任何现有代码,性能就能得到 32 倍的大幅度提升。
Hyper‐Q 允许CPU和GPU之间更多的并发连接
每个 CUDA 流在其自己硬件工作队列管理,优化流间的依赖关系,一个流中的运算将不再阻止其他流,使得流能够同时执行,无需特别定制的启动顺序,消除了可能的虚假依赖。Hyper‐Q 在基于 MPI 的并行计算机系统中使用会有明显的优势。通常在多核 CPU 系统上运行时创建传统基于 MPI‐的算法,分配给每个 MPI 进程的工作量会相应地调整。这可能会导致单个MPI 进程没有足够的工作完全占据 GPU。虽然一直以来多个 MPI 进程都可以共享 GPU,但是这些进程可能会成为虚假依赖的瓶颈。Hyper‐Q 避免了这些虚假的依赖,大大提高了 MPI 进程间共享 GPU 的效率。
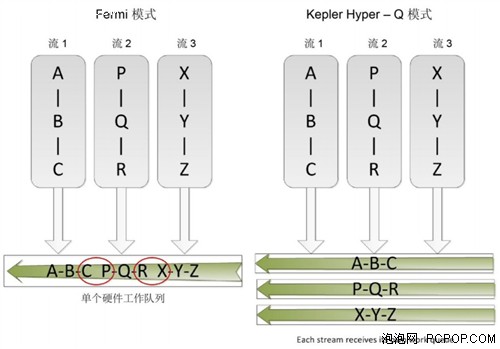
Hyper‐Q 与 CUDA 流一起工作:左侧显示 Fermi 模式,仅 (C,P) 和 (R,X) 可以同时运行,因为单个硬件工作队列导致的流内依赖。Kepler Hyper‐Q 模式允许所有流使用单独的工作队列同时运行。
Kepler GK110 中的新功能,如 CUDA 内核能够利用 Dynamic Parallelism 在 GPU 上直接启动工作,需要 Kepler 中 CPU‐to‐GPU 工作流提供比 Fermi 设计增强的功能。Fermi中,线程块的Grid可由CPU启动,并将一直运行到完成,通过 CUDA Work Distributor (CWD) 单元创建从主机到SM的简单单向工作流。Kepler GK110目的是通过GPU有效管理CPU和CUDA创建的工作负载来改进 CPU‐到‐GPU 的工作流。
我们讨论了 Kepler GK110 GPU 允许内核直接在GPU上启动工作的能力,重要的是要理解在Kepler GK110 架构所做的变化,促成了这些新功能。Kepler 中,Grid 可从 CPU 启动,就和Fermi 的情况一样,但是新 Grid 还可通过编程由 CUDA 在 Kepler SMX 单元中创建。要管理CUDA 创建的 Grid 和主机生成的 Grid,在 Kepler GK110 中引入新 Grid Management Unit (GMU)。该控制单元管理并优先化传送到 CWD 要发送到 SMX 单元执行的 Grid。
Kepler 中的 CWD 保留准备好调度的 Grid,并能调度 32 个活动的 Grid,这是 Fermi CWD 容量的两倍。Kepler CWD 通过双向链接进行通信,允许 GMU 暂停新 Grid 的调度并保留挂起和暂停的 Grid,直到需要。GMU 也有到 Kepler SMX 单元的直接连接,允许 Grid 通过 Dynamic Parallelism 在 GPU 上启动其他工作,以将新工作传回到 GMU 进行优先化和调度。如果暂停调度的额外工作量的内核,GMU 将保持其为不活动,知道以来工作完成。
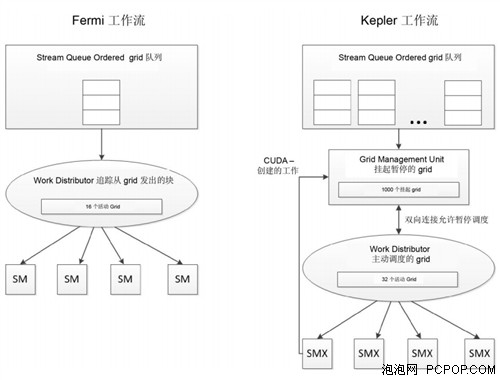
重新设计的 Kepler HOST 到 GPU 的工作流显示新 Grid Management Unit,允许其管理主动调度的 Grid、暂停调度、保留挂起和暂停的 Grid。
NVIDIA GPUDirect
当处理大量的数据时,提高数据吞吐量并降低延迟,对于提高计算性能是至关重要的。Kepler GK110 支持NVIDIA GPUDirect 中的 RDMA,目的是通过允许第三方设备,如 IB 适配器、NIC 和 SSD,直接访问 GPU 内存‐来提高性能。使用 CUDA 5.0 时,GPUDirect 提供以下重要功能:
无需 CPU方面的数据缓冲, NIC 和 GPU 之间的直接内存存取 (DMA)
显著改善 GPU和其他网络节点之间的 MPISend/ MPIRecv 效率。
消除了 CPU 带宽和延迟的瓶颈
与各种第三方网络、捕获和存储设备一起工作
如逆时偏移(用于石油和天然气勘探地震成像)这样的应用程序,将大量影像数据分布在多个GPU。数以百计的 GPU 必须合作,以紧缩的数据,经常通信中间结果 GPUDirect 利用 P2P 和RDMA 功能为服务器内或服务器之间“ GPU‐ 到‐GPU” 的通信的情况分配更高的总带宽。
Kepler GK110 还支持其他功能 GPUDirect,如 Peer‐to‐Peer 和 GPUDirect for Video。
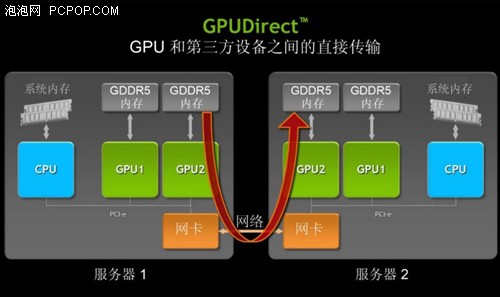
GPUDirect RDMA 允许网络适配器这样的第三方设备访问GPU内存,转换为跨节点GPU之间直接传输。
GTX TITAN的造型无论从美观还是效能上都堪称经典,这次GeForce GTX 780依然采用了和它一样的设计。改进型的涡轮离心式风扇不仅继承了前辈多卡SLI互相干扰小的优点,而且在噪音控制上也非常出色。

▲ GTX TITAN

▲ GTX 780
其实这也在情理之中,GTX 690别具匠心的设计深受好评,如果仅仅在一款双芯火星卡上昙花一现未免太过可惜。看来NVIDIA打算将旗舰卡都采用这种设计。

▲ GTX TITAN

▲ GTX 780
改良版的涡轮离心式风扇看起来非常美观,拆下外壳以后的风扇全貌可以看出,GTX 780和GTX TITAN一模一样。

▲ GTX TITAN

▲ GTX 780
散热器颇有份量,工艺也非常不错,至少拧了一二十个螺丝才将其拆下。均热板底座比普通纯铜底座散热效率更高,和TITAN也是一模一样。组装起来浑然一体,拆开以后却发现零件众多,和一般显卡相比,GTX 780的散热器构造比较复杂。

这是GTX 780的散热器的核心部件,底座鳍片一体式的镀铬散热模块。

▲ GTX TITAN

▲ GTX 780
PCB结构紧凑,用料扎实但并没有华硕的战神、微星的闪电那么张扬,可以看出GTX TITAN和GTX 780完全一样。

▲ GTX TITAN

▲ GTX 780
其实对于多数人来,GK110虽然从未正式亮相消费级市场,但并不陌生,NVIDIA之前为高性能服务器设计的优异产品Tesla K20X采用的就是这款芯片。
别看它其貌不扬,它可是集成了71亿晶体管的真正怪兽。GTX780和GTX TITAN核心标号有所不同,TITAN为GK110-400-A1,GTX 780则是GK110-300-A1。

▲ GTX TITAN

▲ GTX 780
除此之外TITAN的核心频率为837MHz,GTX 780为863MHz,两者都支持GPU BOOST,TITAN又比GTX 780多了两组SMX,所以两者的TDP均为250W,比Tesla高出15W。都是8加6Pin接口,5加1相供电。

▲ GTX TITAN

显存颗粒均为三星出品,编号同样是K4G20325F0-FC03,但GTX TITAN采用的是samsung 222,正反24个颗粒组成了384bit、6GB容量的显存规格,GTX 780采用的是samsung 310,正面12个颗粒组成了384bit、3GB容量的显存规格。规格不变但容量上少了一半,一般来说3GB显存足够应付一切游戏,但TITAN在4K以上分辨率应当更具优势。

▲ GTX TITAN

▲ GTX 780
和TITAN一样,GTX 780做工也是一丝不苟,该屏蔽的地方绝不含糊。笔者感觉比之前的公版做工都要更好一些,当然这些都是它应该具备的东西,GTX 780虽然比GTX TITAN售价便宜不少,但也要5000元以上。

▲ GTX TITAN

▲ GTX 780
可以看到GTX 780和GTX TITAN背面有明显区别,GTX 780PCB背面并没有显存颗粒。

▲ GTX TITAN

▲ GTX 780
考虑到它的定位,GTX 780和TITAN的长度并不算夸张,空间设计合理的中等大小机箱即可容纳。

▲ GTX TITAN

▲ GTX 780
接口方面,GTX 780和GTX TITAN也是一样,NV高端显卡经典的接口组合:DP HDMI 双DVI的阵型无论是对付多个显示设备还是多种显示设备均毫无压力。
此次测试的显卡主要定位高端旗舰,测试时所有游戏中开启全部特效,包括4X抗锯齿(AA)和16X各向异性过滤(AF)。虽然很多游戏提供了更高精度的AA,但由于实用价值不高,且没有可对比性,所以不做测试。
目前也有部分显示器是(1920x1200),游戏在这种分辨率下的性能表现与1920x1080差不多,FPS稍低一点点,使用这种显示器的朋友依然可以参考我们的测试成绩。
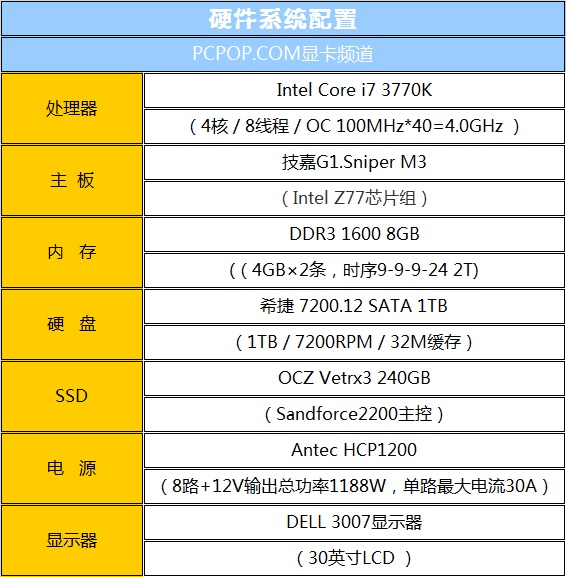
● 测试平台主板:技嘉G1.Sniper M3

技嘉 G1.Sniper M3是一款采用m-ATX板型设计的高端Z77主板,它结合了屡获殊荣的G1.Killer设计理念,目标是给玩家提供强大的性能。无论是内建Creative专业级音效处理器、Sound Core3D高质感音效输出还是支持 cFosSpeed 与网络加速技术的芯片,都是为了让玩家能有最棒的娱乐和联网游戏体验。
● 测试平台电源:Antec HCP1200

安钛克Antec HCP1200电源在世界超频大赛中非常常见,通过了80PLUS认证,转换效率高达92.4%,支持4路12V输出,最高电流72A,支持四卡SLI/交火。平均无故障运行时间为10万小时。配备一颗8cm静音风扇,运行噪音极低。
● 测试平台SSD:OCZ Vetrx3 240GB

OCZ的Vertex系列属于它的高端固态硬盘,专门为高端玩家和存储发烧友设计。随着Sandforce控制器大红大紫,OCZ也将Vertex系列升级到了全新的SF1200方案。如今SATA3.0 6Gbps接口大行其道,OCZ推出了基于SF2200系列主控芯片的Vertex 3固态硬盘,涵盖60-480GB容量范围。
既然针对平台不同,测试项目自然也相去甚远。三大平台除了PC追求极致性能外,笔记本和平板都受限于电池和移动因素,性能不是很高,因此之前的3Dmark11虽然有三档可选,依然不能准确衡量移动设备的真实性能。
3DMARK主界面
而这次Futuremark为移动平台量身定做了专有测试方案,新一代3DMark三个场景的画面精细程度以及对配置的要求可谓天差地别。

Fire Strike、Cloud Gate、Ice Storm三大场景,他们分别对应当前最热门的三大类型的电脑——台式电脑、笔记本电脑和平板电脑。
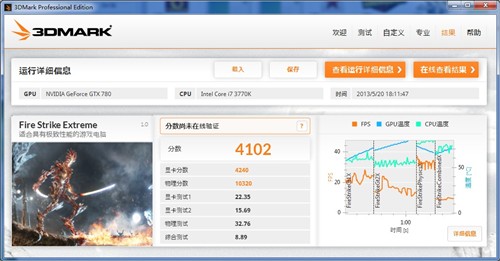
▲ GTX 780 3Dmark Extreme模式得分
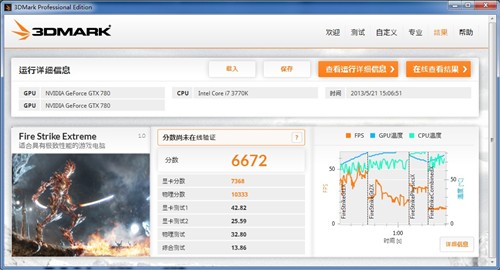
▲ GTX 780 SLI 3Dmark Extreme模式得分
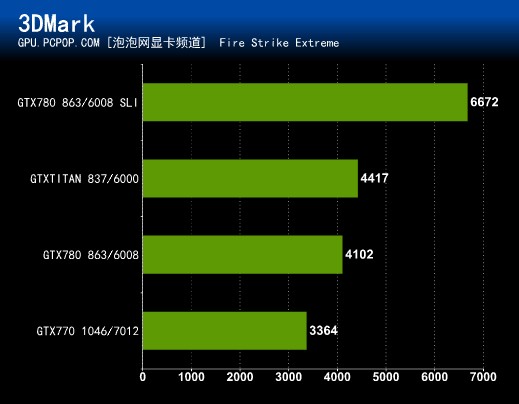
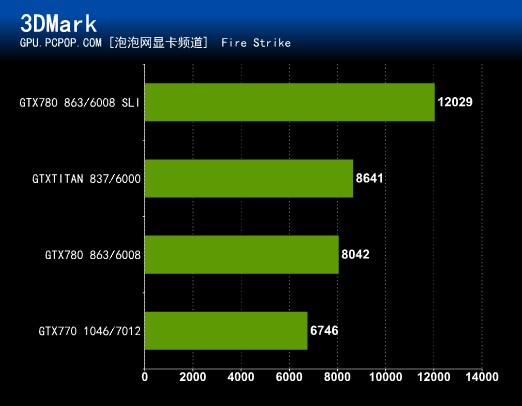
最新的3DMARK软件,最严苛的Fire Strike Extreme模式中,GTX 780 SLI以6672的成绩遥遥领先于其它显卡,新3DMark SLI效率不错。
<


3DMark11的测试重点是实时利用DX11 API更新和渲染复杂的游戏世界,通过六个不同测试环节得到一个综合评分,藉此评判一套PC系统的基准性能水平。
● 3DMark 11的特色与亮点:
1、原生支持DirectX 11:基于原生DX11引擎,全面使用DX11 API的所有新特性,包括曲面细分、计算着色器、多线程。
2、原生支持64bit,保留32bit:原生64位编译程序,独立的32位、64位可执行文件,并支持兼容模式。
3、新测试场景:总计六个测试场景,包括四个图形测试(其实是两个场景)、一个物理测试、一个综合测试,全面衡量GPU、CPU性能。
4、抛弃PhysX,使用Bullet物理引擎:抛弃封闭的NVIDIA PhysX而改用开源的Bullet专业物理库,支持碰撞检测、刚体、软体,根据ZLib授权协议而免费使用。
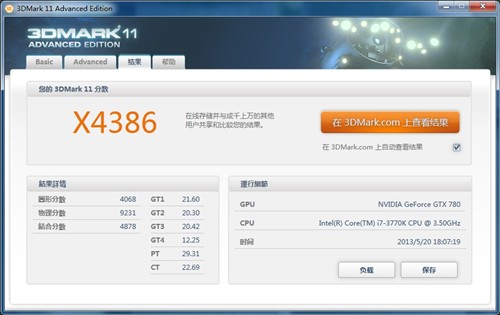
▲ GTX 780 3Dmark 11 Extreme模式得分
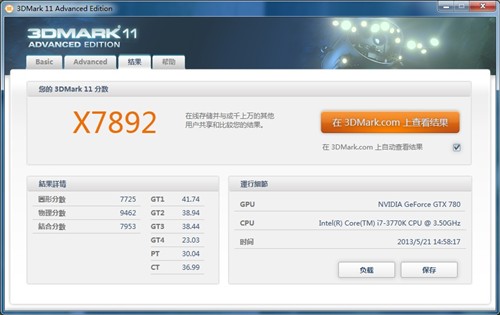
▲ GTX 780 SLI 3Dmark Extreme模式得分
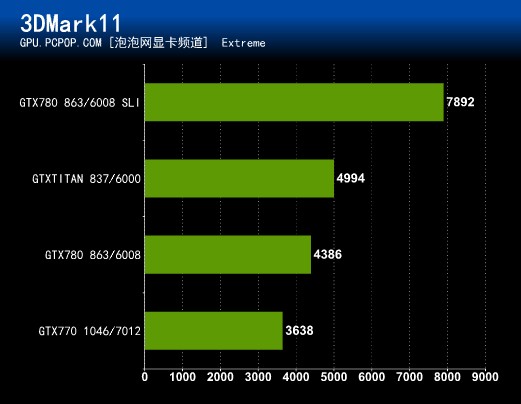
3Dmark11大量特效堆砌出来的以假乱真的画面让GTX770也不能完全流畅运行它,GTX 780以上的显卡就稍微流畅一些。本次测试中所有显卡一视同仁开启Extreme模式,高端级和旗舰级性能差距依旧非常明显。
对于现代显卡测试而言,除了3DMark之外必不可少的项目就是来自俄罗斯的Unigine Heaven(天堂),尤以其高负载、高压榨而知名。现在,新一代3DMark发布之后,Unigine也奉上了全新的显卡测试程序“Valley”(山谷)。
Valley正是Heaven的开发团队一手打造的,可以在最大程度上榨干GPU显卡资源。这次场景来到了一个优美空灵的山谷,群山环绕,郁郁葱葱,白雪皑皑,旭日初升,而且拥有极致的细节,每一片花瓣、每一株小草都清晰可见。
主要技术特点包括:
— 场景面积达6400万平方米,超高细节
— 整个场景可以完全自由浏览,并支持鸟瞰、漫步模式
— 先进视觉技术:动态天空、体积云、阳光散射、景深、环境光遮蔽
— 所有植被、岩石均为实时渲染,而非贴图
— 用户可控的动态天气
— 支持立体3D、多屏幕
— 极限硬件稳定性测试
— 基准测试预设
— 监视每一帧画面对应的GPU温度和频率
— 多平台支持:Windows、Linux、Mac OS X
— 支持命令行自动执行
— CSV格式可定制报告

Unigine Valley分为基础版、高级版、专业版三个版本,其中基础版免费,支持测试预设、自定义设置、GPU监视、交互模式,不支持循环测试(也就是拷机模式)、命令行、CSV报告,对于普通用户和一般评测足够用了。
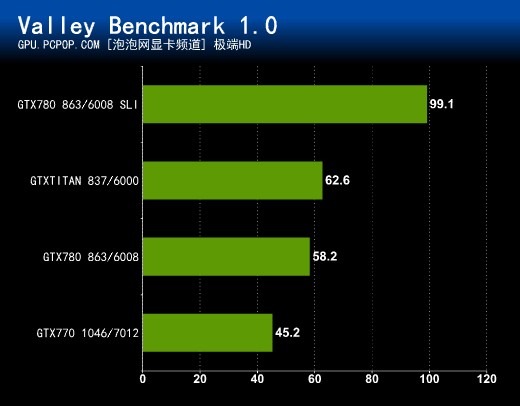
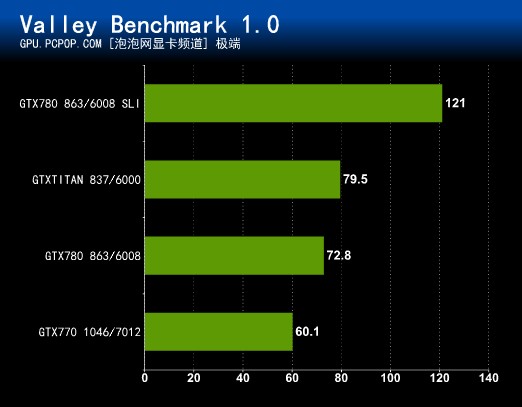
Unigine Valley的场景面积达6400万平方米,超高细节,对显卡渲染提出了很大的考验,在未来的游戏中,类似的情况将会越来越多。GTX 780可以在极端HD模式下达到58.2FPS,双卡SLI更是达到99.1FPS,性能远超GTX TITAN。
《孤岛危机3》支持大量的高端图形选项以及高分辨率材质。在游戏中,PC玩家将能看到一系列的选项,包括了游戏效果、物品细节、粒子系统、后置处理、着色器、阴影、水体、各向异性过滤、材质分辨率、动态模糊以及自然光。技术主管Marco Corbetta表示之所以《孤岛危机2》并不包含这么多的选项,是因为开发主机板的开发组实在是搞的太慢了。

● 实时体积烟云阴影(Real-Time Volumetric Cloud Shadows)
实时体积烟云阴影(Real-Time Volumetric Cloud Shadows)是把容积云,烟雾和粒子阴影效果结合起来的一种技术。和之前的类似技术相比,实时体积烟云阴影技术允许动态生成的烟雾拥有体积并且对光线造成影响,和其他物体的纹理渲染互动变化。
● 像素精度置换贴图(Pixel Accurate Displacement Mapping)
像素精度置换贴图(Pixel Accurate Displacement Mapping)可以让CryEngine 3引擎无需借助DX11的细分曲面技术即可一次渲染出大量没有明显棱角的多边形。此前crytek曾透露过正在考虑在主机上实现类似PC上需要DX11硬件才能实现的细分曲面效果,看来此言非虚,新型的位移贴图技术来模拟细分曲面的效果。虽然实现原理完全不同,但效果看起来毫不逊色。

极度精细逼真,完全嵌合的植被(Tessellated Vegetation)
● 实时区域光照(Real-Time Area Lights)
实时区域光照(Real-Time Area Lights)从单纯的模拟点光源照射及投影进化到区域光照的实现,以及可变半阴影(即投影随着距离的拉长出现模糊效果),更准确的模拟真实环境的光照特性。
● 布料植被综合模拟(Integrated Cloth & Vegetation Simulation)
布料植被综合模拟(Integrated Cloth & Vegetation Simulation)其实在孤岛危机1代中植被已经有了非常不错的物理效果,会因为人物经过而摆动,但是这次crytek更加强化了这方面的效果,还有就是加入了对布料材质的物理模拟,这方面之前只有nvidia的physx做得比较好。
● 动态体积水反射(Dynamic Water Volume Caustics)

动态体积水反射(Dynamic Water Volume Caustics)孤岛危机1和2基本上在水的表现上集中在海水,很少有湖泊和类似大面积积水潭的场景,而这次crytek实现了超远视野的水面动态反射。动态体积水反射可以说是孤岛危机2中的本地实时反射的一个延伸,是结合静态环境采样和动态效果的新的水面反射技术。

绝密细分的蟾蜍惊艳绝伦,完全可以以假乱真!
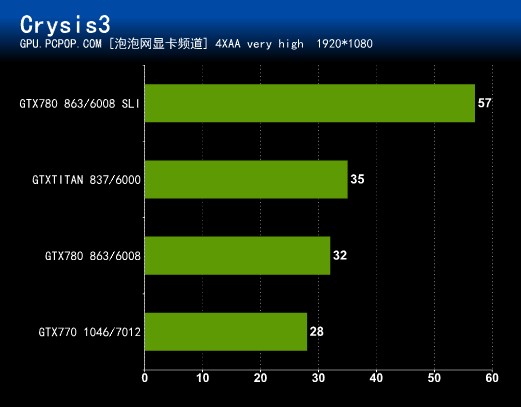
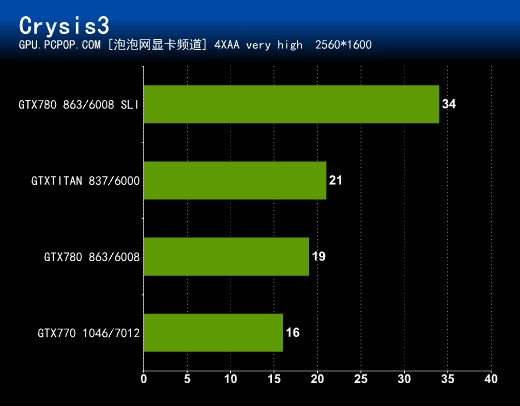
作为新一代DX11游戏的画质标杆,孤岛危机3相比上一代对显卡提出了更高的要求,而在这款代表着最尖端画质的游戏中,双核心的优化做的非常出色,我们可以看到GTX 780 SLI几乎达到了两倍的GTX 780的性能!
这些年我们看到了不少形态各异的劳拉,从丰乳肥臀的动作游戏主角到喜欢探索亚特兰蒂斯文明的睿智贵族。不过我们从未见过这样的劳拉。Crystal Dynamics的《古墓丽影9》让我们看到了一个参加初次探险的年轻劳拉,她遭遇海难被困在刀枪林立的小岛上,必须将自己的智谋和求生欲望提升到极限。

剧情介绍:故事从年少时期的劳拉开始,劳拉所乘坐的“坚忍号”仿佛是被宿命所呼唤,在日本海的魔鬼海遭遇到了台风,不幸搁浅。劳拉也被迫到岛上开始自己的求生经历。

古墓丽影9的游戏画面较之前代上升了不少,游戏要求也提高了不少。

这是我们开启不同画质的游戏截图对比,可以看出“高”特效的画质已经非常不错了。
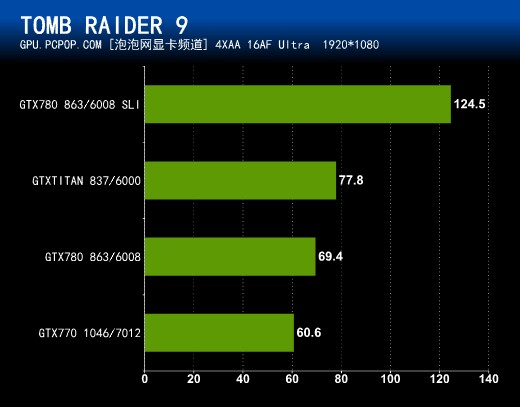
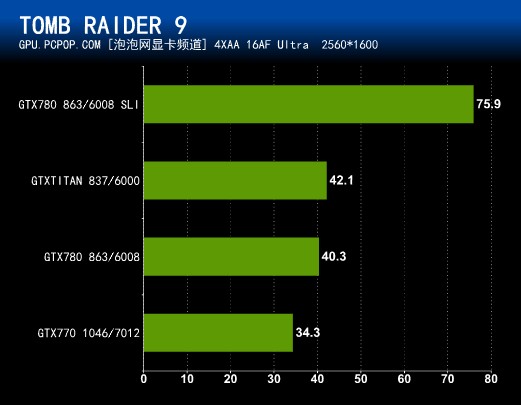
古墓丽影9对A卡的优化非常到位,当然最新的N卡驱动进行了优化以后,N卡游戏性能也得到大幅提升。在Benchmark测试中,即使是2560X1600分辨率+“最高”画质下,GTX 780依然可以流畅运行,和TITAN的性能差距很小,而双卡SLI则是遥遥领先。
由EA DICE工作室开发的《战地3》采用了最新的“寒霜2”引擎,完美支持DirectX 11,并且拥有强大的物理效果,最大的亮点还是光照系统,其渲染的场景已近乎乱真的地步,视觉效果堪称绝赞。游戏还支持即时昼夜系统,为玩家营造一个亲临现场的真实环境。

寒霜2引擎最大的特点便是支持大规模的破坏效果。由于考虑到游戏的画面表现以及开发成本,DICE放弃了以只支持DX9的WINDOWS XP操作系统。另外由于该引擎基于DX11研发,向下兼容DX10,因而游戏只能运行于WINDOWS VISTA以上的的操作系统。

在《战地3》中,“寒霜引擎2”内置的破坏系统已经被提升至3.0版本,对于本作中的一些高层建筑来说,新版的破坏系统将发挥出电影《2012》那般的灾难效果,突如其来的建筑倒塌将震撼每一位玩家的眼球。

《战地3》采用了ANT引擎制作人物的动作效果。在此之前,ANT引擎已在EA Sports旗下的《FIFA》等游戏中得到应用,不过在FPS游戏中使用尚属首次。相较于Havok等物理引擎,用ANT引擎可以花费较少的精力制作出逼真的效果。举例来说,战士在下蹲时会先低头俯身、放低枪口,而不是像以前的游戏那样头、身、枪如木偶般同时发生位移。此外,ANT引擎也可以让电脑AI的行动更加合理。但这款大作目前并不能良好的兼容120Hz3D以及红蓝3D模式。
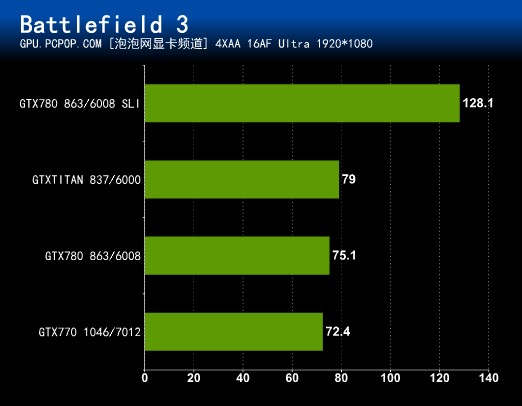
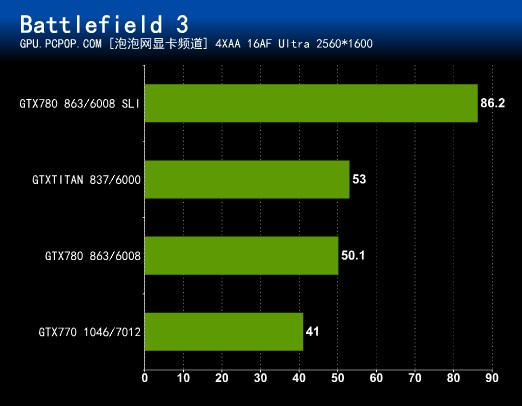
寒霜2引擎大作战地三,是为数不多的画面可以挑战Crysis的游戏大作,而对核心和显存的要求已经超越了Crysis!越是要求变态的游戏,旗舰级显卡就越喜欢,这款游戏中,GTX 780和TITAN的差距也是非常小!

游戏介绍:《地铁2033》(Metro 2033)是俄罗斯工作室4A Games开发的一款新作,也是DX11游戏的新成员。该游戏的核心引擎是号称自主全新研发的4A Engine,支持当今几乎所有画质技术,比如高分辨率纹理、GPU PhysX物理加速、硬件曲面细分、形态学抗锯齿(MLAA)、并行计算景深、屏幕环境光遮蔽(SSAO)、次表面散射、视差贴图、物体动态模糊等等。


开启景深,模拟镜头感
画面设置:《地铁2033》虽然支持PhysX,但对CPU软件加速支持的也很好,因此使用A卡玩游戏时并不会因PhysX效果而拖累性能。该游戏由于加入了太多的尖端技术导致要求非常BT,以至于我们都不敢开启抗锯齿进行测试,只是将游戏内置的效果调至最高。游戏自带Benchmark,这段画战斗场景并不是很宏大,但已经让高端显卡不堪重负了。
测试说明:如果说是CRYSIS发动了DX10时代的显卡危机,那地铁2033无疑是DX11时代的显卡杀手!地铁2033几乎支持当时可以采用的所有新技术,在画面雕琢上大肆铺张,全然不顾显卡们的感受,和CRYSIS如出一辙。然而CRYSIS靠着特效的堆积和不错的优化,其惊艳绝伦的画面和DX9C游戏拉开了距离,终究赚足了眼球;而地铁则没有这么好运了,画面固然不差,BUG却是很多,招来了大量的非议。
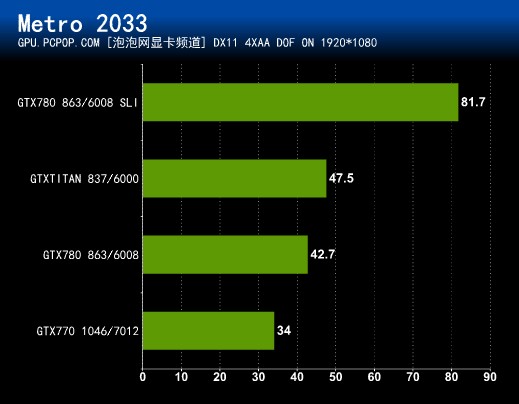
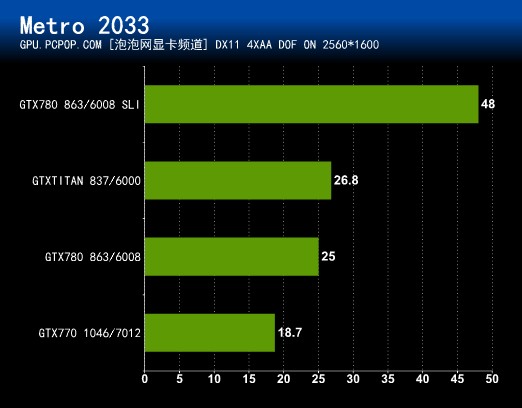
地铁2033,一款销量惨淡,游戏性一般但因为其对显卡硬件的变态要求而家喻户晓的游戏。这款游戏GTX 780和TITAN在极端模式下无法达到30FPS,只有GTX 780 SLI才能完美运行!

游戏引擎开发商BitSquid与游戏开发商Fatshark近日联合公布了一个展示DX11强大技术的DEMO。这个名为《StoneGiant》(石巨人)的DEMO,可以让玩家来测试自己PC显卡的DX11性能。BitSquid Tech即将提供PC平台的引擎,并且大概在今年第三季度将提供PS3和Xbox 360等其他平台的引擎。


画面设置:StoneGiant是一款技术演示Demo,画面做的非常精美,进入之后可以选择开启关闭Tessellation以及DOF(DX11级别景深)进行测试,这两项技术都十分消耗资源,尤其是同时打开时。其中Tessellation技术对画质的改善最为明显,测试时默认开启Tessellation、打开DOF进行测试。
测试方法:自带Benchmark。
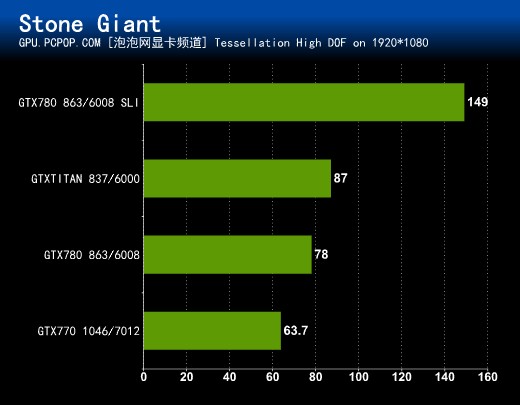
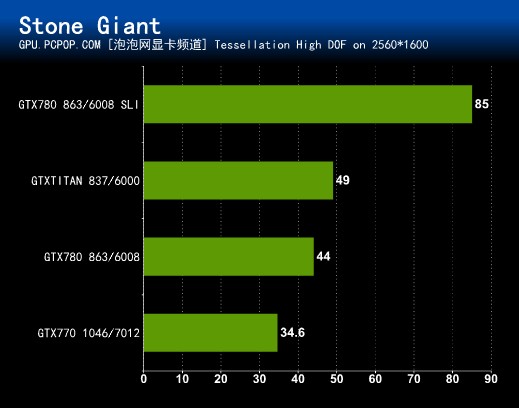
GTX780或者GTX TITAN对付这款比较老的BENCHMARK显然毫无压力,GTX 780 SLI成绩依然表现抢眼。
《Aliens vs. Predator》同时登陆PC、X360和PS3,其中PC版因为支持DX11里的细分曲面(Tessellation)、高清环境光遮蔽(HDAO)、计算着色器后期处理、真实阴影等技术而备受关注,是AMD大力推行的游戏之一,但是这样的主题难免让本作有很多不和谐的地方,暴力血腥场面必然不会少!发行商世嘉在2009年11月就曾明志,表示不会为了通过审查而放弃电子娱乐产品发行商的责任,因为游戏要维持“异形大战铁血战士”这一中心主题,无论画面、玩法还是故事线都不能偏离。

画面设置AVP原始版本并不支持AA,但升级至1.1版本之后,MSAA选项出现在了DX11增强特效当中,当然还支持Tessellation、HDAO、DirectCompute等招牌。该游戏要求不算太高,所以笔者直接将特效调至最高进行测试。
测试方法:游戏带Benchmark,其中测试画面颇代表意义,很好的体现了Tessellation异形身体以及HDAO等高级特效,希望这些特效能让系统发挥所有潜力。
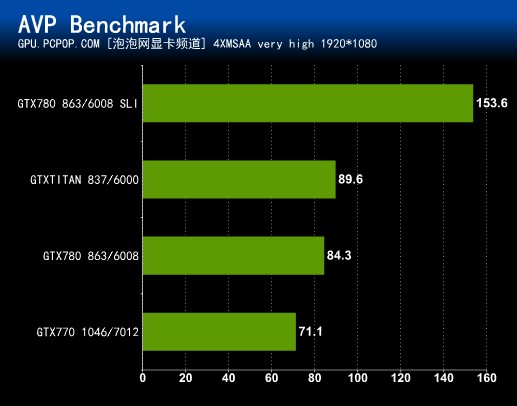
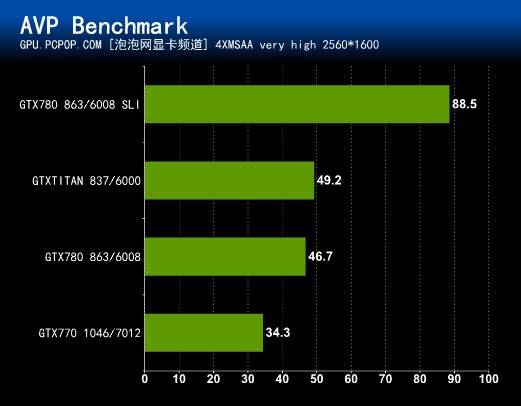
几乎所有游戏都无法和GTX 780双卡SLI相抗衡,这款当初要求变态的游戏,现在速度也达到了88.5FPS!
在互联网时代的今天,网络日益融入人们的生活,爱网、用网成为时尚,上网络玩游戏成为青年喜爱的娱乐方式之一。军事游戏在国外一些军队已发展多年、形成体系,并广泛应用于教育、训练。我军军事游戏目前尚处于起步阶段,基层部队日常娱乐多以小型益智类棋牌游戏为主,形式和功能都比较单一。

一些部队开展网上军事游戏对抗,使用的也大都是国外军事游戏的汉化版,游戏内容和体现的价值理念、军事思想,与我军有很大差异,长期使用不利于部队教育训练,甚至可能误导官兵。新研发的军事游戏《光荣使命》拥有完全自主知识产权,填补了我军军事游戏的空白。
在总部有关部门指导下,南京军区抽调骨干力量展开研发工作。历时半年,研究分析了34款主流军事游戏,先后派出6个专题小组,召开30多场座谈会,调研摸清官兵的兴趣爱好和现实需求,并在部队政工网开设“游戏开发论坛”,发动官兵建言献策。他们经考察了20多家游戏企业,最终选定与无锡巨人网络公司进行合作研发。
正式研发阶段,南京军区专门组成军事指导组,指导游戏设置,配合动作捕捉;聘请国内知名游戏公司技术人员担任顾问,参与项目评审,帮助解决技术难题。经过两年半的摸索实践,2011年4月初完成了测试版本,进一步测试、修改后,6月20日完成了正式版本,被行业专家称为“军事游戏的一个突破,游戏产业的一个创举”。
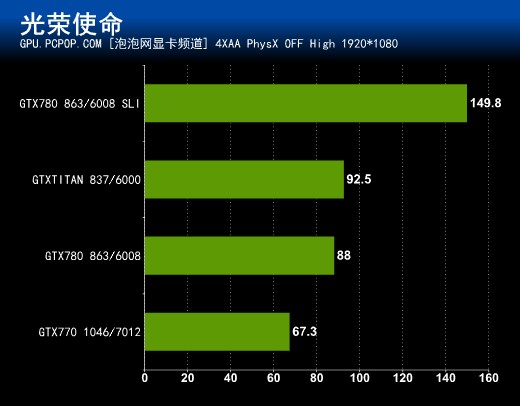
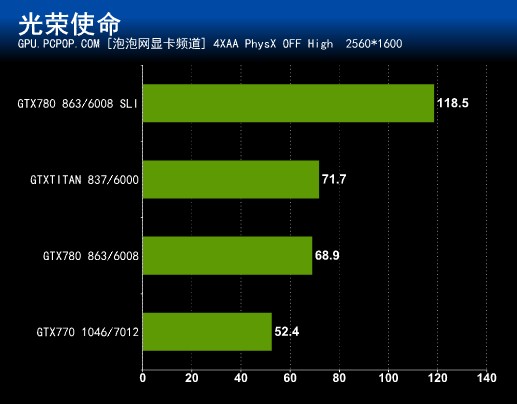
光荣使命不仅是第一款支持DX11的国产游戏,同时也是支持PhysX物理加速的游戏。在这款游戏的Benchmark测试中,GK110和加强版GK104核心还是有不小的优势。
《狙击精英》是2005年Reblion推出的一款以二战为背景的狙击游戏作品,一经推出后就获得英国独立游戏开发者协会的“非常好的PC/主机游戏”大奖,《狙击精英V2》则是这款作品的续作,据游戏开发商称续作继续秉承了游戏潜入类狙击的风格,较初代来说更加注重枪击后的真实感,“我们保证,新游戏将是最真实的二战狙击类游戏。不仅仅在武器弹道上,还有在开枪之前那种紧张的气氛,都会很真实的表现
出来。”Rebellion的首席执行官杰森·科林斯雷(Jason Kingsley)如是说。
游戏的画面在整体上相当的不错,无论是从整体的质感,还是画面的流畅性看都达到了很高的水准,在光源的处理上也非常的到位。同时,游戏依旧延续了初代精益求精的场景设计的理念,比如城市巷战地图中的断壁残垣以及黑烟冲天、山洞地图中充满着神秘气息的导弹基地等都给笔者留下了深刻的印像。

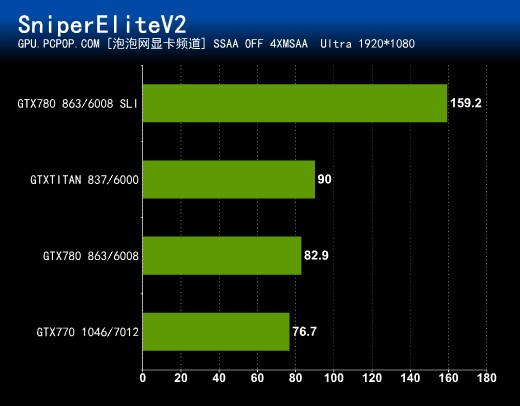
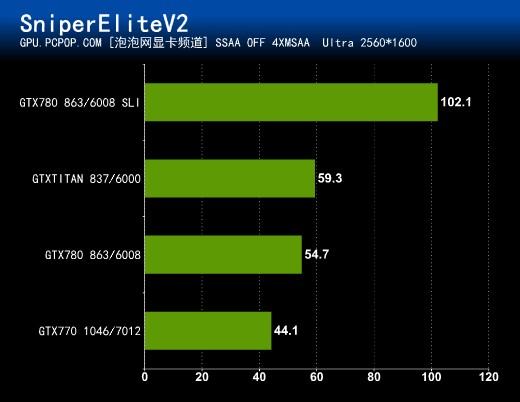
这款游戏支持超级采样AA,特效全开以后对显卡的要求达到了惊人的地步,甚至超越了素有显卡杀手之称的地铁2033,所以我们本次测试并没有开启超级采样,仅仅开启了4XMSAA,这样画面流畅多了
。《失落的星球2》的游戏舞台是前作故事发生后十几年之后经过温暖化改变的EDN-3rd,这里将新增丛林等新场景,主人公也并非前作那样为一人,而是以“雪贼”们不同的视点展开故事。


画面设置:与前作相同,《失落的星球2》采用CAPCOM公司原创引擎MT Framework的最新版VER.2.0进行开发,游戏世界的表现将更加细致和美丽。而不仅仅是画面上的进化,本作将会在前作玩家要求基础上追加大量全新要素,新场景、新角色、新武器等自不必说,角色的动作也比前作更加丰富多彩。
测试方法:游戏自带Benchmark,开启全特效+4AA选择B场景的BOSS战,非常激烈过瘾。
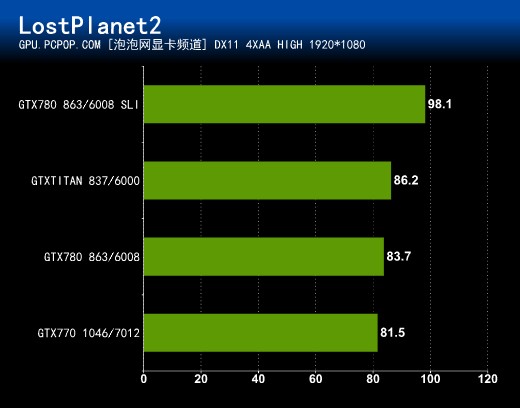
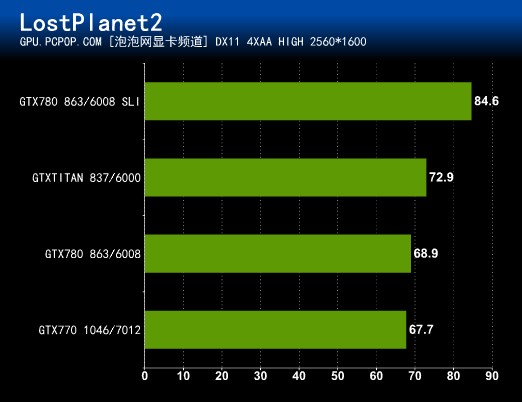
这款游戏非常老了,对显卡的要求也不算太高,所以参测的数款显卡成绩并没有完全拉开,GTX 780 SLI也不能发挥全部的实力。
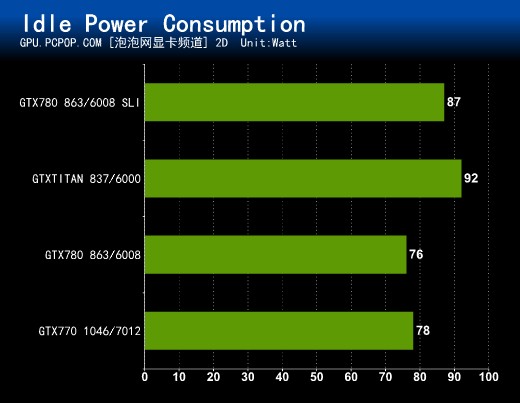
我们的功耗测试方法是直接统计整套平台的总功耗,既简单、又直观。测试仪器为微型电力监测仪,它通过实时监控输入电源的电压和电流计算出当前的功率,这样得到的数值就是包括CPU、主板、内存、硬盘、显卡、电源以及线路损耗在内的主机总功率(不包括显示器)。

待机为windows7桌面下获得的最小值;满载是以1680X1050模式运行Furmark时的最大值,Furmark能够让显卡稳定的以100%满负载模式运行,测得的功耗值比一般的游戏要高一些。
● 显卡空闲整机功耗测试(显示器除外)
● 显卡满载整机功耗测试(显示器除外)
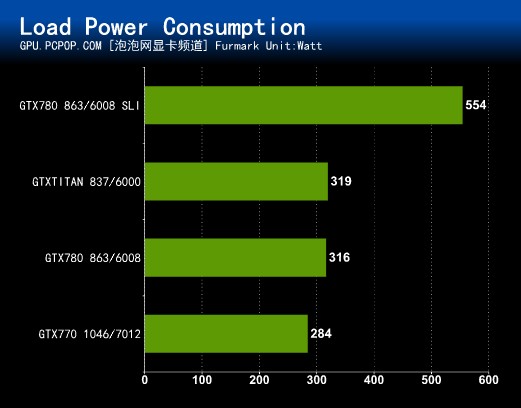
待机功耗TITAN的表现不尽如人意,而GTX 780整机(不包含显示器)只有76W,即使双卡SLI,也只有87W,所以在闲置状态,GTX 780 SLI比单卡GTX TITAN还要省电。满载工以后GTX 780 SLI功耗达到了554W,比TITAN高出将近一倍。所以想要组建双卡SLI平台的朋友一定要配备足额电源,笔者建议至少700W以上!
Kepler架构终极形态GK110又一次提高了游戏行业的标准,在单台计算机上进行设计和渲染,GK110核心的工作站可以实时编辑更多图层与特效,查看更大的地震数据集并与之互动同时不会因数据堵塞而令系统失去响应,以GPU为核心的计算模式再次被发扬光大。

Kepler GK110架构有很多创新,如SMX、Dynamic Parallelism 和 Hyper‐Q等等,这些功能不仅使混合计算大大简化,同时也简化了编程接口,有望催生出更优秀的软件,适用于更广泛的应用。
多显卡并行机制的历史最早可以追溯到1998年,当时Voodoo 2所具有的“SLI交错互连技术”可以让两块Voodoo 2显卡连接起来并行运作,获得近乎翻倍的3D效能。如此一来,其他竞争者就望尘莫及。而经过多年的发展演化,NVIDIA的SLI技术已经趋于成熟,从测试结果来看,最新的主流3D游戏均可以完美支持SLI,游戏性能可以提升80%甚至更多。
● GTX 780 SLI对比 GTX TITAN 的优势:
1. 外观做工设计GTX 780是GTX TITAN的孪生兄弟;
2. 双卡SLI游戏性能大幅超越GTX TITAN,性价比高;
3. 市场铺货充足,有多个品牌公版、非公版可供选择。
● GTX 780 SLI对比 GTX TITAN 的劣势:
1. TDP功耗高很多;
2. 两块成本比GTX TITAN高一些。
3. 对主板、电源有一定 要求,对机箱散热风道也比较挑剔。
事实上从测试结果可以看出,一代单芯卡皇在竞争对手面前毫无惧色,却完败给了它衍生出的次高端双卡GTX 780 SLI,这究竟是戏剧的演化还是宿命的终结?而且我们应该知道,GTX780所使用的PCB和GTX TITAN几乎一样,通过刷BIOS开核的成功率也非常高,如果它开启全部2688个流处理器的话,那么本来强势的性能将会再上一层楼!
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}