

盖棺定论 2013年手机处理器终极指南
泡泡网CPU频道8月13日 你一定很厌烦Android平台上无穷无尽的硬件大战,但我们很遗憾的告诉你:在谷歌对Android发展方向做出战略性调整之前,硬件规格是评价Android设备好坏的重要标准,对于部分用户而言甚至是唯一标准。历代热销的Android手机型号,无一不具备同时代手机中领先的硬件规格;即便是iPhone和iPad,为了实现一流的体验,也配备了地球上最庞大的嵌入式GPU。可以这么说:一台硬件规格强悍的手机不一定是好的Android手机,但一台好的Android手机,必然是一台硬件规格强悍的手机。

科技的发展总是日新月异的,只不过短短一年半,手机就已经到了坐四望八的时代。面对网上众多一知半解和“专家们”的误读,我们特意准备了两篇文章,上一篇对已经问世的四核平台作回顾和分析,下一篇再来展望今年和明年将要到来的新平台。与此同时,我们也会对这个行业的现状、将要遇到的难题以及未来发展的趋势做一些分析和预测,希望能帮大家拨开谜雾,真正了移动处理器的昨天、今天和明天。
群雄并起 四核平台微架构初探
由于种种原因,德州仪器选择了在双核转四核的时代退出了移动领域SoC的竞争。对于一家如此老牌的企业而言,这实在是显得有些奇怪,个中原因可能也只有德州仪器自己才能告诉我们了。作为结果,曾经的四大天王变成了三足鼎立,整个2012年,市场上只能见到三星、高通和nVIDIA的“三国演义”了。当然,我们也不应该忽略MTK,毕竟后者在今年初也推出了定位入门级的低端四核Cortex A7并且取得了不俗的市场成绩。但是这篇文章毕竟是以旗舰平台为主,因此就不对MTK做过多介绍,关于MTK的架构设计我们将会在完成架构分析和性能验证后再开新篇。希望各位不要介意。
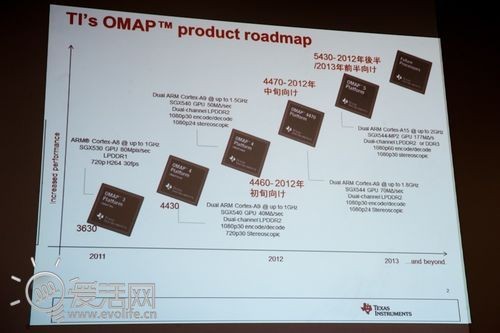
德州仪器曾经的路线图,OMAP5清晰可见
既是先锋也是先烈 NVIDIA Tegra3
截止去年为止,nVIDIA的行事风格一直都是“天下武功唯快不破”。甚至早在2011年底,Tegra3就已经走入了实际产品,而去年第一批搭配四核处理器的手机更是无一例外清一色Tegra3。相比Tegra2,前者的架构改动并不大,只是将CPU子系统从双核Cortex A9增加到了四核Cortex A9,集成的GPU也依是较老的GeForce ULP系列,顶点维持不变,像素和光栅化等组件得到了增强。只是作为一个四核CPU,内存维持了单通道LPDDR2的设计,显得比较莫名其妙。
现在看来,导致Tegra3成为一代最弱四核的一个主要原因,还是落后的工艺。但是这并不能过多责怪nVIDIA,毕竟后者和台积电打了多年交道,深知台积电的特色,因此主动放弃了28nm。事实上台积电一直到2012年下半年才总算可以勉强量产28nm芯片,证明了nVIDIA的远见。不过40nm的功耗却不是可以回避掉的问题,所以nVIDIA特别设计了4+1核心的奇特架构,这也成了nVIDIA产品的设计特色之一,一直延续到了今年的Tegra4和Tegra4i,与ARM的big.Little技术相映成辉。
众所周知,Tegra2因为缺少NEON协处理器,在双核时代被人吐槽的不轻,Tegra3总算没有再犯同样的错误。不过Tegra3却存在着一个由4+1架构带来的新问题,那就是由于主核和伴核共享同一片1MB的二级缓存,而两者的频率之间最多可以差到3倍,因此Tegra3的二级缓存被设计为按照一个固定的时间返回核心所请求的数据——对于主核而言,二级缓存的等待周期会多一些,而对于伴核而言则少一些。这样的设计不可避免的会让二级缓存工作在一个比较“慢”的状态(尤其是对主核心而言),进而影响整体性能。而实际上由于伴核的工作条件比较受限,并不是随时随地都可以切换,因此很多时候Tegra3也不得不以高功耗的主核心去应付低负载,也许会对功耗产生负面影响。这些影响,也最终决定了Tegra3的用户体验与评价。
谨小慎微步步为营 三星Exynos4 Quad
说起Exynos4 Quad,也许Exynos 4412这个名字更为人熟悉一些。它就是Galaxy S III与Galaxy Note 2的核心,2012年最为热门的四核SoC。若从角度来看,Exynos 4412显得相当朴素:基本上,你可以把它看作是“猎户座”处理器的工艺升级外加四核版。但是即便如此,这款产品的实际表现却几乎成为一代标杆,原因除去上一代猎户座在规格和性能上已经足够优秀以外,更重要的还是先进的工艺——这成为了Exynos4412的杀手锏,甚至在现在看来,Exynos 4412也有可能是迄今为止最为平衡的一款SoC。

当然这么说也不太准确,Exynos4 Quad也有一些比较小的改进,比如四颗核心的频率和电压具备完全独立的门控(听起来有些像高通异步架构的特性,不过实际中还是必须跑同频)、改进了内存控制器与CPU核心的连接方式、codec升级了视频编码的流畅度、引入了完善的温度控制和过热保护等等。都不是什么大提升,姑且算作锦上添花。
与高通相比,三星对于工艺的宣传要低调的多——这是很奇怪的情况,在高通的营销攻势下,很多人以为28nm“是非常先进的工艺”。在某种程度上说这也不算是错的,但实际情况是,Exynos 4412的制造工艺——32nm HKMG——要远比高通的28nm先进得多,甚至可以说有着“代”一级的差异。这也许会令人费解,我们留到后面再详细介绍。
也正是因为工艺的进步,Exynos 4412的核心频率被定在1.4/1.6GHz,GPU频率更是从猎户座的200MHz大幅提升到了440MHz,几乎翻倍。唯一可惜的是,具体的GPU依然还是Mali400 MP4,并没有更换。这在当时自然不是什么问题,但是到今天开来,这就成了Exynos 4412最大的短版。
架构为王 高通骁龙S4 Pro APQ8064
与NVIDIA不同,高通果断选择了28nm工艺,带来的结果就是APQ8064这款产品与预期的上市时间相比几乎延期了整整一年,而早期的低良品率也让高通不得不先推出双核产品作为过渡。当然高通也有自己的苦衷,APQ8064实在是太大了,即便使用了28nm工艺,核心面积也只能堪堪控制在100mm2上下。造成这个的原因是高通同时升级了CPU和GPU的核心架构。从Scorpion升级到了Krait“环蛇”,后者同样也是高通在ARM v7-A指令集上自行发展的核心设计,就像ARM官方以Cortex A命名的核心设计一样。在早期的宣传中,高通一直试图让消费者以为Krait是与Cortex A15同级的产品,当然随着时间的流逝,在实际表现的面前,这种说法的信奉者越来越少,以至于高通也不再提及了,不过至于究竟是怎样的情况,我们还是需要在后文中作进一步的分析,才可以给出一个大致的结论。

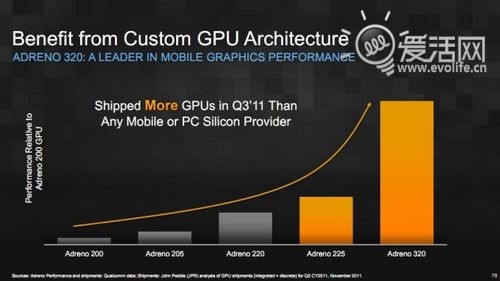
Adreno320 GPU则是另一个亮点。与前任Adreno 22x相比,Adreno320对于微架构做了较为大幅的优化,改善了内部缓存的连接方式,增加了片内EDRAM高速缓存(最终产品中是否出现似乎没有确认),最重要的是,Adreno320的规模再次得到了翻倍,拥有16组4+1D SIMD US。如果以规模论,这会是移动GPU领域除去SGX554MP4以外最为庞大、性能最强、也最为耗电的GPU,在Android领域更加是全无敌手。
简短的回顾到此为止,下面我们会对上一代旗舰的某些技术细节做更进一步的探讨。
不夸张地说,工艺是IT行业的基础。有趣的是,上一代产品中,高通、三星、NV三家公司分别选择了三种不同的工艺:Tegra3采用了台积电“40nm Fast G”,APQ8064采用了台积电“28nm LP”,Exynos 4 Quad则采用了三星自家的“32nm LP HKMG”。如果你已经头晕了,不要先忙着说虽不明但觉厉,这些工艺的代号的确会让人眼花缭乱,但它们是理解工艺细节的关键,所以我们必须要了解一下半导体工艺的相关基础知识。虽然这些都是2012年的产品,但是了解一些工艺细节也更利于我们分析今年甚至未来的新产品。

首先,所谓的45nm、28nm,这些数字都意味着线宽,简单理解就是内部晶体管的尺寸。这可能是半导体工艺中最直观也最具欺骗性的参数——大家都可能认为数字越小越先进,但实际情况远没有这么简单。
严格来说,线宽数字本身就具有一定的欺骗性。在半导体行业中存在两种类型的企业,一种是以Intel、三星为代表的拥有自主制造能力的企业,另一种则是以nVIDIA、高通为代表的Fabless,即设计代工型企业。对于后者而言,芯片的制造往往交给诸如台积电、中芯国际等半导体代工厂负责。正常而言,每一代逻辑芯片工艺的线宽基本上都是以70%的比例不断降低,就Intel为例,近几年我们熟悉的有 90nm、65nm、45nm、32nm和最新的22nm。

由于这些企业的卖的是产品而不是工艺,不论是技术还是工艺,主要都是为了自用,所以不会对这方面的宣传太过在意,但对于台积电而言,由于它的业务是代工,因此工艺细节就成了最主要的宣传对象。或许是为了让自己的技术看起来更“先进”一些,台积电自130nm节点开始,每一代工艺的线宽都要比Intel小一点——分别是110nm、80nm、65nm、40nm、28nm和20nm。这样的决策老实说,可能更多只是商业目的,技术上的差别并不会太大,甚至曾经出现过以台积电110nm工艺制造的芯片,在电子显微镜下观察,实际线宽浮动在120~130nm的情况。因此本质上来说,他们都属于同一代,单纯以线宽论,不论是28nm还是32nm,并不存在明显的孰优孰劣关系。
因此大家就知道了,Tegra3所采用的40nm工艺和45nm是属于同一代的,而Exynos 4 Quad和APQ8064采用的32和28nm则是最新一代的节点。Tegra3之所以选择上一代工艺,之前提到了是因为产能,但是产能到底影响有多大?
如果回顾以下台积电的路线图,那么按照原计划,28nm工艺原本计划在2011年9月量产——注意,是2011年。但实际上一直到2012年6月为止都无法达到传统意义上的大规模量产的水平,甚至一直到今天,依然无法完全令人满意,以至于高通已经将部分28nm订单转移给了联电和三星。而三星也同样遇到了这种问题,Exynos 4412的投产也比原计划晚了大约半年。10个月的拖延,在科技界不论是谁都是绝对无法承受的,所以纵使Tegra3再弱再慢再热,当市场上不存在其他选择的时候,它就是唯一的赢家。

TSMC的路线图:2013年将投产16nm,而实际上连CLN28HPL都看不到
未来随着新一代工艺节点研发难度的持续增大,可以预计“延期”会变得越来越普遍,而换代周期也会变得越来越长。前AMD半导体工厂,现代工厂GF的28nm就比预期的投产时间足足晚了一年多。目前来看,除了Intel以外,我们很难看到有谁可以保证在2013年内量产22/20nm工艺,而如果再进一步到下一代的16/14nm,不确定的因素就更大了。这就像是半导体行业的一枚定时炸弹,也许在不远的将来就会带来明显的影响。相信现在你已经明白“线宽”这个参数的区别,那么就让我们更进一步,去看看线宽以外的东西。
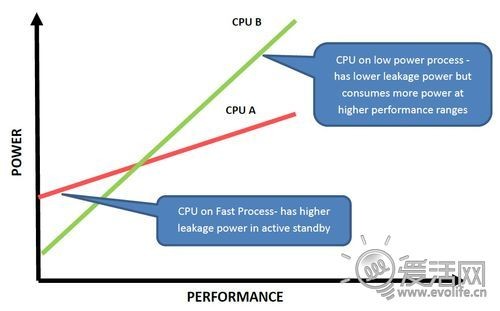
线宽以外还有东西?当然。拿Intel处理器来说,同一代工艺的产品(比如最新的22nm Ivy Bridge),桌面版的功耗为77W,而移动版就只有17W,当然频率是一方面,但更重要的原因则是所谓的“工艺方向”。大体来说,任何一代线宽下都会有三个工艺方向:高性能型、通用型、低功耗型,它们是在“功耗——性能”轴上取不同平衡的产物。同样的线宽,不同的工艺方向,差别甚至可以达到数倍之多,因此只谈论线宽是没有意义的。高通和三星的芯片均采用了低功耗型即LP工艺,唯独nVIDIA因为设计了LP工艺制造的伴核,从而使用通用型即Fast G 工艺制造剩下的部分以追求更低的满负荷功耗。
这么说来,那么高通就和三星一样省电——且慢,事情并不是这么简单。线宽和方向也远远不是工艺的全部,在这个领域还有很多的高级技术,它们发挥的影响力,甚至可以超越以上的一切。细心的你应该注意到了,在本回合开头的工艺介绍中,有诸如“HKMG”这样的缩写,这四个字母正是代表着一个高级技术:它指高介电常数金属栅极,英文为High-K Metal Gate,缩写为HKMG。这是一个非常先进但也非常复杂的技术,详细介绍可以写许多本书,我们作为消费者或技术爱好者,只需知道个大概:HKMG就是利用高介电常数的金属氧化物(例如氧化铪或者氧化铝)代替传统的二氧化硅作为栅极绝缘层,提高栅极对电子的容纳能力与对沟道的控制力,进而降低漏电,更重要的是降低高频率下的功耗。它的效果有多好?根据三星提供的数据, HKMG相对于SiON/Poly-Si工艺在同样的延迟(简单理解即频率)下漏电最多可以降低到十分之一,而同样的漏电下频率最多可以提升40%。Exynos 4 Quad也正是借助这样的先进工艺,在核心数翻倍的情况下,整体功耗依然降低了20%。
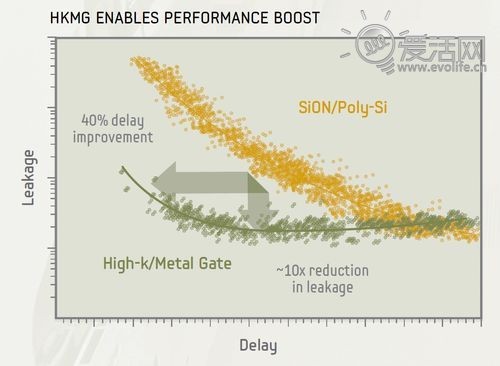
Exynos 4412当然使用了HKMG技术,但高通则令人失望。虽然台积电也拥有28nm HPL HKMG工艺,但高通选择的却是基于SiON/Poly-Si的28nm LP工艺。不仅APQ8064如此,甚至最新的骁龙600 APQ8064T,也还在采用28nm LP工艺制造。这一方面是因为HKMG会抬高制造成本,更重要的是台积电的28nm HPL HKMG工艺至今尚未量产,预计的时间将在2013年底到2014年初。这些因素综合起来,使得28nm LP成为了事实上的唯一选择——这自然会对APQ8064的功耗带来一定负面的影响,这个影响目前来看还是非常明显的。
早在2011年,围绕“Scorpion和Cortex A9到底谁更好”就已经展开过一些争论,随着时间的过去,事实慢慢证明了,Cortex A9的确技高一筹,而Scorpion则不幸成了“高频低能”的形象代言人。前文中我们曾提到,骁龙S4所采用的核心是自行研发的,高通表示这颗处理器的基础架构要远比Cortex A9先进,那么,它算不算ARM新一代架构Cortex A15呢?很显然这一定会引发另一场争论——至少在当时。为了分析这个问题,我们需要深入到架构内部。

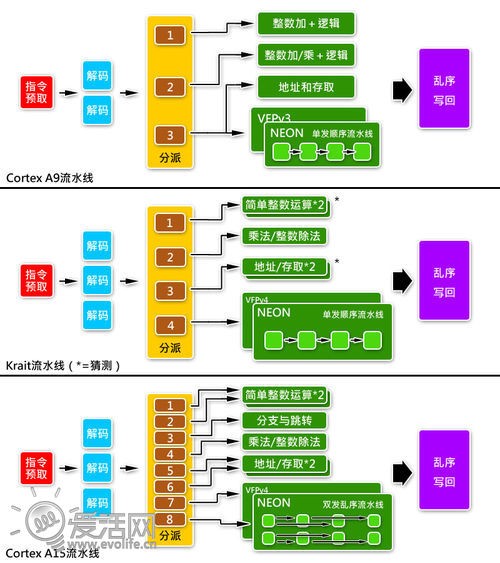
首先看一下规格:3指令发射、乱序执行流水线、3300DMIPS/MHz,的确和Cortex A15很接近。但是实际上Krait核心在大多数时候的表现却和Cortex A9相去不多,这究竟是为什么?答案自然是架构。虽然高通并没有公开Krait的详细架构,但是根据性能表现和一些特征性参数,我们也可以大概猜测一下。
在开始之前,首先需要来观察一下Cortex A9的架构:
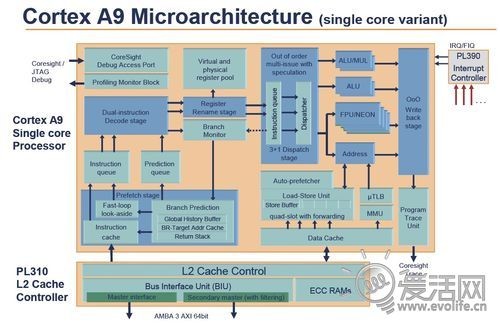
从逻辑角度说,处理器的工作过程是读取指令->解码指令->分派给执行机构->进行运算->把结果写回内存->读取下一条指令的循环。对应在架构图理,指令从左下角的预取(Prefetch Stage)级进入到上方的解码(Decode Stage)级,经过必要的处理(Register Rename)后,进入乱序指令分发(Dispatch)级,送给各个执行(ALU/NEON)器,最后进入乱序写回(Write back)部分。这一条路径,就是所谓的指令流水线,也就是下面这张图。
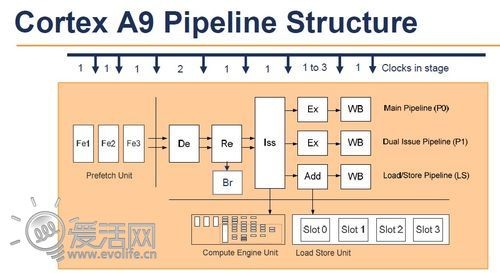
处理器的工作,就是不断读取内存中的应用指令流,然后把它尽可能快的塞进执行流水线。因此吞吐量是一个CPU架构很重要的指标,而吞吐量可以用IPC来衡量,即每周期指令数。Cortex A9的指令解码器(图中De)具备单周期解码两个指令的能力,因此是一个双发射的核心,具备的最大IPC为2。但是光解码没有用,还需要把解码后的指令送入执行流水线才可以真正实现功能,而这是靠乱序指令分派器(图中Iss)实现的。在Cortex A9里,这个部件具备3+1个端口,也就是说总共可以挂接四组执行器,但只能同时分派3个(有一个端口是复用的)。执行单元部有两个通用执行器(其中一个除去整数运算以外还支持并发执行一个硬件乘法运算)、一个访存器和命名为“Compute Engine”的运算协处理器,也就是我们知道的VFP和NEON。
到了Cortex A15,取指宽度提升到了128bit(Cortex A9只有64bit,后文详述),单周期解码能力增加到了3,也就是说拾取部分的IPC从2增加到了3。为了可以实际发挥它,ARM对Cortex A15的指令分派器与执行管线进行了极大的强化,这也是架构图中变化最大的部分。
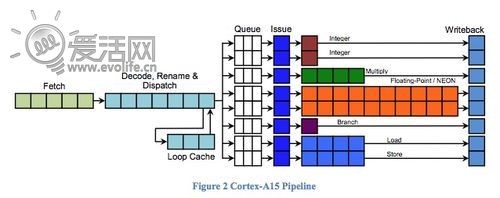
与Cortex A9的3+1分派不同,Cortex A15的分派器具备8指令分派能力,执行器也从3类4组扩充到了5类8组,额外增加了分支跳转单元和硬件乘除法单元,每一组执行器对应的分派端口都有自己的独立队列。Cortex A9上,VFP和NEON要屈尊共享一个分派端口,A15就成功平房换别墅,各自拥有了独立的端口,吞吐量大大提升。
那么结论是什么?至少从架构上,Cortex A15要远远比Cortex A9先进,两者的设计理念之间差了大约有5年。Cortex A9的架构更接近于老式的,上个世纪90年代的顺序架构处理器,即较少的分派队列、复用的执行管线与简单的多指令并发。当然, ARM在Cortex A9上第一次实现了乱序执行核心,但至少从架构图上看,结果可能也仅仅是支持而已。但Cortex A15不同,在Cortex A15上,才是真正看到了可以从乱序执行中获利的设计,原因很简单,乱序执行的本意是通过打破指令的时间顺序,进而增加处理器硬件资源的利用率。那么就自然需要CPU的分派单元具备足够强大的分派能力和硬件资源,可以尽一切可能去填满所有的执行器,因此体积必然会极大膨胀,最理想的情况就是给每一组执行器都设计一个端口和队列。
对于这一点,Cortex A15做到了,而Cortex A9没有做到。当然这么设计并不是没有代价。乱序执行需要的资源完全不是顺序架构可以比拟的,毕竟计算机程序的指令之间本身就具备逻辑上的先后顺序,再乱序,也只能是执行时的乱序,最终还是需要一定的顺序,这就需要具备额外的硬件资源去记录指令间的相关性以及时间状态。除此以外,为了保证后续指令可以跳过前面阻塞的指令执行,也需要指令队列有足够的容量去保存阻塞的指令。这之间有很多技术细节,会导致功耗的激增,如何在引入乱序执行核心优势的同时尽可能的去压制住激增的功耗,这需要非常高深的设计功力,甚至有时候需要一定的技巧和运气。Intel曾经也在探索新架构的时候跌了大跟头,ARM没有任何理由可以免费得到这种好处,因此Cortex A15也为此付出了代价。至于代价有多大,留到下篇再说。
Krait的资料就比较缺乏了,高通一向有保密的传统,所以目前只知道单周期解码能力为3、指令分派能力为4、执行单元一共有7个,仅此而已。但是这已经足够让我们去猜测Krait的设计,关键在于指令分派能力:4,也就是说,Krait的具体架构应当和Cortex A9类似,主要强化的是执行器规模。换句话说,Krait是一个大幅阉割了吞吐量的Cortex A15,或者说是一个大幅提升了“肥胖度”的Cortex A9。原因不用多说,只在省电二字。因此Krait空有接近Cortex A15的3300DMIPS/MHz理论运算能力与3 IPC,却并无法发挥,原因也在这里。单纯增加码头容量和工厂容量,却不提升连接码头和工厂的道路宽度,最终都是白费力气。
分派之后是执行,执行主要靠一组组的运算与逻辑单元构成。相比Cortex A9,A15增加了硬件乘法器和专门用来处理分支的Branch ALU,而且有迹象标明,Load/Store的性能也得到了很大的加强。这些对于某些情况下的应用性能会带来较大的改变,但更为明显的变化其实是在NEON与VFP上。Cortex A15中这两个SIMD ALU不仅拥有独立的端口,内部还实现了双发乱序执行流水线。
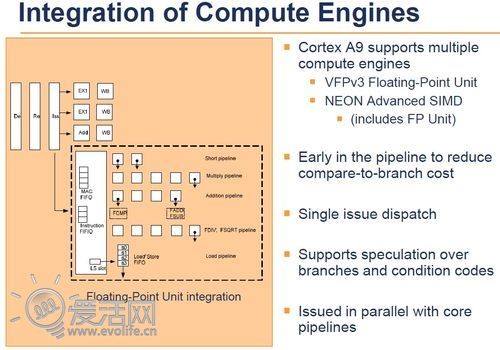
上图就是Cortex A9的浮点运算单元。它的内部实现了管线化架构设计,拥有自己独立的指令队列和指令分派,但是每个周期只能分派一个指令,执行管线也是单发顺序的。虽然图上没有画出来,但是VFP/NEON指令的具体解码在Cortex A9中是在浮点运算单元中实现的,因此相对于其他的执行管线而言,独立性显得比较明显。

到了Cortex A15,浮点运算单元被以其他运算器相同的运作方式整合到了处理器的主管线中,具体而言,就是VFP和NEON的指令解码和其它类型的指令一样是在前端指令解码部分直接实现,再由分派器统一分派。再加上内部的双发乱序,Cortex A15的VFP/Neon可以同时执行两条SIMD指令,四个融合MAC运算,运算能力要大大超越Cortex A9。根据现有的资料和实际的运行结果,高通也实现了双发的VFPv4,但是Neon与是否支持乱序则无从判断。可以猜测,Krait的SIMD部分性能可能会弱于Cortex A15。
作为总结,用一张图来简单比较一下Cortex A9、Krait和Cortex A15的执行管线:
再好的核心如果得不到数据,也只能停摆,所以缓存是现代处理器设计中一个很重要的部分。多处理器系统的缓存大体上有两种设计思路,一种是每个核心拥有自己独立的缓存,通过外部总线进行一致性维护,例如Pentium D和Atom;另一种是设计一块共享的大缓存,使用总线访问。Cortex A9和A15、Krait都采用了后一种设计,但是细节有所不同。
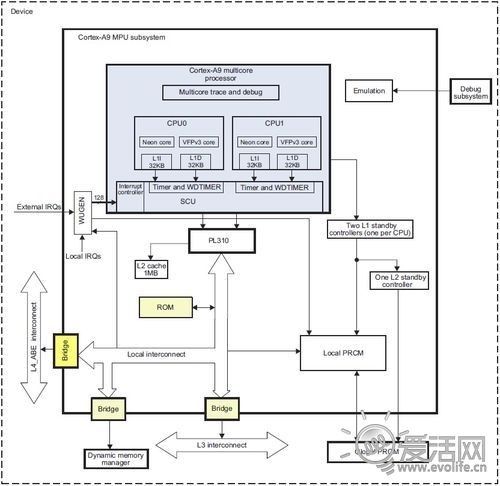
Cortex A9的二级缓存通过外部总线连接到处理器组。可以看到,两颗Cortex A9处理器通过标记为PL310的二级缓存控制器连接到1MB的缓存上。PL310的内部结构如下:
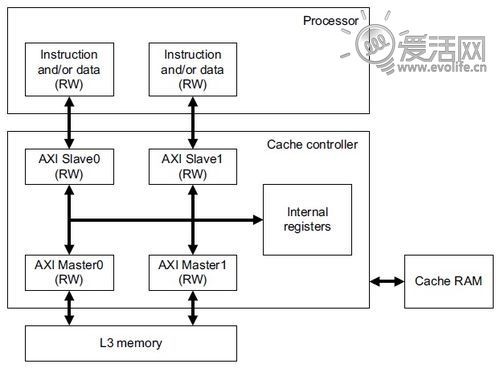
PL310提供了两个AMBA3 AXI接口,宽度都是64bit。结合之前的架构图,可以得到一个八九不离十的推测,那就是这两个接口一个会用作指令拾取,而另一个则用于访问二级缓存。
这个设计好不好呢?显然是不好的,否则ARM也不会把Cortex A15上的二级缓存控制器直接整合进A15多核心控制器SCU中。这是Cortex A15的一大升级,它的二级缓存不再是一个游离的组件,终于与所有的核心构成了一个紧密耦合的整体。它的好处,后面我们还会详细解释,而它的坏处,我们会在下篇中为大家分析。

不仅如此,Cortex A15的二级缓存针对多核心访问设计了4个独立的TAG队列,数据的读取和写入由两个不同的接口实现(这里不太确定),还支持直接的CPU到CPU数据传输,这一切都是为了提升多核心下并发访问缓存的性能。Intel曾经说过Cortex A9糟糕的二级缓存性能限制了它的性能,很明显,ARM决心在Cortex A15上改进这个缺陷。
至于高通S4平台,从高通自己提供的核心框图上看,似乎是采用了一整片L2缓存为所有核心所共享,但是nVIDIA在发布Tegra4的时候给出了一张幻灯片,里面对于Krait的L2缓存有非常清晰的说明:
很明显,Krait并没有设计为一体式L2缓存,依然保留着早期Scorpion的每颗核心包含自己独立缓存的架构。这是异步架构特有的问题和设计之一,缓存之间需要靠外部接口进行一致性维持,有效容量仅有总容量/核心,对于Krait而言,不论多少个核心,有效二级缓存永远只有512KB。当然,这样的设计拥有高带宽低延迟的好处,毕竟缓存是私有的,这点在对阵Cortex A9的时候会有一定的优势,但是面对Cortex A15就很难说有什么好处了。
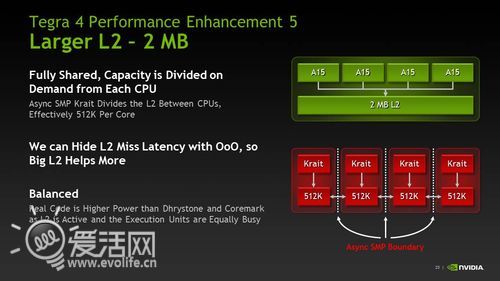
到这里大家应该就明白了,认为Krait是类似于Cortex A15架构的说法是不准确的。事实上,骁龙S4的“Krait”架构相对上代Scorpion而言虽然得到了很大的强化,但距离Cortex A15还有一定的距离,甚至说设计上与Cortex A9的亲缘关系更近,看作是“肥胖版”的Cortex A9也许会更合适一些。这样的架构注定很难发挥它的理论性能。
每次提到高通,“异步多核”甚至“胶水多核”都是一个无法回避的问题。对于这个技术,支持者和反对者都很多,之前的文章也有过一定的介绍。当然,实际上那时的介绍并不准确,不过异步架构在手机上坏处大于好处,这点相信还是很容易理解的。
异步架构的好处是什么?当然是省电。异步架构下的CPU不需要运行在同样的频率,甚至不需要拥有同样的实现,完全可以做到一刻核心运行在1.5GHz的全速下,而另一颗核心只运行在384MHz的最低频下。这样以来,高负载的线程,比如前台应用,就可以工作在高负荷的核心上,而诸如系统后台服务这样的低负载线程就可以工作在低频核心下,系统的能耗比得到最大规模的优化。

为了实现这点,高通必须对Linux核心的调度器做修改,因为典型的调度器并不支持非对称调度,它会默认所有的CPU核心具备同样的性能,这会导致低频核心进入严重的阻塞状态,进而影响系统表现。这也是高通称移动领域只有高通做到了这点的原因。
那么异步架构的坏处又是什么?自然是性能。异步架构对于性能的影响在于两个方面,一是异步电路的同步开销,二是非对称调度的调度开销。
不论多么复杂的硬件,深入到最底层,都是功能电路与总线的组合。总线需要协议,协议的基础是时序,因此显而易见的要求就是,连接到一个总线的两个设备之间想要沟通,那么就需要具备同样的时序。换句话说,就是需要拥有同样的频率。这就是同步电路。30年来,同步电路成为了设计领域的主流,围绕其发展的EDA技术也是最成熟的。而异步电路则不同,它拥有一个特殊的“握手协议”,在正式的传输发起之前,会首先利用几个时钟周期的时间进行“握手”,将双方的时序调整到一致。在实际实现中,这个由固化硬件实现的握手协议消耗的时序,根据设计不同在2~4个时钟周期左右,这就是异步电路的同步开销。如果我们考虑最极端的情况,假设真正的数据传输只需要3个时钟周期,那么异步电路的总线利用率就永远不会超过50%,因为至少有一半的时间要消耗在握手上,哪怕两边的频率是相等的。
看到这里,聪明的你应该可以发现问题所在:即便是异步电路,在真正数据传输的时候,依然还是需要两侧时序保持同步,异步握手协议的加入只是做到了通讯发起时双方的时序可以不一致。因此很明显的结论就是,异步总线同一时刻只能与一个设备进行握手。考虑以下状况,如果两个CPU同时向总线发起占用请求,即发起握手请求,而这两个CPU的频率不同,那么很明显,由于时序的不同,任何防止冲突的协议都无法起效,因为逻辑电路的最小工作周期就是时钟周期。因此异步系统里发起握手行为的只能是总线本身,也就是说异步系统里实际上是总线在不断询问CPU是否要接入,而不是CPU向总线要求接入。

既然如此,异步系统就是一个轮询的系统,这是它的另一硬件开销,尤其是在核心数超过2的系统中,由于轮询必然是有顺序的,那么就必然会遇到某一时刻总线轮询到的是CPU0,而此时需要握手的是CPU3。哪怕CPU1和CPU2都是空闲的,CPU3也必须要等到3个总线周期以后才可以和总线同步。假设同步需要3个周期,而数据传输也只需要3个周期,这就意味着在同步系统里只需要4个周期就可以实现的数据请求,在异步系统里消耗了9个周期。
当然,这里讨论的都是最基础的情况,实际设计中也会有很多的技巧去突破这些限制,但是别忘了,如果把总线协议和接口实现的过于复杂,其本身的耗电量也会增加,因此实际设计中可能并不会引入太多复杂的高级设计,因此这些开销可能全都是存在的。
除去硬件设计导致的开销以外,用于配合异步系统正常工作的操作系统调度器,也会引入额外的开销。对于同步系统的调度器而言,由于它假定所有的CPU均拥有同样的运算能力,因此调度算法的实现非常简单,只需要平衡的把负载分配到各个活动CPU上即可。但是一旦各个CPU之间的频率不同,调度器所需要维护的数据结构就会大大复杂化,因为系统需要尽力去保证异步系统处于异步状态,否则就无法实现异步系统省电的特性,因此就不能平均分配工作符合。尤其是考虑到实际的移动设备里,各个CPU核心的频率都是处在动态变化之中的,因此异步系统调度器的算法会明显复杂得多。我们知道,调度器所占用的是一个系统内两个时间片中间的时间,现代系统中时间片一般取10~100毫秒,Linux核心的时间片大体上是100ms左右,根据任务优先级不同而不同,最短可以到5ms。假设同步系统的调度器执行只需要10us,那么在5ms时间片的系统上所消耗的性能就只有0.2%,但是如果调度器消耗的时间为1ms,那么性能损失就会激增到17%左右,影响十分巨大。当然,在实际系统中不太可能使用5ms时间片,异步系统的调度器也不可能需要花1ms的时间才能完成调度,但是异步调度器的确会占用系统不可分片的时间,带来性能的下降。
至此异步系统的好处和坏处都解释清楚了,那么最后的问题就是,异步系统相对于同步系统而言究竟是好处多还是坏处多,这个问题可以分为两个方面来观察。
首先是用户对于性能的需求。异步系统的省电特性是靠牺牲性能获得的。由于同步开销的存在,异步系统发挥非常好的效率的时候是重度计算的情况,在这种情况下,CPU的指令流水线基本处于满负荷工作的状态,而指令拾取与解码往往会因为后端流水线的阻塞而停止。这时对于总线使用率的要求会大大降低,同步开销得以掩盖。但是当用户执行的是轻量级多线程时,由于同步开销的存在,系统的表现会大受影响,因此给人的感觉就是跑分快,实际用却表现不出来,多任务切换的时候甚至会有卡顿的情况,而这正是高通系统的特征。
其次是同步系统也各种有办法减小同步运行的高功耗,其中之一就是对指令流水线引入复杂而精密的时钟门控,在没有指令输入的时候,流水线甚至可以整体关闭时钟,进入彻底的停摆状态,进而降低功耗。这些都是已经成熟的技术,目前大部分CPU设计中都已经实现,因此同步系统和异步系统之间的差异可能并没有看起来的那么大。
总体来说,手机中使用异步系统是一种牺牲性能节省电量的折衷方法,并非是解决性能和功耗问题的唯一途径。很多时候高通MSM平台所宣称的节电效果是来自于CPU、Baseband、Modem等子系统的共同作用。异步就能省电是个巨大的认知错误。
在2012年的SoC中,内存子系统也存在着很大的区别,我们来回顾一下。

内存的影响这么大?当然。这个问题放在几年前可能的确不那么重要,但现在的智能手机分辨率越来越大、配置越来越好、性能越来越高,所有的内置设备,都要从内存中频繁存取数据。与PC不同,手机的GPU往往并不具备独立显存,因此显存也要占用内存总线,这无疑会进一步加大内存系统的压力。对于这个问题,解决方案就是增加内存带宽,甚至方式都如出一辙,那就是双通道。事实上自双核时代以来,几乎所有的SoC都把双通道作为设计标配。
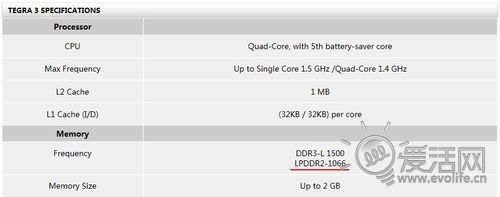
为什么说几乎?那自然是有例外,事实上一共有三个,第一个是Tegra2, 第二个是高通S3,第三个则是Tegra3。nVIDIA独中两元。
内存带宽是一切的基础,可以说在过去、现在和未来,带宽都是越大越好。Tegra3虽然只配备了单通道内存,但是种种迹象显示,Tegra3的内存控制器支持的工作频率非常高,官方提供的数据是LPDDR2 1066MHz,即便是以32bit的单通道,单向带宽也达到了4.2GB/s。但是Tegra3系统中内存实际运行的频率不得而知,但是从测试结果来看,应当不会比1066MHz低多少。
而根据官方提供的资料,高通的APQ8064虽然支持双通道LPDDR2内存,但它的内存频率仅仅运行在等效533MHz下。这样的内存系统,带宽和Tegra3是一样的,同为4.2GB/s。
双通道是用于提升带宽的但同时也会增加延迟,如果双通道系统的频率过低,就像APQ8064,那么这样的系统其实反而会影响性能。我们不可能保证需要读取的数据永远位于两个不同的控制器下,因此低频双通道整体上的延迟要比高频单通道高得多,即便考虑到时序,影响也可能会在20%的水平上。
至于Exynos 4 Quad,它的内存子系统是双通道LPDDR2 800MHz,因此拥有最大的带宽——6.4GB/s,平均延迟则和Tegra3接近。所以在这三款CPU之中,Exynos 4 Quad的内存性能是最好的。

不过随着性能的进一步提升,到最新这一代产品,也就是骁龙600/800、Exynos Octa、Tegra4,最终还是都配置了双通道内存控制器,而且全都升级到了LPDDR3。虽然速度还有区别,但至少不需要纠结双通道与否了,至于它们的具体性能,我们会在下篇中介绍。
放松一下。在微博上曾经流传着一个段子:高铁停电了,第一批人在寂寞中抬起了头,那些都是苹果用户。紧随其后,Android用户也抬起了头,忧郁地看着窗外,而此时,诺基亚的用户还在用手机放着月亮之上。这当然不是吐槽现阶段手机续航的唯一段子,还有一个段子说的是,每一个用Android手机的男人一定都是好男人,因为他们必须每晚准时回家——充电。不可否认的,强大的性能,带来的副作就是不强大的续航,这已经成了很多手机玩家心头挥之不去的痛。指望电池技术一朝突破不太现实,那么唯一的办法就是想办法尽量少用点电。第一回合里我们介绍了工艺,很显然,Exynos 4 Quad、Tegra3、APQ8064采用了三种不同的工艺,自然也会产生不同的功耗。大家都说自己很省电,因此我们只好用测试来决一高下了。
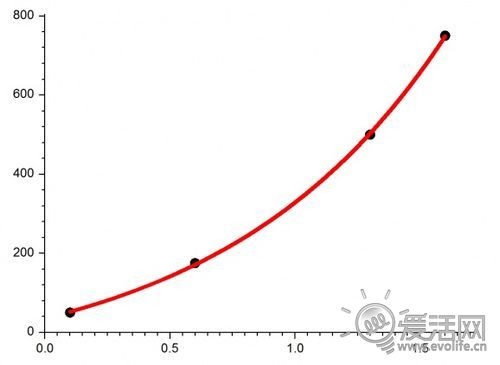
频率和功耗相关性曲线
这一节的功耗测试主要来源是互联网,因此对于数据本身是否足够精确、足够公平,各位可以不用太过于考究,权当定性研究吧。
首先是Tegra3,因为nVIDIA比较慷慨,在Tegra3的白皮书中给出了功耗对比。Tegra 3的整个CPU部分工作在1GHz频率下的功耗大约是1.26W,而Tegra3的实际产品运行频率是1.5GHz,这个频率下的功耗nVIDIA并没有提供,我们只能根据经验来预估。由于Fast G工艺的漏电比例较大,因此Tegra3在1.5GHz下的功耗可能是在2.5W~3W左右。考虑到Tegra3的几乎整颗芯片都用的是40nm Fast G工艺制造,因此也可以猜测在其它通用硬件上,Tegra3的功耗会相对大一些,再加上nVIDIA一贯有标低不标高的“优良传统”,因此这样的估计应该不会相差太远。
当然,Tegra3有一个LP工艺制造的伴核。但是这个伴核更多是用于在待机时避免Fast G工艺的高漏电而设计的,对于正常使用的贡献并不大。
GPU方面,由于完全没有任何可以参考的资料,所以究竟功耗多少,只能从实际使用续航中加以猜测。根据我们和广大用户的实际使用体验,Tegra3手机的游戏续航时间都不会太长,我们推测Tegra3的GPU功耗应当在1W左右,也就是说整颗Tegra3芯片在CPU和GPU满载的时候,功耗大约在3.5W左右(该数字并非官方提供,仅供参考,而且实际也很难做到同时满载,这样的数字只是为了一定程度上方便比较)。
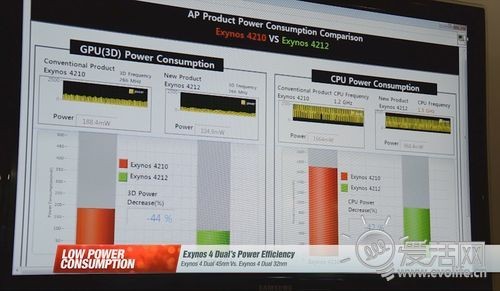
看完了Tegra3,再来看看Exynos 4 Quad。这颗芯片的详细功耗数据三星并没有提供,但我们知道同样工艺的双核版Exynos 4 Dual 32nm的信息,这来源于三星官网上的一段介绍视频。
在图上可以看出,1.5GHz的双核Exynos 4 Dual 32nm的CPU部分功耗大约是在1W左右,每颗核心大约500mW。而Exynos 4 Quad的工作频率为1.4GHz,因此估计的功耗大约会是430mW,也就是说四核心的总功耗在1.7W左右,相对于Tegra3而言至少低了30%。
猎户座的GPU部分功耗图中也有所体现,45nm工艺下,运行频率为266MHz的Mali400 MP4的功耗大约是105mW,由于Exynos 4 Quad的GPU运行频率大约是400MHz,因此经过估算功耗大约在160mW左右。至此,Exynos 4 Quad的CPU+GPU最大总功耗就可以计算出来了,大约是在1.9W左右。
最后是APQ8064。相对于前两者的频繁估计不同,由于高通提供了MSM8960(与APQ8064拥有同样的核心)的开发平台,因此各项功耗都可以轻松直接测量。虽然功耗随着频率和负载的波动变化很大,但当工作在1.5GHz时,Krait CPU功耗大约是在700~750mW,因此APQ8064如果四核满载,消耗的功率也将达到3W左左右,与Tegra3不相上下。
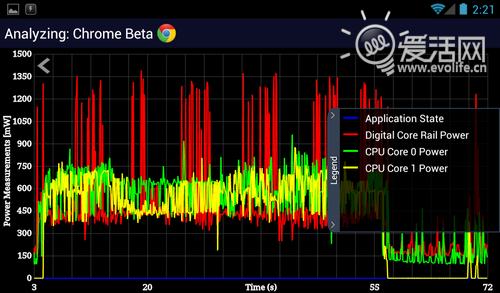
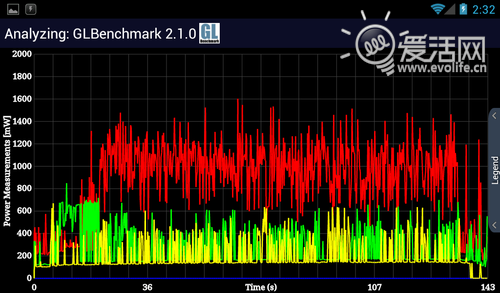
由于MSM8960的GPU是Adreno225,因此GPU功耗无法直接和APQ8064比较,这点比较可惜。但是即便如此,MSM8960的GPU功耗也已经高到难以置信,最高达到了1.6W,平均而言也有1.1W左右——几乎是Exynos 4 Quad的七倍。由于从规模上说,Adreno320和Adreno225相比有着翻倍的提升,而制造工艺完全相同,虽然考虑到微架构的提升可能可以带来一定的省电效果,我们还是很难相信Adreno320的功耗会低于2W。
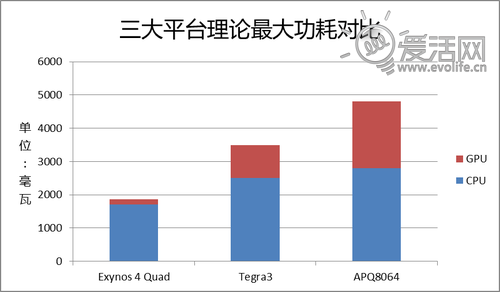
在第一回合的结尾,我们提到过,高通没有选择非常先进的28nm HPL HKMG工艺,可能会对产品的功耗表现产生一定的负面影响,在这里我们可能已经看到了结果,拥有HKMG技术加持的Exynos 4 Quad在三大旗舰平台的功耗里是最小的。 Tegra3由于伴核的存在,实际使用中的功耗比较难以估测,但如果是极限情况下则明显不容乐观。APQ8064的全满载功耗无疑是上一代四核平台里最高的,但是由于在实际产品中,各个制造商都会主动降低这款SoC的工作频率(尤其是GPU),因此实际功耗应当介于前两者之间。毫无疑问,最容易让手机变成好男人的是Tegra3。
对于普通读者而言,长篇大论的理论分析肯定是很乏味的(技术宅另当别论),看到这里,相信大家也都累了。虽然理论上里里外外、反反复复的比了个遍,但是毕竟实践是检验真理的唯一标准,作为2012年旗舰的这三颗处理器究竟孰优孰劣,还得经过实际测试才能知晓。因此,我们整理了Anandtech、GSMArena等数家国外权威媒体的测试成绩,尝试一下通过分析结果来验证一下理论分析的结论。当然,这些测试的环境是否一样无法考证,所以实际上这个对比并不严格。毕竟只是回顾而已。
需要注意的是,因为各种原因,有些测试程序的参考价值有限,如Neocore、Nenamark v1和Vellamo。对于这类测试,我们决定直接忽略。
首先我们来看一些理论性能测试,作为对比,我们在图表里加入了上上代产品,1.2GHz的Exynos 4210与1.5GHz的MSM8260。Linpack是出厂率比较高的测试之一,靠求解线性方程组来测试系统的浮点运算能力。
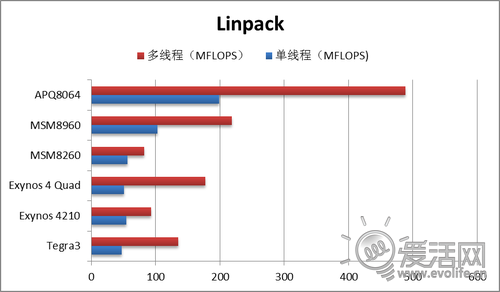
APQ8064取得了压倒性的领先,主要是源于VFPv4,而A9和Scorpion只有VFPv3。浮点运算性能在现阶段的实际应用中体现的较少,因此这项测试的实际意义可能更多是体现在未来。比较有趣的是,Exynos 4 Quad虽然频率更高,但单线程性能却不如Exynos 4210,这也许就是受到了前文提到的处理器子系统带宽问题的影响。
接下来是几乎逢评测必测试的兔子跑分。这是一个综合测试项目,我们先来看总分,再慢慢分析。
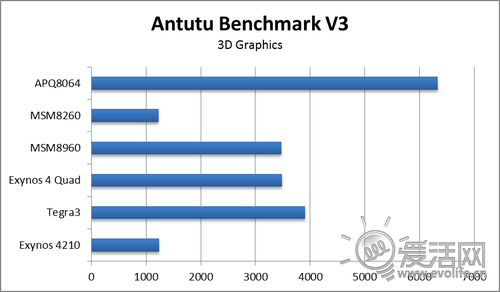
APQ8064是三大四核平台里分数最高的,其次是Exynos 4412,再次是Tegra3。双核和四核在这里体现出了差距,但是我们还需要来仔细看一下单项得分。

内存的结果比较有趣,虽然Exynos 4210和Exynos 4 Quad拥有同样内存配置,但得分只有后者的一半都不到,似乎Exynos 4 Quad内存到CPU的连接的确比较高效。但是若只看四核平台,又会发现对于高通平台而言,浮点和整数的性能落差要明显大于Cortex A9。这也许就是异步架构的开销,毕竟安兔兔的浮点并没有使用VFP加速。
整数部分的差距体现的是双核和四核的差距,虽然Krait拥有架构的优势,但这通过之前的架构分析我们可以找到原因,那就是因为不论是Krait、Cortex A9还是Cortex A15,整数运算器都只有两组,因此执行能力的确没有太大的区别。
CF-Bench也是一个理论性能测试软件。这里我们也来对比一下测试成绩。
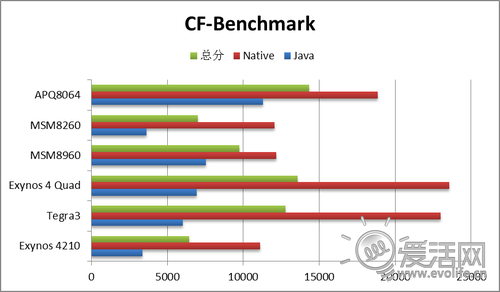
基于同样的理由,在以整数计算为主的Native性能方面,大家的单个核心同频性能基本是差不多的,只是APQ8064的成绩要明显比Tegra3和Exynos4412差,这可能也是由于异步开销导致的。但令人惊奇的是,Krait的Java性能要远远好于其它两款四核平台,不仅相对于前一代Scorpion有超过两倍的飞跃,甚至比所有的四核Cortex A9都高。这个结果比较出乎意料,也许是因为Krait引入的额外执行器在起作用,不论如何,这样的结果意味着在纯Java的应用中APQ8064会有很大的优势,甚至要比四核A9更好——唯一的问题是运算密集型的纯Java应用正变得越来越少。当然也不是没有,下面我们就要来看一个。
Quadrant测试向来是热门测试之一,它就是一个纯Java的测试,正好可以检测一下Krait超高Java性能的效果。这里收集的是支持多核心的V2版,由于总分受IO影响过大,我们只看CPU和内存。
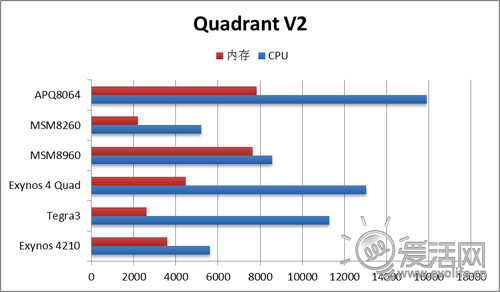
靠着超高的Java性能,APQ8064在这个测试里取得了压倒性的领先。
理论性能测试就到此为止,我们下面来看一下实际环境模拟的测试。首先采集的是Smartphone Benchmark 2012中反映CPU性能额Productivity项。
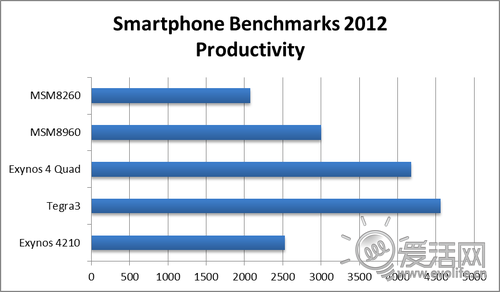
APQ8064无法找到测试成绩,不过从MSM8960来看,成绩应当与四核Cortex A9是同一水平。Tegra3在这个测试里出人意料的取得了第一名,1.5GHz的主频应当功不可没。
浏览器测试也是实际应用中很常见的项目,我们先看看Sunspider。
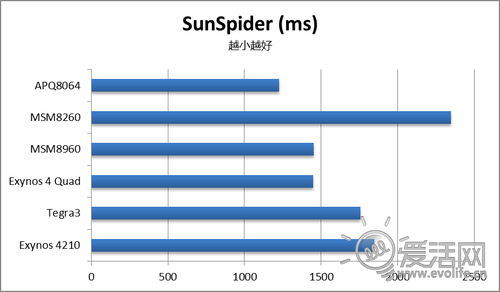
时间越短越好,不过从双核A9、双核Krait到四核A9,相对来说差距并不大。因为SunSpider测试的成绩主要受到浏览器JS引擎的影响,与系统层面的优化关系密切,因此差距不大是可以理解的。
接下来是BrowserMark:
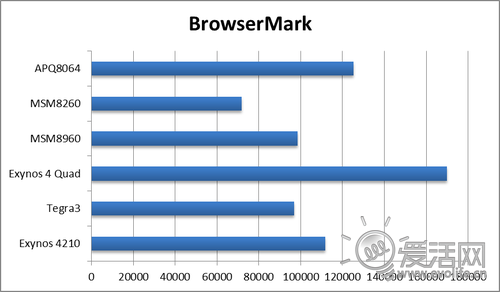
BrowserMark的结果很有趣,Exynos 4412一枝独秀,APQ8064紧随其后,除此以外,其它平台基本处于同一水平,更有趣的是不论Tegra3还是MSM8960,都不如上上代的Exynos 4210,这说明三星在软件上针对浏览器进行的单独优化效果远超其他厂家,两代亲儿子真不是白做的。
最后来看看3D性能。首先登场的自然是大名鼎鼎的GLBenchmark。2.1版本的Egypt场景使用了大量的Shader,尤其是Pixel Shader,比较看重GPU进行像素处理的能力。为了避免分辨率的影响,我们采集的是720p Offscreen的数据。
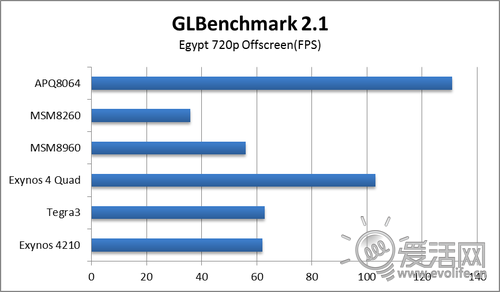
Adreno320凭借超高的硬件规模,总算在这个之前不擅长的测试里取得了第一。
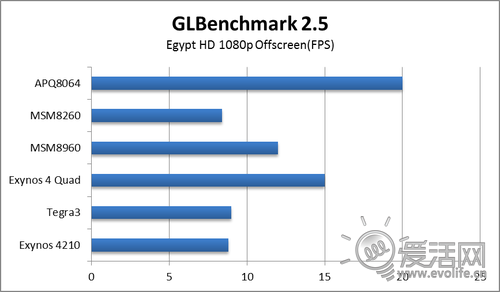
GLBenchmark2.5中,开发商重新设计了所有的模型和效果,提升极为明显,尤其是模型,细腻光滑,显然包含了数量众多的三角形。这个测试里Adreno320依然一马当先,领先第二名33%。当然,其实大家跑的成绩都不怎么样,2.1理动辄100FPS+的成绩相比,最高的APQ8064也仅仅拿到了20FPS而已,可以说都惨不忍睹,只是惨的程度而已。
安兔兔跑分的3D部分在3.0之前一直都过于简单,无法压榨优异GPU的水准。因此开发商在3.0版本引入了一个全新的3D测试场景,我们来看看这个场景的表现。
可以看到一旦复杂度提升,Mali400 MP4的性能就会大幅下跌,同时Adreno系列就会得到极大的优势。在兔子跑分V3中,配备APQ8064的手机总分远高于其他产品,几乎完全都是GPU的功劳。
最后则是最新发布的,大名鼎鼎的老牌3D测试软件3DMark。在支持了移动设备之后,大家总算有一个相对公平的比较平台,虽然对于桌面系统而言,区区DX9水平的测试早就是淘汰级别,但我们也没有更好的方式。根据之前越复杂高通越强大的规律,3DMark中高通应该也拥有很大的优势,那么实际情况是怎样呢?
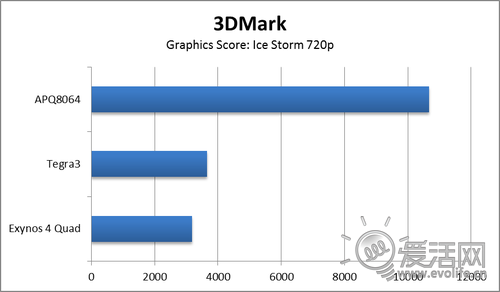
这究竟应当用“惨不忍睹”形容Exynos 4412,还是应当用“惊为天人”形容Adreno320?在3DMark的压榨下,Adreno320爆发出的性能几乎是其他四核平台的三倍,成绩已经接近2007年的低端入门级笔记本独显8400M GT。
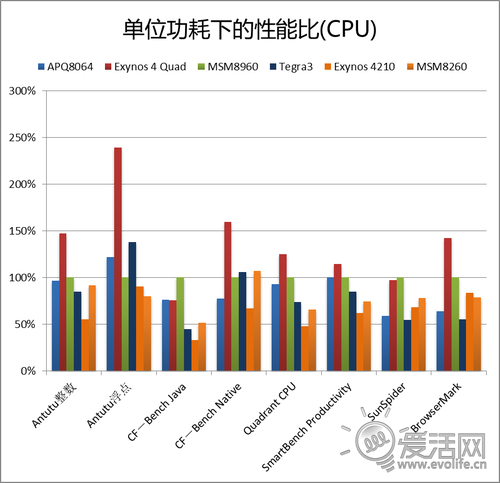
和以往测试性能不同,由于存在两种架构和两种核心数,所以这次我们尝试更加深入一点,去计算了一下三大旗舰平台在不同项目中的能耗比。除了Linpack以外,我们假定在测试中各个平台的功耗均处于最大,数据采用之前的结果。MSM8260的功耗之前并未提及,根据估测应当在650毫瓦左右。首先比较的是CPU部分的性能功耗比,这里用MSM8960的性能作为单位1。
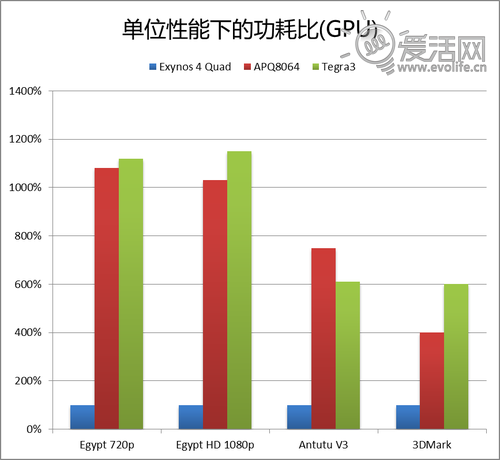
然后是GPU部分。
综合来看,Exynos 4412在上一代四核平台中能耗比是最高的,其次是MSM8960,当然这是一颗双核SoC。APQ8064在绝大多数情况下,能耗比都要比Exynos 4412低不少,而性能和对方差距也不大,这意味着两者的使用体验会比较接近,但APQ8064的发热会远大于Exynos 4412。当然厂家可以靠降低运行频率、设置更严格的温度控制阈值来控制功耗,但是这样一来性能会受到较大影响。总体来说,APQ8064有些空有一身力气却因为吃不饱而无法发挥的感觉。
GPU则对高通而言不太妙,因为差距已经大到难以理解。Tegra3由于采用的是落后的40nm工艺,能耗比不理想是可以理解的,但S4已经采用了28nm工艺(虽然工艺细节比较落后),再考虑到架构上的巨大优势,能耗比却大幅度落后。当然,在最新的测试中,Adreno320的性能有绝对的领先优势,但是这样的优势不足以抵消其超过2W的功耗。考虑到实际的应用状况,即便是遇到必须要Adreno320才可以流畅运行的游戏,Adreno320也会因为功耗过大而不具备实际的使用价值。如何解决能耗比问题,是高通的一大难点。
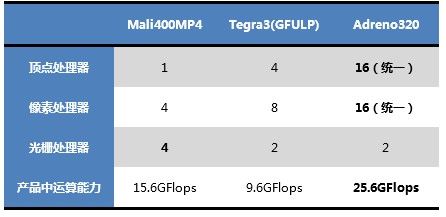
Adreno320的规模之大,为移动领域少有,根据某些渠道的消息,Adreno320占用的硅片面积大约是30mm2左右。根据路线图,年底将要上市的骁龙800会配备规模更大的Adreno330,性能将会进一步提升50%,但假如高通无法提升自己GPU的效率与能耗比,只是一味的去“堆”运算单元,即便最终可以获得强大的性能,这样的提升也会变得毫无意义,毕竟便携设备靠电池供电,不可能允许功耗无限制地增大。我们实在不敢想像在小小的手机里有着一颗功耗接近3W的GPU是怎样的感觉,唯一可以确定的是,如果真的存在这样一个GPU,在99%的时候它都不可能运行到哪怕一半的设计性能。
算过了能耗比,我们再来算算同频性能。对阵的是Cortex A9与高通新老两代核心Krait与Scorpion。
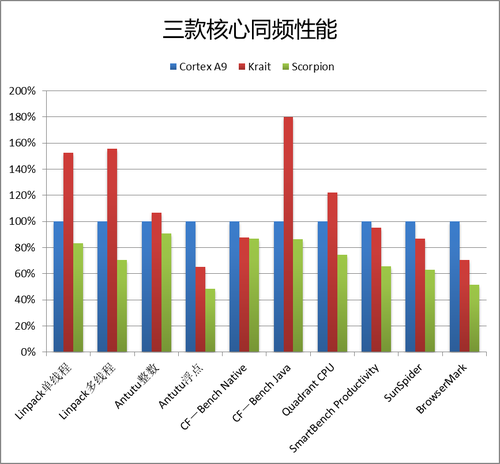
从结果可以看出,骁龙S4的Krait核心在整体的执行性能方面和Cortex A9互有胜负,并不像某些文章中所说,“远超Cortex A9,与Cortex A15同级”。领先较多的三项中,Linpack源于Krait更高版本的VFP处理器,真正有实际意义的是Java性能,这点可能会在实际使用中带来很大的区别,但异步架构又可能会对性能表现带来负面影响,所以总体而言,Krait与Cortex A9的关系更多类似于“基本持平”而并不是“远远甩开”。这个结果对高通而言可能有些沮丧,毕竟高通奉行的是两年一升级的策略,骁龙S4在自己生命周期的起始阶段无法彻底击败上一代架构的对手,随着今年正统Cortex A15产品的陆续上市,Krait核心届时也许会变得更加被动。
尾声:疯狂时代的最后演出?
通过这篇回顾,我们对于过去的2012年里大放异彩的移动四核产品算是有了一个清晰的概念,同时也对于移动产品的一些架构和技术有了一定的了解。2013年已近过半,高通已经拿出了最新的骁龙600,nVIDIA的Tegra4也蓄势待发,而三星则拿出了比较独特的八核处理器Exynos Octa。在未来的半年内,ARM阵营还会有骁龙800和Tegra4i陆续到来,Intel则会祭出全新Silvermont架构的新一代ATOM处理器以取代老迈的Saltwell——后者的架构自推出以来就几乎未曾更新,但即便如此,依然具有与Cortex A15一战的性能和Cortex A9级别的功耗。甚至一向对移动市场不太热衷的AMD,都会推出设计功耗只有3.9W,基于Jaguar核心的Temash嵌入式处理器。看起来移动领域的军备竞赛还将继续下去,至少2013年不会是终点。
但是再往后呢?攀升的性能与功耗,与发热和续航之间的矛盾正在一天天激化。从07年开始,我们经历着手机从三天一充,到一天三充,到今天甚至出现了永远都无法全速工作的“优异手机”。面对这个局面,手机厂家却依然锲而不舍地升级新硬件,消费者也还在孜孜不倦地追求最多的核心与最高的频率。这样的现象正常么?恐怕很难如此认为。这是一个疯狂的时代,毁灭可能会发生在最辉煌的一刻,而那一刻可能就在不远的将来。
那么刚刚上市与即将上市的最新一代手机究竟会发展成怎样?最新的硬件到底能给我们带来什么?这个产业的未来会是怎样?这都是我们需要思考的问题,也都是下篇将要探讨的问题。我们享受着科技进步带来的好处,也在为科技进步的副作用买单。我们推动着市场从无到有,也推动者市场从理性到疯狂进而毁灭。消费者的欲望是无限的,而消费者的理性是有限的,这才是一切问题的根源所在。移动产业何去何从?会不会像PC一样进入百足之虫死而不僵的地步?时间会告诉我们一切,我们姑且拭目以待。
下一篇Archon将会围绕着现今手机处理处理器的现状与未来进行探讨,对于这篇文章还意犹未尽的玩家可以进一步的阅读。■<
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}