

此卡一出天下反!iGame780九段全测试
首先我们来看看NVIDIA的公版产品,作为NVIDIA目前高端的型号,GTX780在硬件配备方面算是GTX TITAN的删节版,搭载了之前GK110显示核心。
GTX780采用的GK110核心拥有2304个CUDA核心,核心频率则提升到了863MHz,等效显存频率6008MHz!搭配3GB GDDR5显存,位宽384bit。下面是高端显卡的详细参数对比:
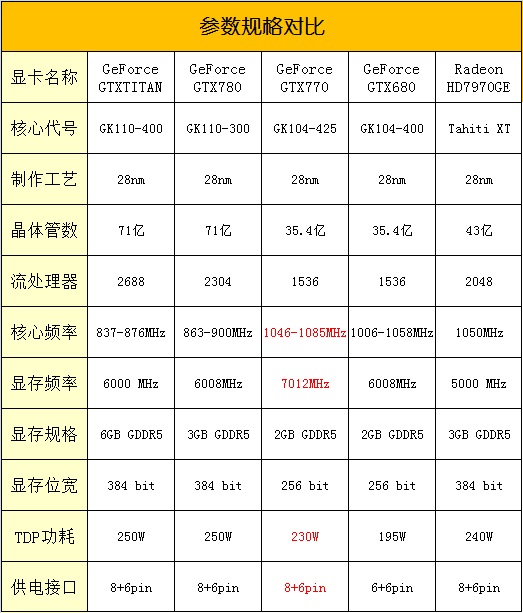
通过提供比上一代GPU更强大的处理功能以及优化和提高GPU上并行执行工作负载的新方法,Kepler GK110简化了并行程序的创建,将对会对高性能计算引起进一步改革。
Kepler GK110由71亿个晶体管组成,是有史以来架构最复杂的微处理器。GK110新加了许多注重计算性能创新功能,目的是要成为NVIDIA Tesla和HPC市场上的并行处理动力站。

Kepler GK110和GK104
Kepler GK110会提供超过每秒1万亿次双精度浮点计算的吞吐量,DGEMM效率大于80%,而之前的Fermi架构的效率是60‐65%。除了性能之外,Kepler架构在电源效率方面也有巨大的飞跃,相对于Fermi 的性能/功率比提高了3倍之多!
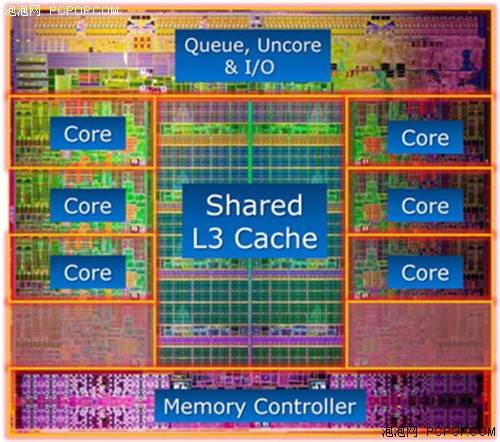
之前有人说Kepler GK110更适合超级计算和通用计算,其实这是一种误解。Kepler GK110的以下新功能不仅提高GPU的利用率,简化了并行程序设计,而且有助于GPU在各种计算环境中部署,无论是从个人电脑还是超级计算机,GK110都适用:
Dynamic Parallelism – 能够让 GPU 在无需 CPU 介入的情况下,通过专用加速硬件路径为自己创造新的工作,对结果同步,并控制这项工作的调度。这种灵活性是为了适应程序执行过程中并行的数量和形式,编程人员可以处理更多的各种并行工作,更有效的将 GPU 用为计算用途。
Hyper-Q – 允许多个CPU核同时在单一GPU上启动工作,从而大大提高了GPU 的利用率并削减了CPU空闲时间。Hyper‐Q 增加了主机和 Kepler GK110 GPU 之间的连接总数(工作队列),允许 32 个并发、硬件管理的连接(与 Fermi相比,Fermi 只允许单个连接)。
Grid Management Unit –使 Dynamic Parallelism 能够使用先进、灵活的 GRID 管理和调度控制系统。新 GK110 Grid Management Unit (GMU) 管理并按优先顺序在 GPU上执行的 Grid。GMU 可以暂停新 GRID 和等待队列的调度,并能中止 GRID,直到其能够执行时为止,这为 Dynamic Parallelism 这样的强大运行提供了灵活性。
NVIDIA GPUDirect–NVIDIA GPUDirect 能够使单个计算机内的 GPU 或位于网络内不同服务器内的 GPU 直接交换数据,无需进入CPU系统内存。GPUDirect 中的 RDMA 功能允许第三方设备,例如 SSD、NIC、和 IB 适配器,直接访问相同系统内多个 GPU 上的内存,大大降低 MPI从GPU内存发送/接收信息的延迟。还降低了系统内存带宽的要求并释放其他 CUDA 任务使用的 GPU DMA 引擎。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}