

终极指南:2013年手机CPU的现状与未来
在前文中,我们将Cortex A15批得体无完肤,也许你要有疑问:既然A15在手机上表现如此糟糕,ARM为何还要设计出这么一个核心?答案非常简单:ARM高估了半导体工艺的升级与技术进步速度,Cortex A15实际上是为20nm工艺所设计的核心。
让我们把时间倒回到2008年,TSMC在当时提出了未来5年半导体工艺路线图。如果一切都与图中的宣传精确吻合,我们在2010年就能用上28nm处理器,而在2012年,也就是去年,我们将迈入20nm时代。按照这个进度,ARM在2013年将核心进化至Cortex A15就没有任何的问题。也许ARM的初衷是借助于20nm工艺良好的性能,可以强行将Cortex A15的实际功耗压缩到0.5W以内,获得两倍于Cortex A9的能耗比提升。这点从早期TSMC和ARM的演示文档中也可以看出来。而且,A15也的确做到了绝对性能提升两倍的设计目标。

TSMC画的大饼
只不过,工艺最终没能按照ARM所设想的发展下去。28nm跳票到2012年,20nm还在遥远的2014年,而且即便成功量产,其可以得到的性能提升也极为有限,一连串的意料之外造成了Cortex A15的尴尬定位。由于工艺的失算,Cortex A9事实上失去了后继产品:Cortex A7的能耗比虽然很高,但其性能太弱,甚至不如Cortex A8;Cortex A15虽然绝对性能翻倍,但是能耗比过低,两者都无法作为Cortex A9的继任者。即便ARM通过big.LITTLE技术将二者捆绑在一起,最终实现的总体效率也只能基本上和Cortex A9打个平手,所谓的继任者更多成了纸面上而不是性能上的。
很明显,ARM被TSMC这个队友坑惨了。
有趣的是,在ARM官方面临产品线问题的时候,反而是两家ARM IP的购买商——高通和苹果——给出了比Cortex A15更好的解决方案。它们都规避了Cortex A15过于臃肿的架构设计,把注意力集中在对Cortex A9的优化和提升上。不约而同的,它们都选择了保留Cortex A9的前端、扩充Cortex A9的后端,区别是高通的着眼点在于提升指令的理论吞吐量,苹果的工作重心在提升内存表现。当然,最终的结果我们看到了,高通的方案并没有对Cortex A9形成实质上的优势,苹果的方案则很难找到对比的标准,但是至少这两家的行动方向是正确的。
因此在Cortex A15架构推出3年后的2013年,ARM痛定思痛,给出了自己针对这个问题的答案,那就是Cortex A12。

在设计规格上,ARM终于放弃了宏伟庞大的“200%性能提升”,转而只给Cortex A12定下了比Cortex A9快40%这样一个目标。这是一个相当现实的目标,尤其是考虑到Cortex A9的体系架构上的确存在一些过时的限制,让我们来看Cortex A12是怎么改的。
首先,如同其他的ARMv7架构处理器一样,Cortex A12提升了二级缓存的性能,学习前辈Cortex A15和A7的先进经验,把二级缓存整合进多核心控制器,所有核心终于可以不用再通过一条可怜的64bit总线访问自己的缓存,这将大大缓解拥堵现象。其次,Cortex A12把NEON和vFP提升到了第四版,并且和Cortex A15一样引入了内部OoO(乱序执行)设计,指令执行时效率要比A9高很多。最后,A12的外部接口也从64bit AMBA 3升级到了128bit AMBA 4,带宽提升一倍有余。

Cortex A12凭什么降低了功耗?主要是三方面,一方面是最大并发取指数从3降低到2,另一方面是大幅度缩减了指令派发队列,最后一方面是大幅度缩减了运算单元的数量。由于指令派发队列的意义在于可以支撑乱序执行,它所对应的寄存器资源和硬连接资源是非常庞大的,Cortex A15为所有8组8个运算单元设计了完整的8个独立指令队列,这无疑消耗了巨大的电力,而Cortex A12把这个数字缩减到了3。与此同时,Cortex A12的运算单元也减少到3组6个,即整数、存取和FP/NEON,每一组内包含两个运算单元,共享一个指令队列。
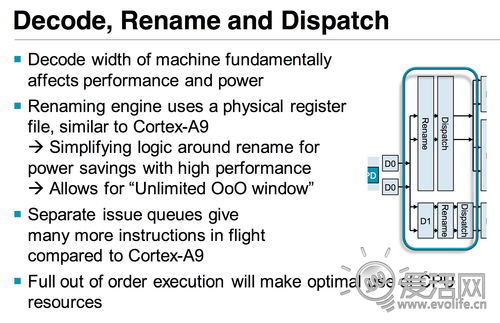
而Cortex A9就相当寒酸了,只有一个指令队列,支撑着2个整数ALU、一个存取单元和FP与NEON。仅仅依靠这样的改进,Cortex A12就几乎可以实现40%的性能提升,更不要说算上二级缓存、外部总线、以及更为前端的取指与解码部分——例如数据与指令部分重命名与分派彼此独立——的改进了。总体来说,Cortex A12是一个与Cortex A9相比性能提升40%、功耗维持不变的架构,它单凭一己之力拯救了ARM处理器摇摇欲坠的每瓦特性能,可以说是ARM的救星。A12唯一的问题只有一个——它最早也要等到2014年中才可能有产品,那时ARM很可能已经被英特尔大卸八块了。
如果我们把Cortex A12与高通Krait、苹果Swift放在一起看,可以发现一些比较有趣的地方。与ARM不同,高通Krait几乎保持了Cortex A9的前端设计,唯一的增强是取指部分的并发能力提升到3,后端则和Cortex A15一样堆积了数量巨大的执行器,具体来说是7个。这样的架构瓶颈来自于连接前端与后端的中间部分,导致Krait在实际应用中根本无法发挥其3300DMIPS——只比Cortex A15低5.7%——的理论最高性能。至于苹果Swift,由于缺乏资料与有效的对比方式,在这里并不能给出太多的分析,但是苹果的优势在于硬件与软件之间可以做到完全的匹配,因此即便苹果对Cortex A9进行如高通一般的单方面增强,也可以依靠自身的操作系统进行针对性的优化并将其发挥出来。因此在这三个介于Cortex A9和Cortex A15之间的设计中,我们认为Cortex A12是最为平衡的设计。只是——如之前所说,我们恐怕无法在2013年看到它了,甚至在2014年都有可能看不到最终产品的上市。因此Cortex A12是否真的实现了ARM的设计目标,我们也只能等到2014甚至2015年才能看到结果。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}