

是不是真的王者?创新X-FI技术再细看
前几天刊登了momo关于创新X-Fi的《聆听王者到来的声音!X-FI新技术探讨》一篇文章,受到了不少网友关注,X-Fi到底是什么?它的性能怎么样?……今天小编给大家找到一些这方面的技术资料,让大家进一步了解关于X-Fi方面的技术。
● 采样率转换简介
当我们听到声音时,我们的耳机感觉到的,是由周围物体运动引起的空气压力的连续变化。在模拟音频电子学中,空气压力的变化是由电路中电势或电压的连续变化表示的(图1)。不过,在数字音频中,此类变化存储为一组数字,每个数字都对应某一时刻的空气压力状况,而没有用连续的值。通过数学证明,我们知道了这样一个有趣的事实:一个连续的声波,完全可以用一组有限的数字,以任意的精度表现出来。

图 1 – 由声音的压力波产生的模拟信号
在模拟至数字的转换中,音频被转换为数字形式,这一过程请参考图2。为了避免产生严重的“量化失真”,必须向模拟音频信号加入少量噪音或“抖动”。加入这类噪音之后,产生的信号将按某一时间间隔进行数值测定或“采样”。若将要生成的目标音频的最高频率为某一值,采样的频率(采样率)应至少是这个值的两倍,单位为赫兹(Hz)。例如,采样率为 48,000 Hz (48 kHz),意味着每秒钟要取 48,000 个值。在相反的过程中,数字音频信号的各数值将通过“数模转换”还原为连续的信号。
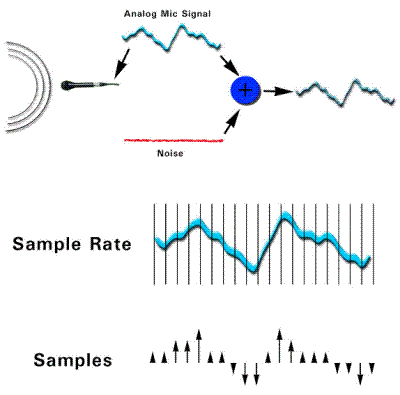
图 2 – 模数转换过程
数字音频的数学原理保证数字音频信号能精确而完整地还原连续空气压力声波的原貌。因此必须利用某种方法,只根据采样值就能计算出任意时刻的波形。这种计算方法使数字音频信号由某一采样率转换为另一采样率成为可能,这一过程就是我们所说的“采样率转换”。如图 3 所示,由原始采样率数据,可以估算新采样率下某一时刻对应的压力值,从而计算出新采样率的数据。通过复杂的数学运算,这样的转换过程可以实现任意的精度。如果运用得当,采样率转换中产生的计算性错误将远远小于原信号中的抖动噪音,听者几乎感觉不到它的存在。
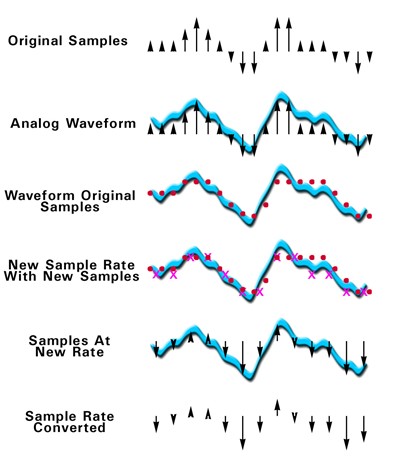
图 3 – 采样率转换
3.不同采样率之间的混音
混音是指将来自多个音源的音频结合成一个单一的声音流,这是一项基本的音频处理过程。在模拟音频领域,只要简单地将信号叠加即可。而对于数字音频,如果各信号的采样率一致,也将采用这一过程。如果各信号是在不同时刻采集的,那么就不能直接叠加信号了。
通过将某一信号转换为另一信号的采样率,可以解决这一问题。一旦样本的采样时刻统一,每个时刻的样本值就能进行简单地叠加,形成混音输出了。生成的信号可以用于更进一步的数字处理,或转换为可供聆听的模拟形式。
4.用物理方法建立多普勒平移模型
当一个发声的物体远离聆听者时,声音将随物体速度与声音速度的比率,在时间和空间上有明显的拉长效果。聆听者听到的拉长的声音,音调降低,持续时间则有所延长,如图 4 所示。当物体向聆听者移动时,将产生相反的效果。

图 4 – 多普勒效应
这一音调平移(或称多普勒平移),可以通过与改变采样率相同的算法加以模拟。如图 5 所示,将信号转换为较高的采样率,但按原速率播放计算出的样本序列,这样,声音将在时间上得到延展,其效果与多普勒平移极为相似。

图 5 – 多普勒平移的建模
如果物体移动得慢,音调只会受到轻微影响;但因为人耳对音调变化极为敏感,轻微的多普勒平移也能觉察得到。X-Fi 音频处理器含有 256 个采样率转换器,每个都有一个可调整的采样率比率,可以精确地建造出虚拟现实的模型来。
5.采样率转换:用于减少数据存储量
波表合成器通过播放真实乐器的录音,重现乐器的声音。实际上,每种乐器只储存了几段录音。如果播放的音符不在录制的音调之中,将对现有的录音进行移调处理,产生所需的音符。和多普勒平移的延展效果类似,移调与采样率转换有相同的数学原理。通过采样率转换,无需存储每个可能的音符,只要少量的录音就可以了,这大大减少了数据的存储量。由于音调可以进行微调,颤音和弯音也可应用于音乐效果渲染,使得合成的音乐具有更好的表现力。
在音频频带有限的场合,采样率转换可以有效压缩数据量。例如,对于语音录音而言,12 kHz 的采样率是完全可以接受的,与48 kHz 的采样率相比,占用的磁盘空间只有后者的四分之一。
6. 采样率转换:用于数字互联方式
要求信号在相同时刻采样,这使各个数字音频处理模块之间的互联变得十分困难,如果没有采样率转换,这几乎是不可能完成的。想像一下,有一个简单的数字音频模块(如数模转换器),工作频率为48,000 Hz。由于内部时钟的关系,这个模块要求每秒钟有正好48,000个输入样本。如果这个模块的数据源是以稍高的频率运行的,如 48,001 Hz,相差 0.002%,那么每操作一秒,提供的样本中就有一个没有在本秒内被模块所使用。这些样本逐渐累积,最后形成所谓的 over-run 错误。同理,如果数据源以稍低的采样率工作,那么模块就会缺少数据,产生 under-run 的错误。两种错误都会在音频中造成讨厌的杂音和噪音。
现代的数字录音室要求每个模块都在同一个参考采样率时钟下工作,从而解决了这个问题。这种方法被称为 “house sync” 或 “AES black,”,它使整个录音室都在同一个采样率下统一运作,无需进行采样率转换。图 6 说明如何使用 house sync 进行模块同步。
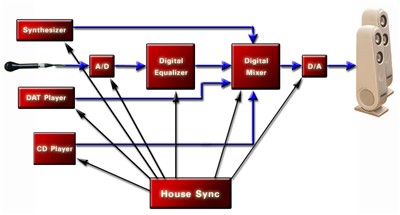
图 6 – 同步数字音频
不过,“house sync” 自身也有很多问题。除了专业录音室所用的设备之外,很少有其他设备能满足 house sync 的要求。消费者对 house sync 的需求也感到十分迷惑,其连接方法也缺乏一定的规律。并不是每个音源都能接受 house sync,而且某些材料是在其他采样率下取得的。
随着数字音频在电脑操作系统中的不断繁荣,出现了一些无法用 “house sync” 架构解决的情况。操作系统必须能与不同的音频模块相联,但由于硬件或数据的问题,这些模块是在不同的采样率下工作的。音频系统可能会被某个应用程序初始化,准备在某个采样率下工作,却被另一个使用不同采样率的应用程序先行占用。用户还可能会将某个音源同时接到两个要求使用不同采样率的目标上。最后,操作系统需要接受来自外部来源的数字音频,并将其提供给下游处理。这类互联还可能在局域网或广域网中扩展。在这些情况下,house sync 就无能为力了。
采样率转换为这些问题提供了理想的解决方案。每个数字音频输入的采样率转换器会将流入的数字音频数据转换为接收器预期的采样率。这样,安装和分布 “house sync” 就变得毫无必要了,数字音频的连接工作变得像插接线一样简单,而这正是消费者所期盼的。图 7 演示了录音室如何利用 X-Fi 采样率转换器和高度集成化的 X-Fi 音频处理器实现一个直观易懂的连接的。
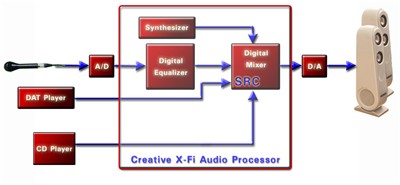
图 7 – 简化数字音频
7.关于保真度的问题
在声音转换为数字形式时,是按一定的时间间隔进行采样的。如果两个不同的模数转换器处理同一段声音,产生的数字序列可能会不同,但是两者都准确地表现了原始 信号。同样,采样率转换也能理想地生成样本的新序列,从数学的角度来说,这一新序列与原始信号是等同的。如果有误差,应归因于执行的数学操作本身的精度有限。重点在于,要保持由样本集表示的连续信号的保真度,将数学运算带来的误差降到远低于信号固有的模拟噪声、可以忽略不计的程度。
在采样率转换过程中,有两类信号衰减现象。线性误差出现在那种并非完全没有起伏、但出现的是“波纹”的频率响应之中。这种误差是由于采样率转换器原有的滤波器所致。如果将波纹放大到近 1dB,它就变得清晰可闻了。信号处理的链条式流程中,会用到多个采样率转换器,造成波纹效应的累积,每个转换阶段都会产生一个极小的波纹。
非线性误差的产生与原有滤波器的规格和实现这些滤波器时的计算误差有关。非线性处理误差最常见的放大倍数测量方法是“THD + Noise” 总协波失真。这一测量方法将信号中所有的失真组件和所有随机噪声叠加求和,与预期信号(通常是正弦波)的级别进行比较。虽然这种测量方法简便易行,但还不能完全准确地衡量我们感知的信号质量,因为每种不同的失真组件,在听觉范围内的变化都很大。
THD+N 总协波失真测量常被应用于测试在整个数字处理链式流程中的全级别信号。例如,一般的 CD 播放机的 THD+N 为 0.002% (-90 dB),也就是说,一个全级别的 997Hz 的正弦波,产生的失真信号级别为该数值。需要注意的,在这种情况下,失真的倍数与信号强度无关。因此,本例中一个–60dB 的正弦波,THD+N 的值可能为 2% (-30dB),是很容易听到的。
与此不同的是,采样率转换器的 THD+N 记录了信号的强度,因此,–60dB 的信号产生的失真比全级别信号要小 60dB。另外,当多个采样率转换器被插入一个数字音频处理时,每个转换器产生的失真会以一种相当有益的方式组合在一起,因为各个失真元件并非“相关”。简单地说,N 次转换完成后,产生的失真仅是按 N 的平方根增加。例如,如果处理链中有 100 个采样率转换器,噪声仅是单个转换器的10(100 的平方根)倍。只比一个转换器的情况高 20 dB。这意味着,即使使用了多个转换器,其技术指标依然十分优秀。
如果采样率转换器只是对采样率稍作改动(例如,转换器只是纠正了采样率的某些微小的不精确之处),产生的失真将与原有信号的频率十分接近。此时,失真几乎是听不到的,因为它被与之接近的信号频率掩盖住了。
8.传统的采样率转换器
传统的采样率转换器算法采用多相有限脉冲响应滤波器,简称 FIR。这种滤波器根据原始样本的产品总数计算新的样本。为了达到优秀的技术指标,需要进行大量的运算。FIR 滤波器的“order”是指每个输出样本的计算产品数,这与转换器的质量有关。
正如上面解释的那样,采样率转换器在已录制的样本之外的各点计算原始的连续音频信号值。最简单的算法是采用“连线游戏”,其中的连续信号是根据线段予以估算的。这种方法被称为“线性插值”,对应 order 2 的 FIR 滤波器。虽然这易于理解,但是效果很差。
传统的采样率转换器技术,包括 order 64 的 FIR 滤波器,每个转换器每秒需要进行约 3,000 万次数学运算,这还不能满足 X-Fi 所设定的品质目标要求。
X-Fi 有 256 个采样率转换器。在某些应用,如 3D 音频和音乐合成中,会对大量的采样率转换器输出进行混音。为了在模数转换过程中使音频质量达到我们的目标,每个转换器的 THD+N 性能必须十分优秀。X-Fi 音频处理器还支持任意的信号图,允许音频进行多次采样率转换。为了能够对这些类型的信号图提供透明化的支持,X-Fi 采样率转换器只能有极低的波纹效果。THD+N 和波纹效果的品质目标,以及 X-Fi 采样率转换器的数量要求,使传统的采样率转换器架构在计算方面变得十分昂贵。
9. X-Fi 混合采样率转换器架构
X-Fi 采样率转换器采用独特的三阶段架构,如图 8 所示。第一阶段采用了一种十分有效的计算方法,将原有的采样率加倍。第二阶段使用一个多相 FIR 滤波器,产生一个采样率,该采样率是最终的目标输出采样率的四倍。第三阶段也就是最后一个阶段,以四为除数,得到所需的采样率。第一个阶段的计算过程具有极高的效率。如果您对采样率转换器的技术有所了解,您会发现,最后一个阶段是以最小的计算成本,通过提供一个 steep anti-Imagine barrier 扩展转换比率的范围的。
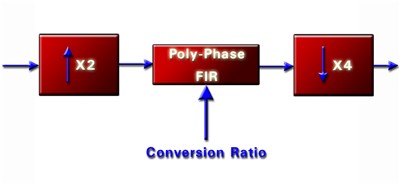
图 8
图9用实例说明了这一架构是如何动作的。在本例中,44.1 kHz 的采样率被转换至 48 kHz。第一阶段将原始采样率加倍,提供采样率为 88.2 kHz 的新信号。第二阶段中,多相 FIR 滤波器在两倍于 48/44.1 的采样率比率下操作,将此信号转换为 192 kHz 的采样率。最后一个阶段将采样率降低为所需的输出采样率,即 48 kHz。
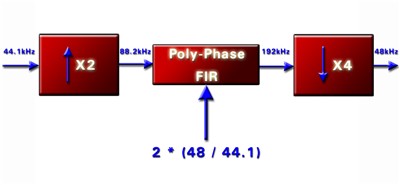
图 9
10. X-Fi 混合采样率转换器的品质
X-Fi 采样率转换器的目标,是使用多个串联或并联的采样率转换器,提供只受到模数转换器固有噪声限制的音频品质。X-Fi 在将 44.1 kHz 转换为 48 kHz 时的 THD+N 性能如图 10 所示。任一频率的全级别正弦波产生的的失真都低于 –136dB(在Audio Precision distortion analyzer音频精度失真分析器中测量)。在本例中,通频带波纹为 ±0.00025dB。
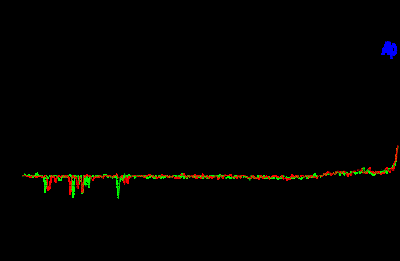
图 10
假设,在 6dB 的信号容度下,连续通过 32 个转换阶段,X-Fi 转换器产生的 THD+N 值为 –124dB,远远低于现有最好的数模转换器的最低噪音值, 积累的波纹效果低于 ±0.01dB。这样的情况下大多数失真都被原始信号遮掩住了,这使这些技术规格更具有吸引力。
X-Fi 采样率转换器支持从零到三个八度在内的广阔的移调范围。X-Fi 架构灵活的路由功能,意味着音频可以通过两个串联的采样率转换器,扩展到更广阔的移调范围。
即使有了 X-Fi 混合 SRC 架构,这样的品质也不是轻易就能达到的。X-Fi 中,针对特殊目的的采样率转换器引擎,每秒钟能执行 70 亿次以上的算术运算。信号数据路径经过细心的流水线处理,乘法器和加法器的位宽也得到了优化,以保证实现最高的信号品质。
11.总结
X-Fi 采样率转换器拥有一个不同寻常的架构,能够提供非常好的音频保真度,营造出最精确的 3D 虚拟环境和毫无瑕疵的合成音乐。它拥有极低的波纹效果值和出色的 THD+N 性能,从而消除了采样率合成中种种令人头疼的问题,使这一过程就像使用插接线一样地简单。X-Fi 音频处理器将诸如“要不惜一切代价避免进行采样率转换”“要尽量进行位精确录音”等等旧观念一扫而光。X-Fi 音频处理器的使用直观而充满创意,你可以充分利用采样率转换的种种好处,享受非常好的音频乐趣!<
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}