

火力全开超TITAN!GTX780GHz首发评测
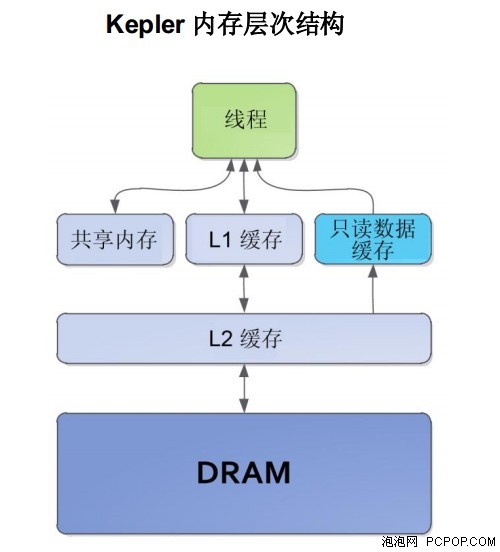
Kepler的内存层次结构与Fermi类似。Kepler架构支持统一内存加载和存储的请求路径,每个SMX 多处理器有一个L1缓存。Kepler GK110 还使编译器指示为只读数据增设一个新的缓存,如下所述。
64KB可配置共享内存和L1缓存
在 Kepler GK110 架构(如在上一代 Fermi 架构)中,每个 SMX 有 64 KB 的片上存储器,可配置为 48 KB 的 共享存储器和 16 KB 的 L1 缓存,或配置为 16 KB 的共享存储器和 48 KB 的 L1 缓存。Kepler 目前在配置共享存储器的分配和 L1 缓存方面的灵活性更大,允许共享存储器和 L1 缓存之间以 32KB/32KB 划分。为了支持 SMX 单元增加的吞吐量,用于 64 位或更大负载运算的共享存储器带宽相对 Fermi SM 也增加一倍,到每主频 256B。
48KB只读‐数据缓存
除 L1 缓存之外,Kepler 为只读数据引入 48 KB 缓存为了函数的持续时间。在 Fermi 时代,该缓存只能由纹理单元访问。专家程序员通常发现它的优势是通过将数据映射为纹理来加载数据,但这种方法有很多局限性。
在 Kepler 中,除了大大提高了该缓存的容量之外,还伴随着纹理功力的提高,我们决定让缓存为一般负载运算直接访问 SM 。使用只读的路径好处极大,因为它使负载和工作组的影响远离共享/L1缓存路径。此外,其他情况下,只读数据缓存更高的标签带宽支持全速非对齐内存访问模式。
该路径的使用是由编译器自动管理(通过参数 C99 访问任何变量或称为常量的数据结构)。标准关键字 “const_restrict” 将被编译器标记以通过只读数据缓存加载。
改进的L2缓存
Kepler GK110 GPU 具有 1536KB 的专用 L2 缓存内存,是 Fermi 架构中 L2 的 2 倍。L2 缓存是SMX 单元之间主要数据统一点,处理所有加载、存储和纹理请求并提供跨 GPU 之间有效、高速的数据共享。Kepler 上的 L2 缓存提供的每时钟带宽是 Fermi 中的 2 倍。之前不知道数据地址的算法,如物理求解器、光线追踪以及稀疏矩阵乘法,从高速缓存层次结构中获益匪浅。需要多个SM读取相同数据过滤和卷积内核也从中受益。
内存保护支持
与 Fermi 相同,Kepler的注册文件、共享内存、L1 缓存、L2 缓存和 DRAM 内存受单错纠正双错检测 (SECDED) ECC 代码保护。此外,只读的数据缓存‐通过奇偶校验支持单错纠正,在奇偶校验错误的情况下,缓存单元自动使失效,迫使从 L2 读取正确的数据。
ECC 校验位从 DRAM 获取必定消耗一定量的带宽,这会导致启用 ECC和停用 ECC的运算之间的差异,尤其对于内存带宽敏感的应用程序。基于 Fermi 的经验,Kepler GK110 对 ECC 校验位获取处理进行了几项优化。结果,经内部的计算应用测试套件测量,开启和关闭 ECC 的性能三角洲已经平均降低 66%。
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}

