

火力全开超TITAN!GTX780GHz首发评测
原来的一个困难是,GPU始终要优化调度来自多个数据流的工作负载。Fermi 结构支持从单独数据流的16路并发内核启动,但最终数据流都复用相同的硬件工作队列。这允许虚假的数据流内依赖,要求在单独数据流内的其他内核可以执行之前就完成一个数据流内依靠的内核。虽然在某种程度上这可以通过使用广度优先启动顺序缓解,但是随着程序的复杂性的增加,这可以成为越来越难以有效地管理。
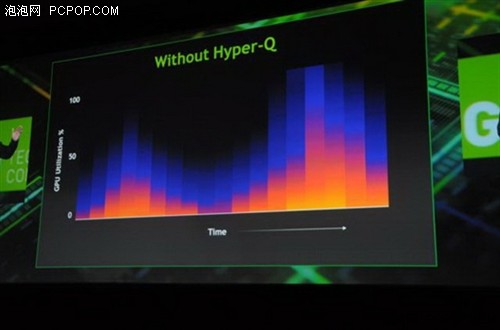
Kepler GK110 使用新 Hyper‐Q 特征改进了这一功能。Hyper‐Q 允许 32 个并发,硬件管理的连接( 对比 Fermi 的单一连接),增加了主机和 GPU 中 CUDA Work Distributor (CWD)逻辑之间的连接总数(工作队列)。Hyper‐Q 是一种灵活的解决方案,允许来自多个 CUDA 流、多个消息传递接口(MPI)进程,甚至是进程内多个线程的单独连接。以前遇到跨任务虚假串行化任务的应用程序,限制了 GPU 的利用率,而现在无需改变任何现有代码,性能就能得到 32 倍的大幅度提升。
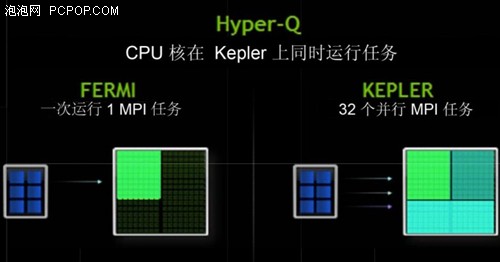
Hyper‐Q 允许CPU和GPU之间更多的并发连接
每个 CUDA 流在其自己硬件工作队列管理,优化流间的依赖关系,一个流中的运算将不再阻止其他流,使得流能够同时执行,无需特别定制的启动顺序,消除了可能的虚假依赖。Hyper‐Q 在基于 MPI 的并行计算机系统中使用会有明显的优势。通常在多核 CPU 系统上运行时创建传统基于 MPI‐的算法,分配给每个 MPI 进程的工作量会相应地调整。这可能会导致单个MPI 进程没有足够的工作完全占据 GPU。虽然一直以来多个 MPI 进程都可以共享 GPU,但是这些进程可能会成为虚假依赖的瓶颈。Hyper‐Q 避免了这些虚假的依赖,大大提高了 MPI 进程间共享 GPU 的效率。
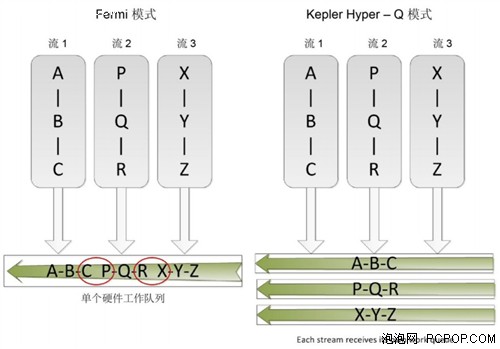
Hyper‐Q 与 CUDA 流一起工作:左侧显示 Fermi 模式,仅 (C,P) 和 (R,X) 可以同时运行,因为单个硬件工作队列导致的流内依赖。Kepler Hyper‐Q 模式允许所有流使用单独的工作队列同时运行。
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}

