

完美DX10!ATI新王者HD2900XT权威评测
第四章\\第八节 Shader Export & Render Back-Ends(像素输出部分)
ATI的Render Back End(后期渲染)其实就相当于NVIDIA的ROP(Raster Operation Processor光栅操作处理器),其主要作用就是像素输出,但是它还担负了Z(深度)操作、抗锯齿取样等繁重任务,在DX10中被称作“Output Merger”。
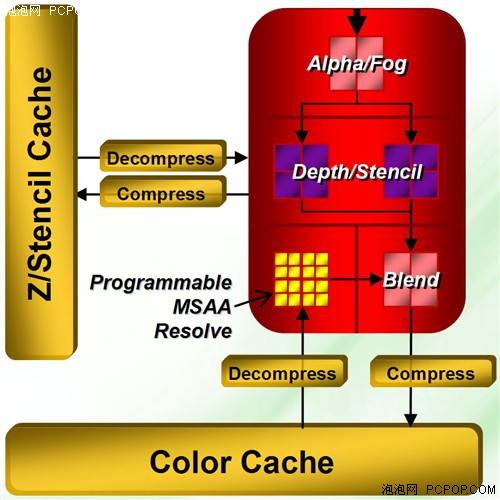
 R600拥有4个后期输出模块
R600拥有4个后期输出模块
与G80相同,R600也提供了最大8个MRT(Multiple Render Target),直接支持8xMSAA。其最大的特点就是可编程AA模式,可以在2/4/8xMSAA的基础上衍生出N多种高效率的CFAA(最大24x),这部分内容将在后文章详细介绍。
R600可以在一个时钟周期内采样32个Z/模版,速度翻倍,而且深度/模版是分开处理的,执行效率更高。
深度/模版压缩率提高至16:1,到达了X1000的两倍,在8xMSAA模式下更是可以达到128:1的超高压缩率。
第四章\\第九节 独立的专属缓存
GPU所要处理的几乎所有数据和指令都是被存储在海量的显存之中,虽然显存速度逐年增长、512Bit总线将带宽翻了两倍、环形总线也有效的降低了延迟,但始终不可能与GPU同步运行,因此片内缓存依然是必备之物。其设计理念与CPU的L1/L2、数据/指令缓存完全相同。
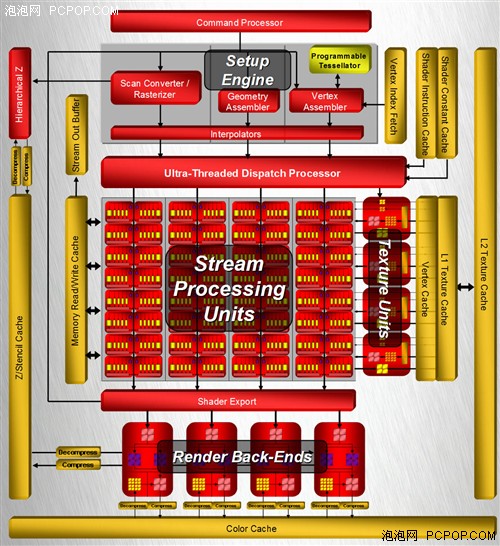
从R600的架构图中可以看到,几乎每一个模块都配备了大量的缓存,这些缓存各自独立、各司其职,如图深黄色部分,接下来简要介绍各部分缓存的用途及相关技术:

超线程分配处理器配备了独立的着色常数缓存和指令缓存,使得代码长度几乎可以不受限制,而且可以在队列中存放更多条优先级较低的指令。
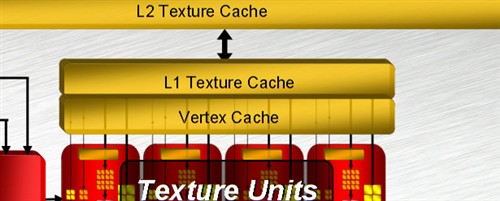
纹理缓存(Texture Cache)部分,R600的L1和L2分别是一个整体(而G80被分割为8块,因为有8个Shader阵列,加起来是384KB),四个纹理单元共享256KB的容量。RV630的L2减半,RV610则没有L2。
顶点缓存(Vertex Cache)容量达到R580的8倍!
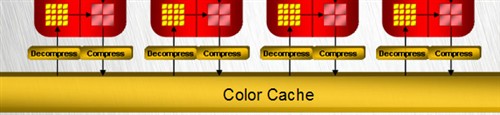
颜色缓存(Color Cache)其中内容可以是颜色索引或者RGBA数据,很多时候拥有左右两个甚至上下左右四个缓存,用以实现立体图。

模板缓存(Stencil Cache)用以保持屏幕上某些位置图形不变,而其他部分重绘。例如大家熟悉的开飞机和赛车的游戏的驾驶舱视角,只有挡风外面的景物变化,舱内仪表等等并不变化。
除此之外,R600的Z缓存和模板缓存压缩比率提高到16:1(达到X1000的2倍),打开8xMSAA时压缩率高达128:1!R600中模板缓存和深度缓存依然是一个整体,但两者是单独压缩独立存取的。压缩信息可以存放在片内缓存或者是显存当中,这使得模板和深度压缩几乎可以被无限制的使用。

显存读写缓存(Memory Read/Write Cache),与CPU相同,GPU并不能直接访问庞大的外部显存,也是通过一块映射缓存充当内存的镜像后访问。
数据流输出缓冲(Stream Out Buffer),以往几何体必须在写入显存之前是被光栅化之后送入Pixel Shader。而Stream Out技术允许数据从VS或PS中直接传入Buffer或者显存,这种缓存可以被传回Shader重新处理,允许GPU重复利用已有的结果从而减少重复计算。DX10新纳入的几何着色器通过顶点信息批量处理几何图形,快速生成大量多变形,在此过程中会生成大量重复性数据,此时Stream Out Buffer就能起到事倍功半的作用,大幅提高新图形算法及物理运算的效率!
如此众多的片内缓存有效的提高了芯片个部分模块的运行效率,但同时也让R600的晶体管规模膨胀。

关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}