

深度解读DX10架构!Shader激超2200MHz
回望过去DX7时代3DFX的陨落;DX8时代NV与ATI的双雄争霸;DX9时代NV从NV30的绝对劣势到NV40的反击确立性能王者地位,作为业界最广泛被使用的图形接口,DirectX的每一次升级都给业界带来近乎翻天覆地的变化,当然到了DX10时代来临的时候同样如此。机会总是稍瞬即逝的,如何能在DirectX更新换代时抓住先机是显卡芯片厂商每一代显示芯片的兵家必争之地,G80的抢先发布无疑是给AMD R600给了沉重的压力。
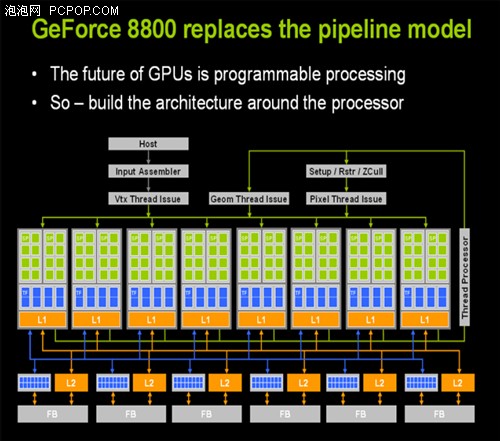
从G80开始NV为新一代的显示芯片带入了统一着色器架构(Unified Pipeline and Shader Design),简单地说就是不同于从前那样分开Pixel Shader、Vertex Shader等等不同类型的Shader单元去处理数据,而是以一个被称为GigaThread的线程处理器根据不同的工作负荷分配流处理器完成各种指令。这样设计的好处是,加上标量架构设计的配合,即便是面对各种各样的图形接口,显示芯片都能够以最高的工作效率运作,而不会出现Pixel或者Vertex上的自愿浪费,影响效能。
以G80为例,128个标量化流处理器扮演着顶点着色器、几何着色器、像素着色器等等的角色。与以往不同,当Pixel、Vertex等等的渲染工作就交由标量化流处理器完成,那么大部分渲染工作的完成效能就涉及到流处理器频率的问题。以往我们惯用提升显卡效能的手段无非是提高显卡核心频率或者显存频率,再要提高效能充其量就是在显存的时序上动些手脚,但在承继了G80统一着色器架构的显卡上,除了核心频率以及显存频率外影响效能的还有标量流处理器Shader的频率,而这个Shader的频率在不少玩家口中流传着一种说法就是Shader频率决定了效能的高低,而核心频率的作用被Shader频率的作用淡化。
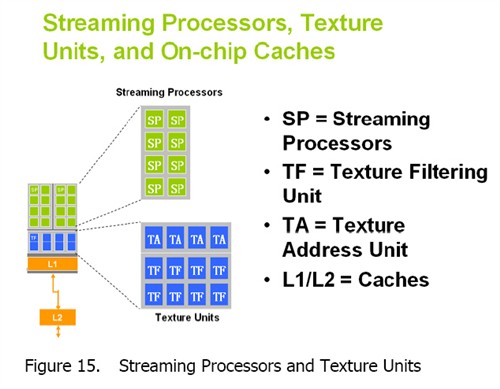
而事实上我们可以从NV官方放出的架构图上见到,无论是Texture Flitering(TF)还是Texture Addressing(TA)都是和Streaming Processors分离的独立单元,此外NV的官方文档也提及了很重要的一点:CoreClock是控制着包括dispatch、textuneunit和ROP unit的效能,也就是说单单从理论上看,在显卡处理运作的时候,实际上Shader频率提升后,如果CoreClock维持,当Shader处理能力很强,但Textuneunit或者ROP一旦出现瓶颈,那么显卡性能还是不会有大幅提升。
值得一提的是,在高端的G80身上被验证是成功的统一着色器架构被NVIDIA带进Geforce 8系列中低端显卡中。而事实上作为G80精简3/4、7/8后的G84/G86并没有表现出与G80性能精简后同比列后相似的性能,实际上是流处理器优化的问题。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}