

GPU挑战CPU地位!详解CUDA+OpenCL威力
较多核CPU确实很诱人,但只能存在于实验室中,距离我们似乎非常遥远。由于较多核CPU的架构与目前的双核/四核CPU有很大的不同,因此大家不必拘泥于传统处理器的概念。其实较多核处理器“远在天边、近在眼前”——高配置电脑当中肯定拥有一颗GPU(显卡),9800GTX+是128核心、GTX280则拥有240颗核心,GPU的每一个流处理器就是一颗核心。
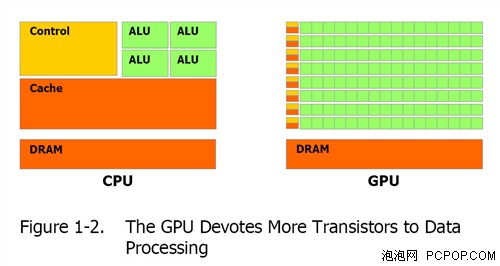
目前X86架构的处理器经过30年的发展,指令集、平台、系统和软件支持已经接近完美,因此使用CPU处理数据是天经地义的。GPU虽然也诞生了近20年,但它从来都只能渲染图形,想要让他进入全新并行计算领域,无论硬件架构还是软件平台都需要作相应的调整。
● GPU在硬件架构方面的进步
传统GPU的核心组成部分是Shader(着色器),分为Pixel Shader(像素单元)和Vertex Shader(顶点单元),每一个Shader是一个4D或5D的矢量运算单元,之所以设计成这样是因为在图形处理中,最常见的像素都是由RGB(红黄蓝)三种颜色构成的,加上它们共有的信息说明(Alpha),总共是4个通道。而顶点数据一般也是由XYZW四个坐标构成,这样也是4个通道。在3D图形进行渲染时,其实就是改变RGBA四个通道或者XYZW四个坐标的数值。为了一次性处理1个完整的像素渲染或几何转换,GPU的像素着色单元和顶点着色单元从一开始就被设计成为同时具备4次运算能力的运算器(ALU)。
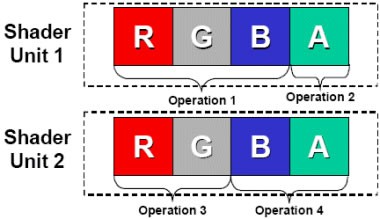
传统Shader结构的GPU只适合做图形渲染
这样的4D矢量运算单元在渲染3D图形时会有很高的效率,但在处理复杂指令时的效率会大打折扣,比如DX10新引入的几何着色、物理加速等,尤其在面对非图形渲染指令时优势全无。
NVIDIA的科学家对图形指令结构进行了深入研究,它们发现标量数据流所占比例正在逐年提升,如果渲染单元还是坚持SIMD(单指令多数据流)设计会让效率下降。为此NVIDIA在G80中做出大胆变革:流处理器不再针对矢量设计,而是统统改成了标量ALU单元。用通俗的话说就是:Shader单元内部ALU完全打散,设计成为各自独立的流处理器,并分配相应的指令发射端和控制单元,这样的架构在面对任何形式的指令(包括组合指令)时都能保证最高的执行效率,这也就是NVIDIA在DX10时代游戏性能大幅领先于竞争对手的根本原因!
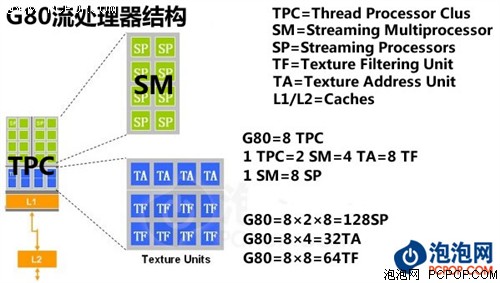
随着图形画面越来越复杂,1D、2D、3D指令所占比例正在逐年增多,而G80在遇到这种指令时可说是如鱼得水,与普通4D指令一样不会有任何效能损失,指令转换效率高并且对指令的适应性非常好,这样G80就将GPU Shader执行效率提升到了新的境界!
这种富有弹性的架构不仅拥有很强的图形渲染能力,而且能够处理以往不敢奢想的非图形运算指令,理论上来讲只要是浮点运算指令都可以交给GPU来处理。而在以往,程序员必须针对GPU的架构特点,对指令重新分类打包并模拟图形指令交给GPU处理器,工作量可想而知,效率也极为低下。
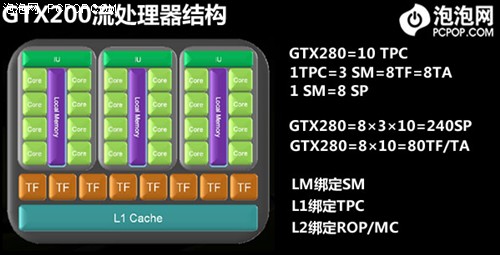
G80的架构无论对于图形渲染还是并行计算都是革命性的,但NVIDIA并没有满足于此,为了进一步提高GPU的并行计算效能,把GPU改造成为一颗真正的通用处理器,NVIDIA在GTX200核心大规模扩充流处理器数量的同时,也对内核架构进行了诸多优化与改进,使之更适合做超大规模并行数据处理。

GTX200核心的主要改进有:
- 每个SM(8个流处理器为一簇)可执行线程从768提升至1024条;
- 每个SM的指令寄存器容量翻倍,从16K提升至32K;
- 将双指令执行(Dual-Issue)效率提升至94%,接近于理论值;
- 512Bit显存控制器,4GB显存容量支持,防止指令排队溢出;
- 支持双精度64Bit浮点运算,55nm版GTX200的双精度运算能力提高4倍!
以上所有的改进(显存位宽除外)并不会让GTX200核心的图形渲染能力得到提高,但却能够大幅提升GPU在进行海量数据处理时的效率。由此我们可以看出NVIDIA的野心与实力——G80与GTX200已经不再是一颗图形处理器,而是较多核通用处理器!而NVIDIA这种图形架构与并行计算架构合二为一的架构就被称为CUDA。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}